

Read and write operations
The API supports reading and writing Hive tables from Spark. HWC supports writing to ORC tables only. You can update statements and write DataFrames to partitioned Hive tables, perform batch writes, and use HiveStreaming.
Pruning and pushdowns
spark.datasource.hive.warehouse.disable.pruning.and.pushdowns property is
set to true. Incorrect data can appear when one dataframe is derived from the other with
different filters or projections (parent-child dataframe with different set of
filters/projections). Spark 2.3.x creates only one read instance per parent dataframe and
uses that instance for all actions on any child dataframe. The following example shows one
of many ways the problem can occur during filtering: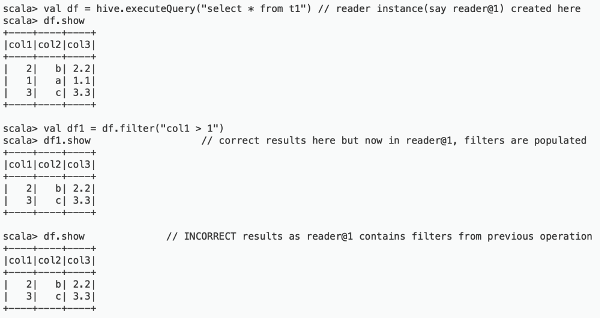

To prevent these issues and ensure correct results, do not enable pruning and pushdowns. To enable pruning and pushdown, set the spark.datasource.hive.warehouse.disable.pruning.and.pushdowns=false.
Read operations
Execute a Hive SELECT query and return a DataFrame.
hive.executeQuery("select * from web_sales")
HWC supports push-downs of DataFrame filters and projections applied to executeQuery.
Execute a Hive update statement
Execute CREATE, UPDATE, DELETE, INSERT, and MERGE statements in this way:
hive.executeUpdate("ALTER TABLE old_name RENAME TO
new_name")
Write a DataFrame to Hive in batch
This operation uses LOAD DATA INTO TABLE.
Java/Scala:
df.write.format(HIVE_WAREHOUSE_CONNECTOR).option("table", <tableName>).save()Python:
df.write.format(HiveWarehouseSession().HIVE_WAREHOUSE_CONNECTOR).option("table", &tableName>).save()Write a DataFrame to Hive, specifying partitions
HWC follows Hive semantics for overwriting data with and without partitions and is not
affected by the setting of spark.sql.sources.partitionOverwriteMode to
static or dynamic. This behavior mimics the latest Spark Community trend reflected in
Spark-20236 (link below).
Java/Scala:
df.write.format(HIVE_WAREHOUSE_CONNECTOR).option("table", <tableName>).option("partition", <partition_spec>).save()Python:
df.write.format(HiveWarehouseSession().HIVE_WAREHOUSE_CONNECTOR).option("table", &tableName>).option("partition", <partition_spec>).save()<partition_spec> is in one of the following forms:option("partition", "c1='val1',c2=val2") // staticoption("partition", "c1='val1',c2") // static followed by dynamicoption("partition", "c1,c2") // dynamic
- No partitions specified = LOAD DATA
- Only static partitions specified = LOAD DATA...PARTITION
- Some dynamic partition present = CREATE TEMP TABLE + INSERT INTO/OVERWRITE query.
Note: Writing static partitions is faster than writing dynamic partitions.
Write a DataFrame to Hive using HiveStreaming
When using HiveStreaming to write a DataFrame to Hive or a Spark Stream to Hive, you need to escape any commas in the stream, as shown in Use the Hive Warehouse Connector for Streaming (link below).
Java/Scala:
//Using dynamic partitioning
df.write.format(DATAFRAME_TO_STREAM).option("table", <tableName>).save()
//Or, writing to a static partition
df.write.format(DATAFRAME_TO_STREAM).option("table", <tableName>).option("partition", <partition>).save() Python:
//Using dynamic partitioning
df.write.format(HiveWarehouseSession().DATAFRAME_TO_STREAM).option("table", <tableName>).save()
//Or, writing to a static partition
df.write.format(HiveWarehouseSession().DATAFRAME_TO_STREAM).option("table", <tableName>).option("partition", <partition>).save() Write a Spark Stream to Hive using HiveStreaming
Java/Scala:
stream.writeStream.format(STREAM_TO_STREAM).option("table", "web_sales").start()Python:
stream.writeStream.format(HiveWarehouseSession().STREAM_TO_STREAM).option("table", "web_sales").start()