Product Release Notes - June 2025 Edition
Cloudera Octopai Data Lineage announces the release of the Spark Connector for automated data lineage extraction. The connector captures runtime lineage for Spark batch jobs on Apache Spark 2.x and 3.x clusters without requiring access to customer source code or development environments, enabling secure and efficient metadata extraction.
Spark Connector
Overview
Cloudera Octopai Data Lineage announces the release of the Spark Connector for automated data lineage extraction. The connector captures runtime lineage for Spark batch jobs on Apache Spark 2.x and 3.x clusters without requiring access to customer source code or development environments, enabling secure and efficient metadata extraction.
The connector captures runtime lineage for Spark batch jobs without requiring access to customer source code or development environments, enabling secure and efficient metadata extraction.
Key capabilities
-
Execution-based lineage capture: Captures lineage by intercepting Spark SQL execution plans at runtime, ensuring lineage reflects the actual executed data flows.
-
Support for Spark 2.x and 3.x: Fully compatible with Apache Spark versions 2.x and 3.x environments.
-
Persistent storage operations: Captures data reads and writes to persistent storage systems (tables, file systems, object stores). Only persistent operations are included; in-memory-only transformations are not captured.
-
Column-level lineage: Tracks how individual columns are transformed and propagated through the job, providing detailed flow information.
-
Language agnostic and secure: Supports Spark jobs written in Python, Scala, Java, and R. The connector extracts lineage at runtime without static code parsing, reducing setup time and minimizing security exposure.
-
User-defined function awareness: Identifies when UDFs are used in jobs; internal UDF logic is not parsed or exposed.
-
Application name capture: Captures Spark application names when explicitly set in the Spark job code, aiding in operational tracking.
-
Batch job support: Supports lineage capture for Spark batch jobs. Streaming jobs (Spark Structured Streaming, Kafka) are not supported in this release.
-
Authentication: Supports Basic Authentication (username/password) for communication with the Spline server. Kerberos authentication and delegation tokens are not supported.
Limitations
-
Captures lineage only for successfully completed jobs.
-
In-memory transformations that are not persisted to storage are not captured.
-
Internal UDF logic is not parsed.
-
Streaming pipelines (Kafka, Structured Streaming) are not captured.
-
Kerberos authentication is not supported; only Basic Authentication is available.
Deployment notes
For installation guidance, see the Configuring Octopai Connector for Apache Spark.
-
Requires Spark cluster configuration with Spline agent properties set in
spark-defaults.conf. -
Requires a writable HDFS or object storage location for lineage output.
-
Spark containers must be deployed and managed within the customer environment.
Compatibility
-
Supports Apache Spark versions 2.x and 3.x.
-
Compatible with jobs written in Python, Scala, Java, and R.
Apache NiFi Connector: Technical Preview / Early Availability
Overview
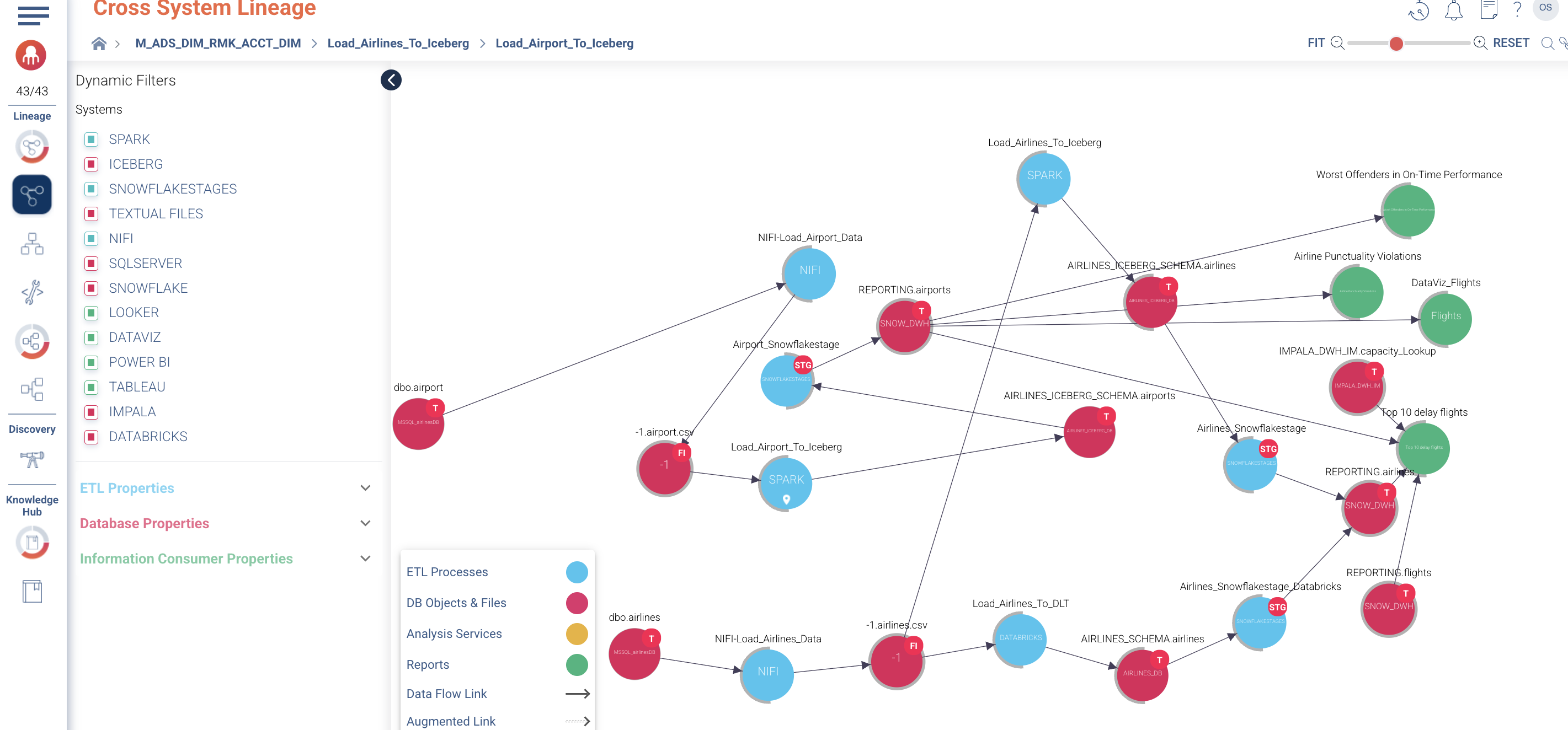
Cloudera Octopai is introducing an early availability release of its Apache NiFi connector specifically tailored for Cloudera environments. This initial version focuses on enabling visibility into Cross-System Lineage, with broader functionality under development for future releases.
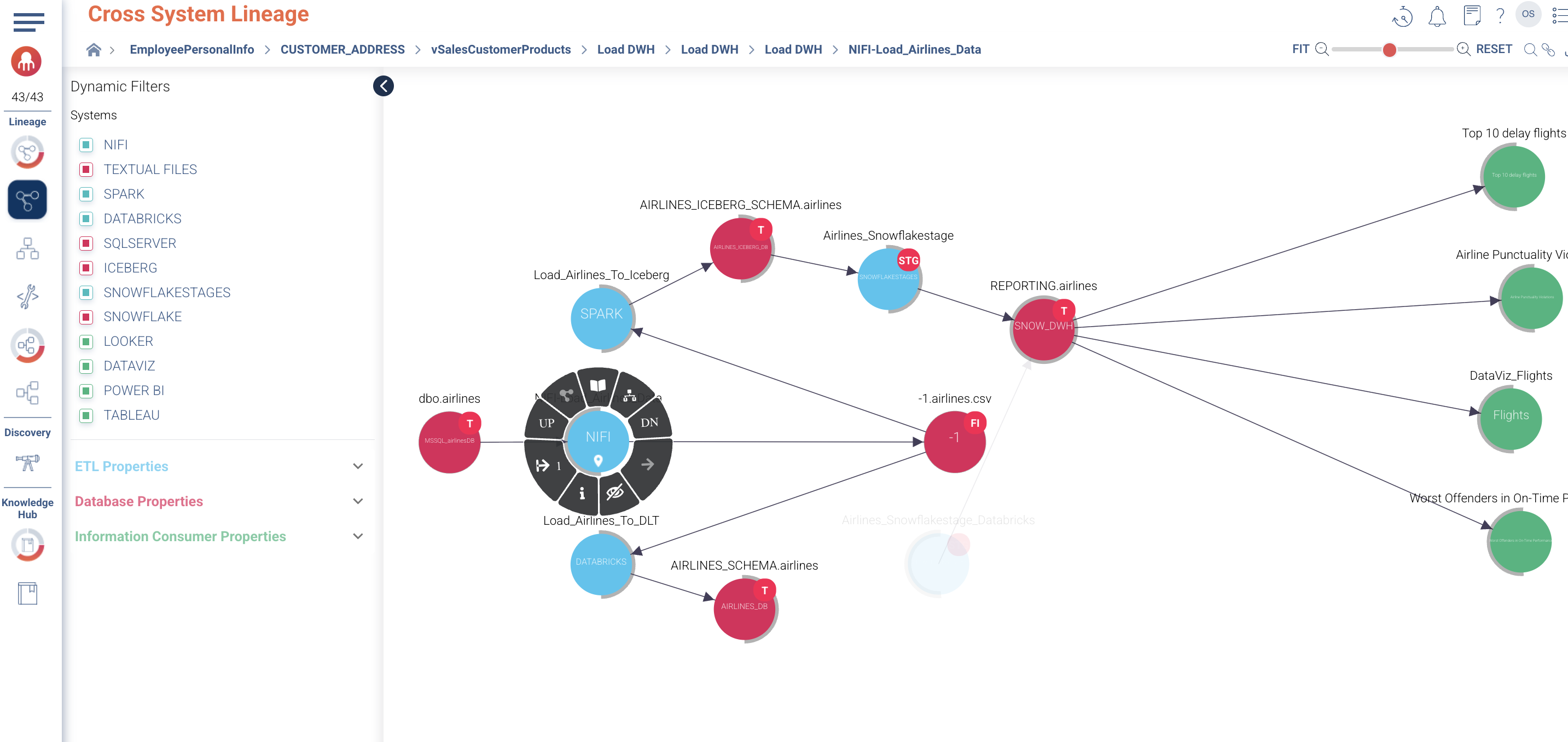
Why Apache NiFi data lineage matters
Apache NiFi is a core orchestration platform within modern data ecosystems, responsible for moving and transforming data between systems. Capturing lineage from NiFi is critical because:
-
Visibility into data movement: NiFi connects diverse sources and targets—from files to databases to cloud services—making flow visibility vital for governance, compliance, and impact analysis.
-
Cross-system complexity: Enterprises rely on NiFi to bridge legacy, hybrid, and cloud environments. Cross-System Lineage enables teams to track data across technologies and platforms.
-
Operational insight: Identifying dependencies between systems helps troubleshoot issues, optimize pipelines, and reduce risk during changes or migrations.
Even in this early phase, Cross-System Lineage provides immediate value by exposing how datasets traverse different environments, ensuring data trust and streamlined operations.
Why these processors first
The initial set of supported processors was carefully selected based on the following criteria:
-
High usage frequency: Processors such as GetFile, PutS3Object, ExecuteSQL, and FetchHDFS cover common ingestion, transformation, and delivery patterns.
-
Critical integration points: These processors interact with key enterprise systems—object stores, databases, filesystems, and messaging platforms—vital for building an end-to-end lineage view.
-
Clear source-to-target semantics: Well-defined metadata makes these processors ideal for establishing reliable lineage in complex flow environments.
This phased approach delivers immediate, high-value coverage while laying the groundwork for more advanced lineage capabilities.
What's supported in this release
For additional details, see the Octopai by Cloudera Connector for Apache NiFi: Tech Preview / Early Availability.
Cross-system lineage (table level)
-
Visualization of Cross-System Lineage at the table level.
-
Initial support includes lineage derived from the following NiFi processors:
-
GetFile
-
PutFile
-
PutS3Object
-
ListS3
-
FetchS3Object
-
PutParquet
-
InvokeHTTP
-
GenerateTableFetch
-
ExecuteSQL
-
FetchHDFS
-
EvaluateJsonPath
-
QueryRecord
-
PutHDFS
-
PutDatabaseRecord
-
PublishKafka / ConsumeKafka
-
General processor handling
-
Processors not explicitly listed above display with basic logic (ObjectData=0).
-
Parameter context support is included.
Processor groups visibility
-
Processor Groups that contain only other Processor Groups and no Processors or Ports do not appear on the Cross-System Lineage dashboard.
-
Only Processor Groups that directly read from or write to Processors, Input Ports, or Output Ports are included in the dashboard view.
Not supported in this release
-
Detailed column-level lineage (planned for a future phase).
-
Nested Processor Groups and wrappers for complex flows.
-
Dynamic parameters within table or query names, for example
${db.table.fullname}) -
Site-to-Site connections.
-
Kerberos authentication (tested only with username/password).
Installation and setup
This tech preview version does not include installation or setup instructions.
For assistance with installation, configuration, enablement, or to join the Early Adoption Program, contact your Cloudera representative or Cloudera Octopai Support.
Supported NiFi versions
-
NiFi 1.7 and higher versions.
Recommended NiFi version
For the best experience, use NiFi 1.15 or higher versions. Higher versions offer enhanced metadata extraction, improved parameter context support, better provenance event handling, and critical security updates.
Next steps
Cloudera Octopai is enhancing this connector. Subsequent releases will add the following enhancements:
-
Full inner and end-to-end lineage.
-
Column-level lineage details.
-
Expanded processor support.
-
Support for nested and complex NiFi Process Groups.
Generic SQL Script Extractor
Availability
Available in Cloudera Octopai Agent 10.0
Overview
Cloudera Octopai introduces the Generic SQL Script Extractor, a new capability that extends the Cloudera Octopai automated data lineage extraction to additional environments.
What’s new
The Generic SQL Script Extractor enables the automated extraction and analysis of SQL scripts embedded within XML files—a common format used by custom-built, Java-based, and other enterprise systems for configuration and integration purposes.
This addition allows organizations to extend their lineage mapping to systems that previously could not be easily captured.
Key capabilities
-
Automatically detects and extracts embedded SQL scripts from structured XML outputs.
-
Prepares extracted scripts for ingestion and analysis in the Cloudera Octopai lineage platform.
-
Fully integrates with the Cloudera Octopai upload and metadata processing framework.
-
Includes built-in logging and operational monitoring for enhanced traceability.
Benefits
-
Expands lineage coverage to include systems using XML as an output format for SQL.
-
Reduces manual effort and operational overhead by automating script extraction.
-
Enhances governance, auditability, and change impact analysis across hybrid and custom system landscapes.
Visual examples

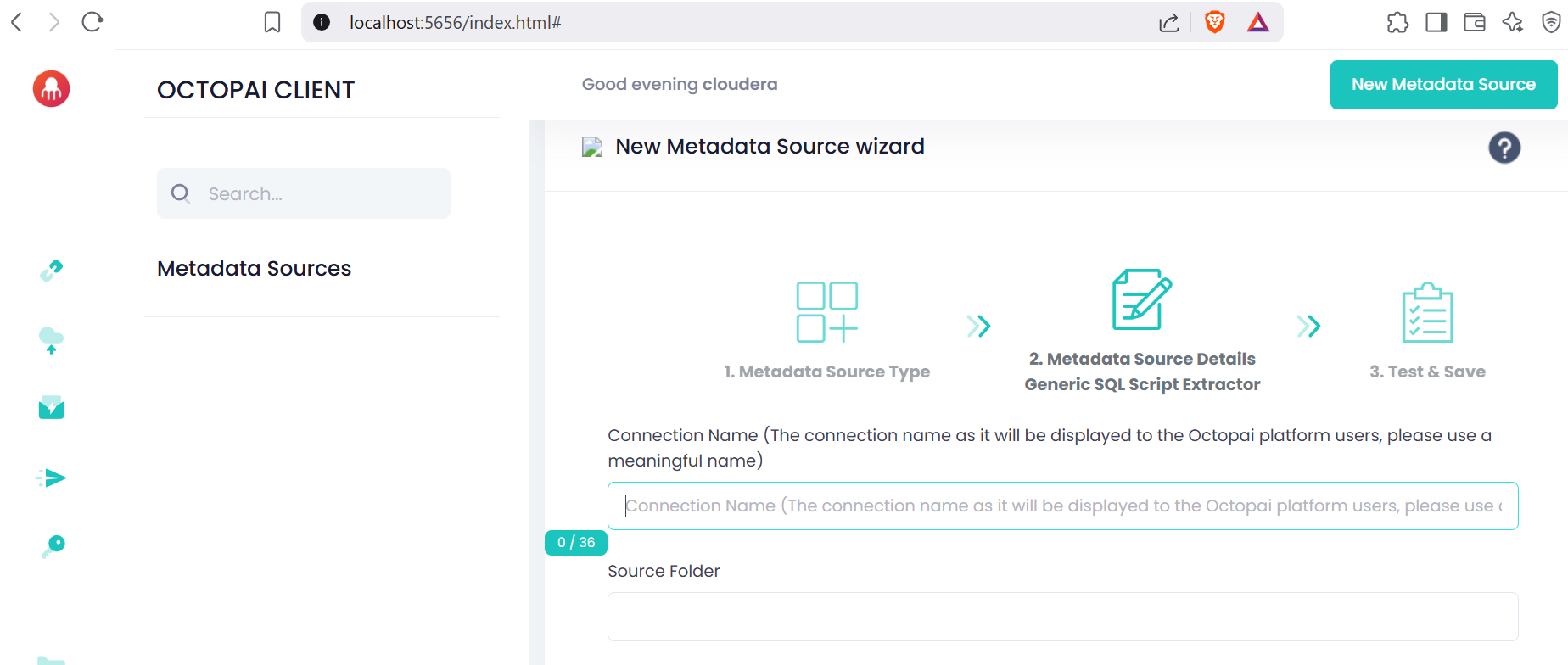
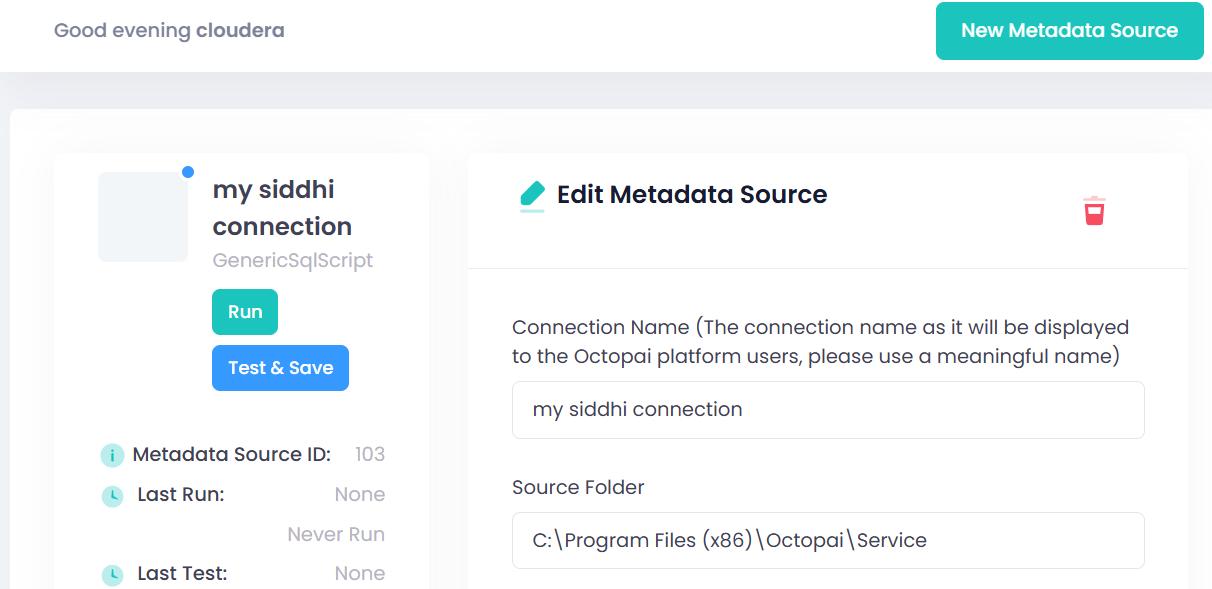
Availability details
-
Available with Cloudera Octopai Agent 10.0 and higher versions.
-
No changes are required to system outputs if SQL scripts are embedded within XML files.
Cloudera Octopai Snowflake Connector Enhancement: Support for Dynamic Tables
Version
Version: Cloudera Octopai Agent 10.0 and above
Overview
The Cloudera Octopai Snowflake connector has been enhanced to support Dynamic Tables—Snowflake’s innovative feature for declaratively defined data pipelines with automatic refresh logic.
Dynamic Tables are increasingly being adopted as a replacement for manual job orchestration tools like Airflow, dbt jobs, and others. They behave similarly to views but offer automated data refresh based on defined logic.
What’s new
-
Dynamic Table extraction: The connector now identifies Dynamic Tables during metadata extraction and retrieves their definition scripts.
-
Enhanced metadata collection: For objects identified as Dynamic Tables (
IS_DYNAMIC = 'YES'), the connector now automatically executes:SELECT GET_DDL('DYNAMIC_TABLE', '<db>.<schema>.<dynamic_table_name>');This allows Cloudera Octopai to extract the full declarative definition, just as it does for views.
-
Improved lineage and impact analysis: Dynamic Tables are now fully incorporated into the Cloudera Octopai lineage and impact analysis processes. Upstream changes affecting Dynamic Tables are captured, enabling complete root cause analysis and audit reporting.
Why it matters
Without this enhancement:
-
Impact and root cause analysis would be incomplete for Snowflake environments leveraging Dynamic Tables.
-
Customers using Dynamic Tables would face gaps in compliance and audit trails, risking incomplete documentation and potential compliance violations.
With this enhancement:
-
Dynamic Tables are fully visible in the Cloudera Octopai lineage maps.
-
Scripts for Dynamic Tables are available for inspection and versioning.
-
Customers gain full confidence in their metadata governance and auditing processes.
Important notes
-
Upgrade required: This capability requires upgrading to the Cloudera Octopai Agent 10.0 or higher versions.
-
Backward compatibility: Existing functionality for standard tables and views remains unchanged. Only customers using Dynamic Tables benefit from this enhancement.