Identifying Throughput Bottlenecks
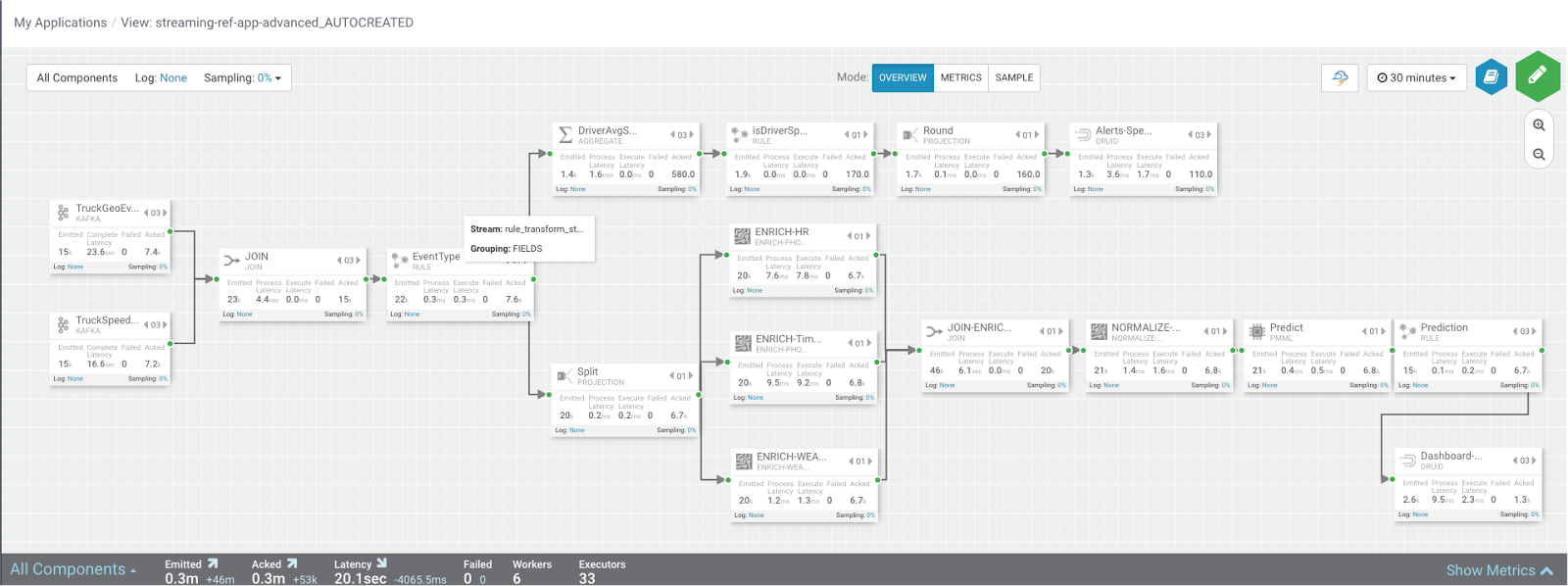
Looking through the metrics the Source and Sink metrics, we want to increase the throughput such that we we emit/consume more events from the Kafka Topic and send more events to Druid sink over time. We make some changes to the app to increase throughput.
Increase the parallelism of TruckGeoEvent (kafka topic: truck_events_avro) and TruckSpeedEvent (kafka topic: truck_speed_events_avro) from 1 to 3. Note that each of these kafka topics have three partitions.
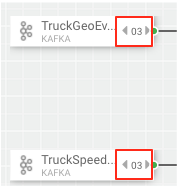
Increase the parallelism of the Join from 1 to 3. Since the join is grouped by driverId, we can configure the connection to use fields grouping to send all events with driverId to the same instance of the Join.
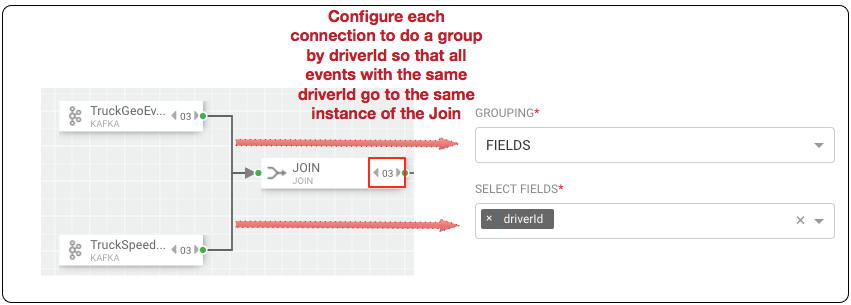
Increase the parallelism of the DriverAvgSpeed aggregrate window from 1 to 3. Since the window groups by driverId,driverName and route, we can configure the connection to use fields grouping to send all events with those field values to the same instance of the window.
Increase the parallelism of the Dashboard-Predictions Druid sink from 1 to 3 so we can have multiple JVM instances of Druid writing to the cube.
After making these changes, we re-deploy the app using SAM and run the data generator for about 15 minutes and view seeing the following metrics.
SAM’s overview and detailed metrics makes it very easy to verify if the performance changes we made had the desired effect.