

Hive Warehouse Connector for accessing Apache Spark data
The Hive Warehouse Connector (HWC) is a Spark library/plugin that is launched with the Spark app. You use the Hive Warehouse Connector API to access any managed Hive table from Spark. You must use low-latency analytical processing (LLAP) in HiveServer Interactive to read ACID, or other Hive-managed tables, from Spark.
In HDP 3.1.5 and later, Spark and Hive share a catalog in Hive metastore (HMS) instead of using separate catalogs, which was the case in HDP 3.1.4 and earlier.
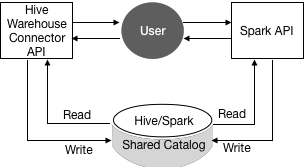
The shared catalog simplifies use of HWC. To read the Hive external table from Spark, you no longer need to define the table redundantly in the Spark catalog. Also, HDP 3.1.5 introduces HMS table transformations. HMS detects the type of client for interacting with HMS, for example Hive or Spark, and compares the capabilities of the client with the table requirement. A resulting action occurs that makes sense given the client capabilities and other factors. See link below.
The default table type created from Spark using HWC has changed to external. The
external.table.purge property is set to true, so external table behavior is like HDP 2.x
managed tables with regard to the drop statement, which now drops the table data, not just the schema.
When you use SparkSQL, standard Spark APIs access tables in the Spark catalog.
You use low-latency analytical processing (LLAP) in HiveServer Interactive to read ACID, or other Hive-managed tables, from Spark is recommended. You do not need LLAP to write to ACID, or other managed tables, from Spark. You do not need HWC to access external tables from Spark.
Using the HWC, you can read and write Apache Spark DataFrames and Streaming DataFrames. Apache Ranger and the HiveWarehouseConnector library provide row and column, fine-grained access to the data.
- From HWC, writes are supported for ORC tables only.
- Table stats are not generated when you write a DataFrame to Hive.
- The spark thrift server is not supported.
- When the HWC API save mode is overwrite, writes are limited.
You cannot read from and overwrite the same table. If your query accesses only one table and you try to overwrite that table using an HWC API write method, a deadlock state might occur. Do not attempt this operation.
Example: Operation Not Supported
scala> val df = hive.executeQuery("select * from t1") scala> df.write.format("com.hortonworks.spark.sql.hive.llap.HiveWarehouseConnector").mode("overwrite").option("table", "t1").save
Supported applications and operations
- Spark shell
- PySpark
- The spark-submit script
- Describing a table
- Creating a table for ORC-formatted data
- Selecting Hive data and retrieving a DataFrame
- Writing a DataFrame to Hive in batch
- Executing a Hive update statement
- Reading Hive table data, transforming it in Spark, and writing it to a new Hive table
- Writing a DataFrame or Spark stream to Hive using HiveStreaming