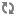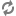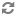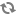The Capacity Scheduler is designed to allow organizations to share compute clusters using the very familiar notion of FIFO (first-in, first-out) queues. YARN does not assign entire nodes to queues. Queues own a fraction of the capacity of the cluster, and this specified queue capacity can be fulfilled from any number of nodes in a dynamic fashion.
Scheduling is the process of matching resource requirements -- of multiple applications from various users, and submitted to different queues at multiple levels in the queue hierarchy -- with the free capacity available on the nodes in the cluster. Because total cluster capacity can vary, capacity configuration values are expressed as percents.
The capacity property can be used by administrators to allocate a
percentage of cluster capacity to a queue. The following properties would divide the
cluster resources between the Engineering, Support, and Marketing organizations in a
6:1:3 ratio (60%, 10%, and 30%).
Property:
yarn.scheduler.capacity.root.engineering.capacity
Value:
60
Property:
yarn.scheduler.capacity.root.support.capacity
Value:
10
Property:
yarn.scheduler.capacity.root.marketing.capacity
Value:
30
Now suppose that the Engineering group decides to split its capacity between the Development and QA sub-teams in a 1:4 ratio. That would be implemented by setting the following properties:
Property:
yarn.scheduler.capacity.root.engineering.development.capacity
Value:
20
Property:
yarn.scheduler.capacity.root.engineering.qa.capacity
Value:
80
![[Note]](../common/images/admon/note.png) | Note |
|---|---|
The sum of capacities at any level in the hierarchy must equal 100%. Also, the capacity of an individual queue at any level in the hierarchy must be 1% or more (you cannot set a capacity to a value of 0). |
The following image illustrates this cluster capacity configuration:
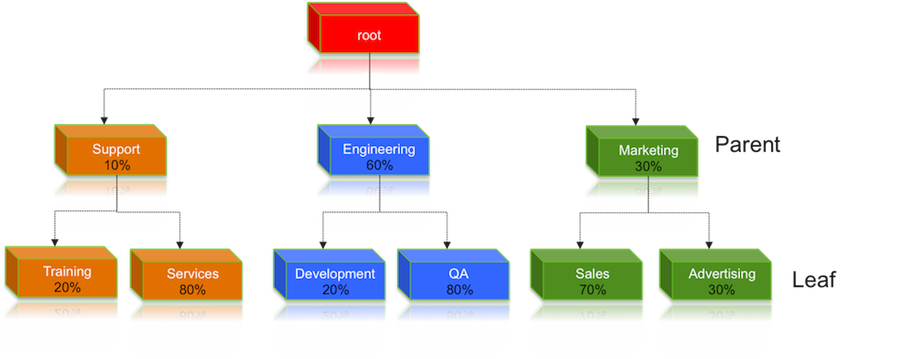
Resource Distribution Workflow
During scheduling, queues at any level in the hierarchy are sorted in the order of their current used capacity, and available resources are distributed among them starting with queues that are currently the most under-served. With respect to capacities alone, the resource scheduling has the following workflow:
The more under-served a queue is, the higher the priority it receives during resource allocation. The most under-served queue is the queue with the least ratio of used capacity as compared to the total cluster capacity.
The used capacity of any parent queue is defined as the aggregate sum of used capacity of all of its descendant queues, recursively.
The used capacity of a leaf queue is the amount of resources used by the allocated Containers of all of the applications running in that queue.
Once it is decided to give a parent queue the currently available free resources, further scheduling is done recursively to determine which child queue gets to use the resources -- based on the previously described concept of used capacities.
Further scheduling happens inside each leaf queue to allocate resources to applications in a FIFO order.
This is also dependent on locality, user level limits, and application limits.
Once an application within a leaf queue is chosen, scheduling also happens within the application. Applications may have different priorities of resource requests.
To ensure elasticity, capacity that is configured but not utilized by any queue due to lack of demand is automatically assigned to the queues that are in need of resources.
Resource Distribution Workflow Example
Suppose our cluster has 100 nodes, each with 10 GB of memory allocated for YARN Containers, for a total cluster capacity of 1000 GB (1 TB). According to the previously described configuration, the Engineering organization is assigned 60% of the cluster capacity, i.e., an absolute capacity of 600 GB. Similarly, the Support organization is assigned 100 GB, and the Marketing organization gets 300 GB.
Under the Engineering organization, capacity is distributed between the Development team and the QA team in a in a 1:4 ratio. So Development gets 120 GB, and 480 GB is assigned to QA.
Now consider the following timeline of events:
Initially, the entire "engineering" queue is free with no applications running, while the "support" and "marketing" queues are utilizing their full capacities.
Users Sid and Hitesh first submit applications to the "development" leaf queue. Their applications are elastic and can run with either all of the resources available in the cluster, or with a subset of cluster resources (depending upon the state of the resource-usage).
Even though the "development" queue is allocated 120 GB, Sid and Hitesh are each allowed to occupy 120 GB, for a total of 240 GB.
This can happen despite the fact that the "development" queue is configured to be run with a capacity of 120 GB. Capacity Scheduler allows elastic sharing of cluster resources for better utilization of available cluster resources. Since there are no other users in the "engineering" queue, Sid and Hitesh are allowed to use the available free resources.
Next, users Jian, Zhijie and Xuan submit more applications to the "development" leaf queue. Even though each is restricted to 120 GB, the overall used capacity in the queue becomes 600 GB -- essentially taking over all of the resources allocated to the "qa" leaf queue.
User Gupta now submits an application to the "qa" queue. With no free resources available in the cluster, his application must wait.
Given that the "development" queue is utilizing all of the available cluster resources, Gupta may or may not be able to immediately get back the guaranteed capacity of his "qa" queue -- depending upon whether or not preemption is enabled.
As the applications of Sid, Hitesh, Jian, Zhijie, and Xuan finish running and resources become available, the newly available Containers will be allocated to Gupta’s application. This will continue until the cluster stabilizes at the intended 1:4 resource usage ratio for the "development" and "qa" queues.
From this example, you can see that it is possible for abusive users to submit
applications continuously, and thereby lock out other queues from resource allocation
until Containers finish running or get preempted. To avoid this scenario, Capacity
Scheduler supports limits on the elastic growth of any queue. For example, to restrict
the "development" queue from monopolizing the "engineering" queue capacity, an
administrator can set a the maximum-capacity property:
Property:
yarn.scheduler.capacity.root.engineering.development.maximum-capacity
Value:
40
Once this is set, users of the "development" queue can still go beyond their capacity of 120 GB, but they will not be allocated any more than 40% of the "engineering" parent queue's capacity (i.e., 40% of 600 GB = 240 GB).
The capacity and maximum-capacity properties can be used to
control sharing and elasticity across the organizations and sub-organizations utilizing
a YARN cluster. Administrators should balance these properties to avoid strict limits
that result in a loss of utilization, and to avoid excessive cross-organization sharing.
Capacity and maximum capacity settings can be dynamically changed at run-time using
yarn rmadmin -refreshQueues.