Trino is a distributed SQL query engine designed from the bottom up to be built around
the concept of connectors and federation. Trino connectors help you connect to and access data
from a variety of remote data sources, expose metadata (exposed within Trino as catalogs), and
handle sending or receiving data from the remote source.
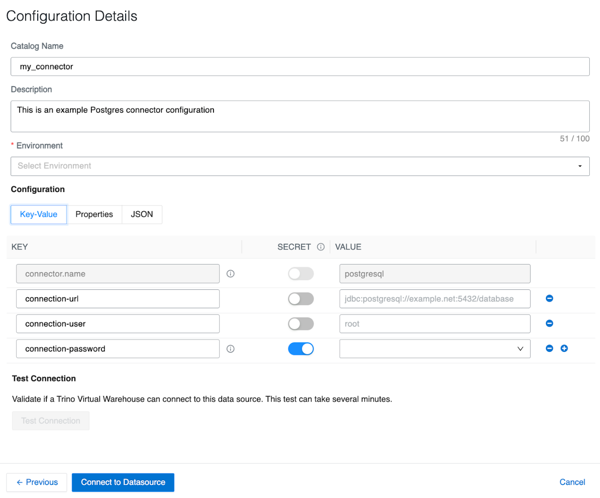
You can use Cloudera Data Warehouse to configure a connector for a data source,
enabling a Trino Virtual Warehouse to access the data source. You can either create an Optimized
connector (tested and certified by Cloudera) or a
Community connector.
When you create an optimized connector, a template specific to the selected data source type is
provided for you to specify the connector configuration details, such as connector URL and
secrets that are required to access the data source. You can also choose community data source
types that are powered by open-source Trino, however, these connectors are not directly supported
by Cloudera and do not offer default configuration.
Cloudera enables you to configure connectors for the
following data sources: