

Using Spark Streaming
This section provides information on using Spark streaming.
Before running a Spark Streaming application, Spark and Kafka must be deployed on the cluster.
Unless you are running a job that is part of the Spark examples package installed by Hortonworks Data Platform (HDP), you must add or retrieve the HDP spark-streaming-kafka .jar file and associated .jar files before running your Spark job.
Spark Streaming is an extension of the core spark package. Using Spark
Streaming, your applications can ingest data from sources such as Apache Kafka and
Apache Flume; process the data using complex algorithms expressed with high-level
functions like map, reduce, join, and
window; and send results to file systems, databases, and live
dashboards.
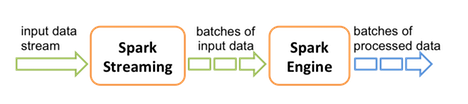
Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches:
See the Apache Spark Streaming Programming Guide for conceptual information; programming examples in Scala, Java, and Python; and performance tuning recommendations.
Apache Spark has built-in support for the Apache Kafka 08 API. If you want to access a Kafka 0.10 cluster using new Kafka 0.10 APIs (such as wire encryption support) from Spark streaming jobs, the spark-kafka-0-10-connector package supports a Kafka 0.10 connector for Spark streaming. See the package readme file for additional documentation.
The remainder of this subsection describes general steps for developers using Spark
Streaming with Kafka on a Kerberos-enabled cluster; it includes a sample
pom.xml file for Spark Streaming applications with Kafka. For
additional examples, see the Apache GitHub example repositories for Scala, Java, and
Python.
 | Important |
|---|---|
Dynamic Resource Allocation does not work with Spark Streaming.
|