Cloudera Data Engineering example jobs and sample data
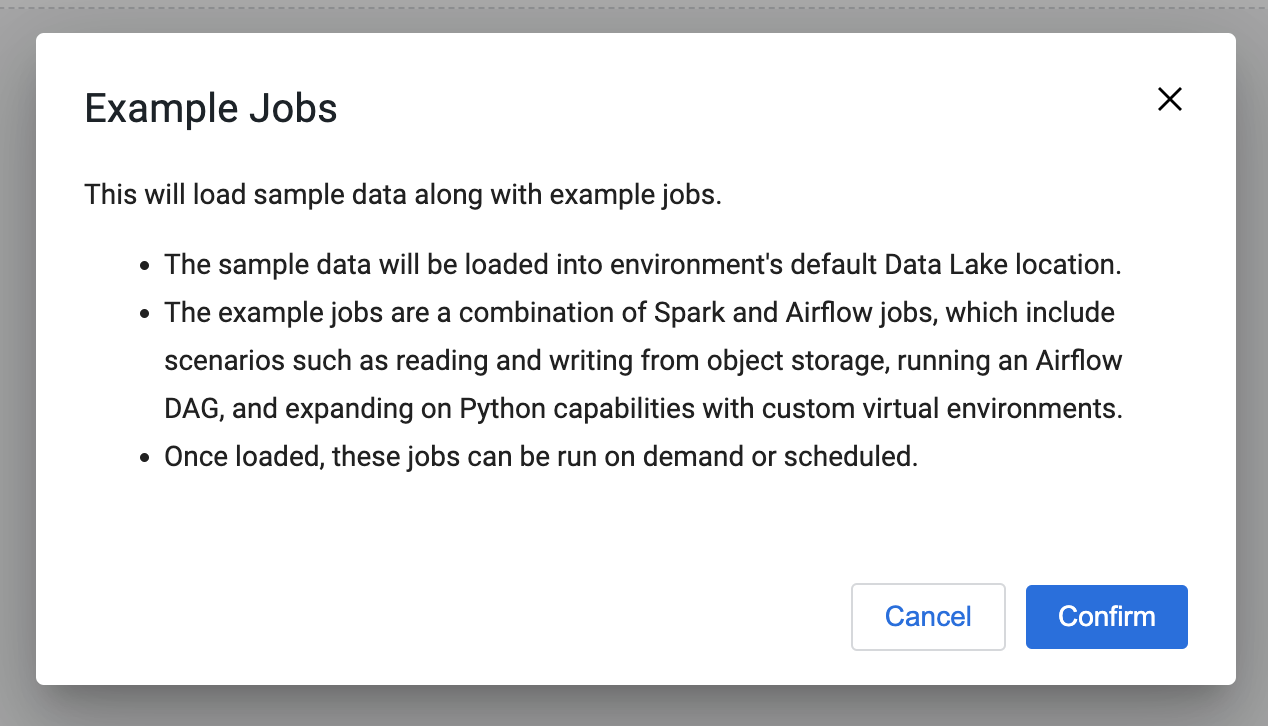
Cloudera Data Engineering provides a suite of example jobs that operate on example data to showcase its core capabilities and make the onboarding easier. The example jobs are a combination of Spark and Airflow jobs, which include scenarios such as reading and writing from object storage, running an Airflow DAG, and expanding on Python capabilities with custom virtual environments. Once loaded, these jobs can be run on demand or scheduled. The sample data will be loaded into the environment's default Data Lake location.
In Cloudera Data Engineering, jobs are associated with virtual clusters. Before you can create a job, you must register a Cloudera environment and Data Lake, and create a Cloudera Data Engineering Service and virtual cluster. For more information, see Environments, Enabling Cloudera Data Engineering service, and Creating virtual clusters .
| Job | Description |
|---|---|
example-load-data |
Loads the sample data onto the environment data lake. This job runs only once and is then deleted. |
example-virtual-env |
Demonstrates Cloudera Data Engineering job configuration that utilizes Python Environment resource type to expand pyspark features via custom virtual env. This example adds pandas support. |
example-resources |
Demonstrates Cloudera Data Engineering job configuration utilizing file-based resource type. Resources are mounted on Spark driver and executor pods. This example uses an input file as a data source for a word-count Spark app. The driver stderr log contains the word count. |
example-resources-schedules |
Demonstrates scheduling functionality for Spark job in Cloudera Data Engineering. This example schedules a job to run at 5:04am UTC each day. |
example-spark-pi |
Demonstrates how to define a Cloudera Data Engineering job. It runs a SparkPi using a scala example jar located on a s3 bucket. The driver stderr log contains the value of pi. |
example-cdeoperator |
Demonstrates job orchestration using Airflow. This example uses a custom Cloudera Data Engineering Operator to run two Spark jobs in sequence, mimicking a pipeline composed of data ingestion and data processing. |
example-object-store |
Demonstrates how to access and write data to object store on different form factors: S3, ADLS, and HDFS. This example reads data already staged to object store and makes changes and then saves back the transformed data to object store. The output of the query ran on the object store table can be viewed in the driver stderr log. |
example-iceberg |
Demonstrates support for iceberg table format. This example reads raw data from object store and saves data in iceberg table format and showcases iceberg metadata inforation, such as snapshots. |
-
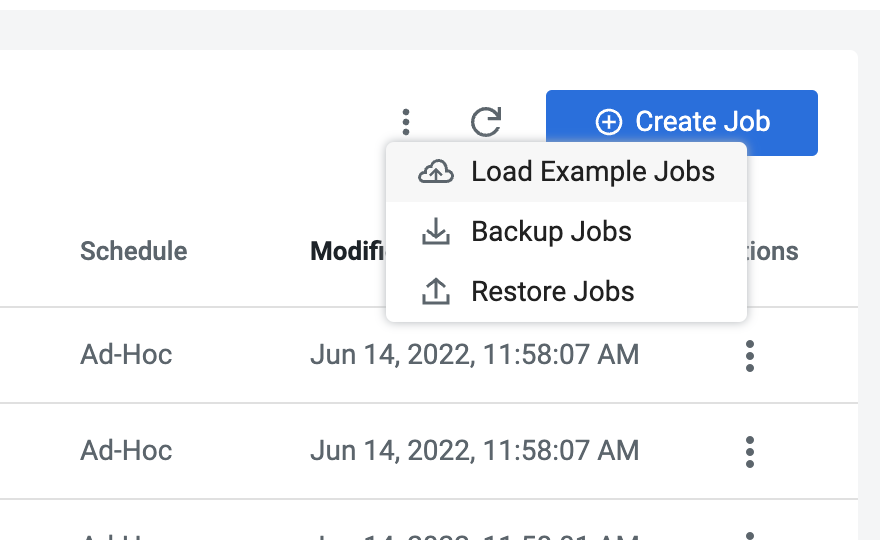
Select Load Example Jobs from the two options that
appear.

-
If you have existing jobs in the virtual cluster, click
 on the jobs page to
Load Example Jobs.
on the jobs page to
Load Example Jobs.
-
A dialog box appears explaining the example jobs and sample data. Click
Confirm to load example jobs and sample data.