
Advanced Connection Management Features
By default, all connections for a user are forwarded to the same Spark AM to execute the query. In some cases, it is necessary to exercise finer-grained control.
Specifying Named Connections
When user impersonation is enabled, Spark supports user-named connections identified
by a user-specified connectionId (a Hive conf parameter in the
connection URL). This can be useful when overriding Spark configurations such as queue,
memory configuration, or executor configuration settings.
Every Spark AM managed by the Spark Thrift server is associated with a user and
connectionId. Connection IDs are not globally unique; they are specific to
the user.
You can specify connectionId to control which Spark AM executes
queries. If you not specify connectionId, a default connectionId is
associated with the Spark AM.
To explicitly name a connection, set the Hive conf parameter to
spark.sql.thriftServer.connectionId, as shown in the following
session:

Note: Named connections allow users to specify their own Spark AM connections. They are scoped to individual users, and do not allow a user to access the Spark AM associated with another user.

If the Spark AM is available, the connection is associated with the existing Spark AM.
Data Sharing and Named Connections
Each connectionId for a user identifies a different Spark AM.
For a user, cached data is shared and available only within a single AM, not across Spark AM’s.
Different user connections on the same Spark AM can leverage previously cached data. Each user connection has its own Hive session (which maintains the current database, Hive variables, and so on), but shares the underlying cached data, executors, and Spark application.
The following example shows a session for the first connection from user “foo” to named connection “conn1”:
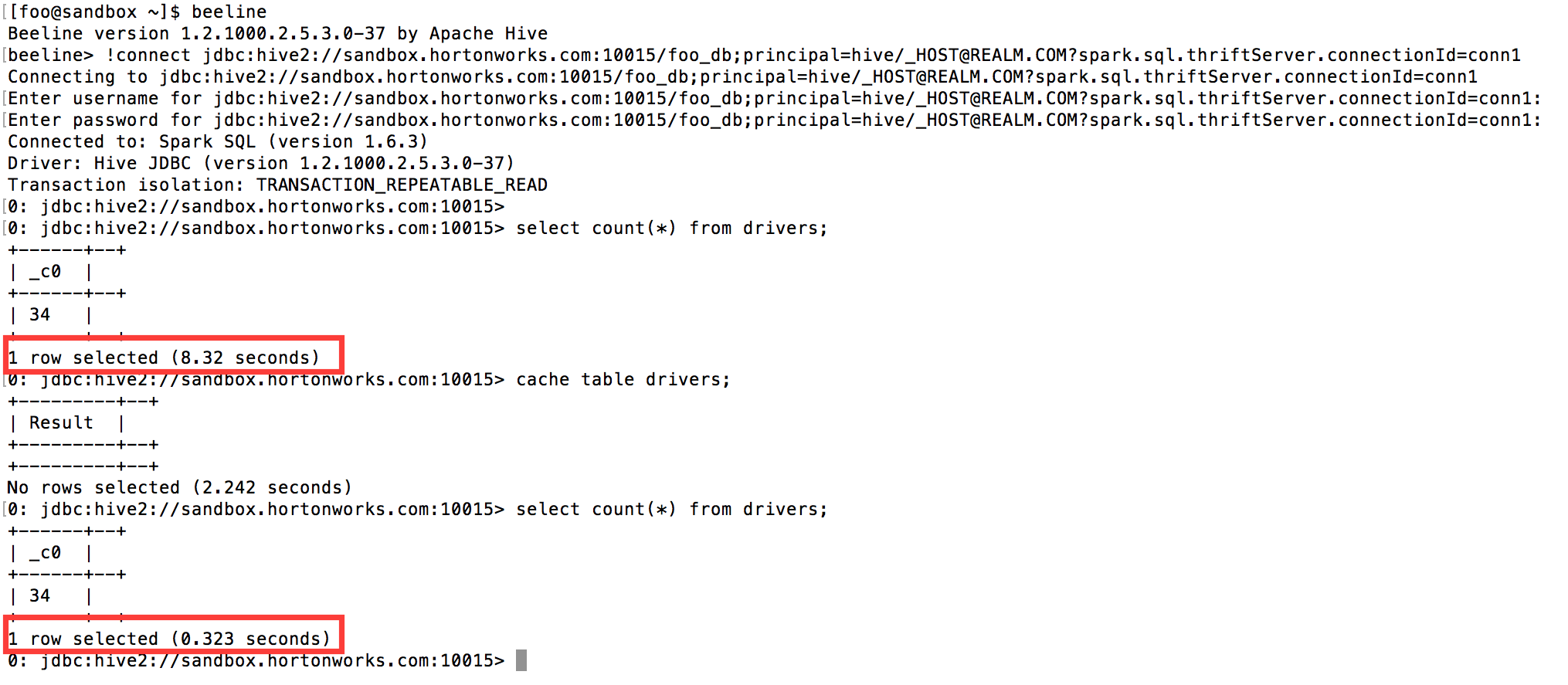
After caching the ‘drivers’ table, the query runs an order of magnitude faster.
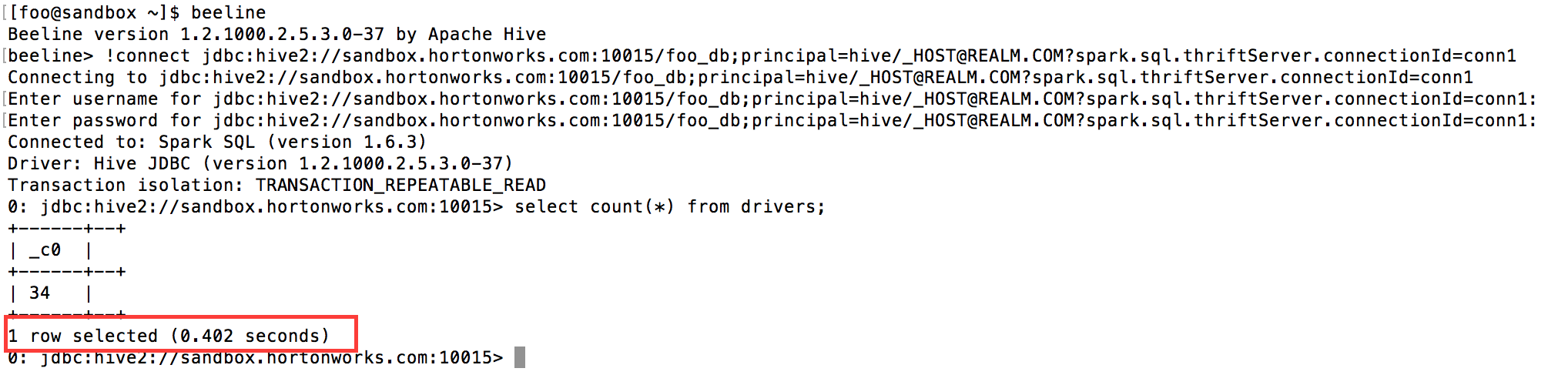
A second connection to the same connectionId from user “foo”
leverages the cached table from the other active Beeline session, significantly increasing
query execution speed:
Overriding Spark Configuration Settings
If the Spark Thrift server is unable to find an existing Spark AM for a user
connection, by default the Thrift server launches a new Spark AM to service user queries.
This is applicable to named connections and unnamed connections. When a new Spark AM is to
be launched, you can override current Spark configuration settings by specifying them in
the connection URL. Specify Spark configuration settings as hiveconf
variables prepended by the sparkconf prefix:
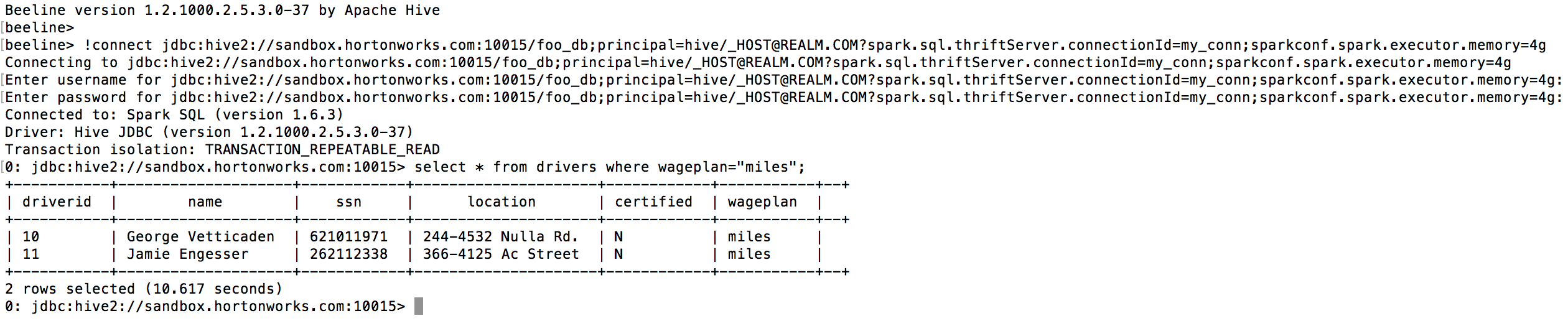
The following connection URL includes a spark.executor.memory setting of
4 GB:
jdbc:hive2://sandbox.hortonworks.com:10015/foo_db;principal=hive/_HOST@REALM.COM?spark.sql.thriftServer.connectionId=my_conn;sparkconf.spark.executor.memory=4g
The environment tab of the Spark application shows the appropriate value:
