

Using the Hive Warehouse Connector with Spark
This section provides a brief overview of the Hive Warehouse Connector with Apache Spark. For details, see the detailed Hive Warehouse Connector documentation (link below).
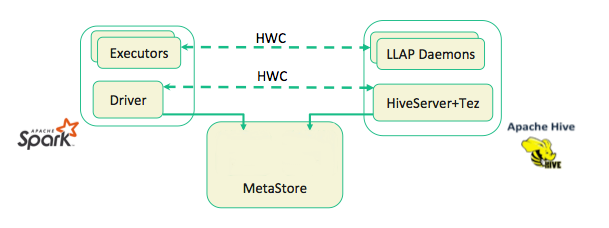
Spark cannot read from or write to ACID tables, so Hive catalogs and the Hive Warehouse Connector (HWC) have been introduced in order to accommodate these improvements.
Updates for HDP-3.0:
- Hive and Spark share the same catalog in the Hive Metastore in HDP 3.1.5 and later.
- You can use the Hive Warehouse Connector to read and write Spark DataFrames and Streaming DataFrames to and from Apache Hive using low-latency, analytical processing (LLAP). Apache Ranger and the Hive Warehouse Connector now provide fine-grained row and column access control to Spark data stored in Hive.