Developing a dataflow for Stateless NiFi
Learn about the recommended process of building a dataflow that you can deploy with the Stateless NiFi Sink or Source connectors. This process involves building and designing a parameterized dataflow within a process group and then downloading the dataflow as a flow definition.
The general steps for building a dataflow are identical for both source and sink connector flows. For ease of understanding a dataflow example for a simple MQTT Source and MQTT Sink connector is provided without going into details (what processors to use, what parameters and properties to set, what relationships to define and so on).
- Ensure that you reviewed Dataflow development best practices for Stateless NiFi.
- You have access to a running instance of NiFi. The NiFi instance does not need to run on a cluster. A standalone instance running on any machine, like your own computer, is sufficient.
- Ensure that the version of your NiFi instance matches the versions of the Stateless NiFi
plugin used by Kafka Connect on your cluster.
You can look up the Stateless NiFi plugin version either by using the Streams Messaging Manager (SMM) UI, or by logging into a Kafka Connect host and checking the Connect plugin directory. In addition, ensure that you note down the plugin version. You will need to manually edit the flow definition JSON and replace the NiFi version with the plugin version.
- Access the SMM UI, and click
 Connect in the navigation sidebar.
Connect in the navigation sidebar. - Click the
 New Connector option.
New Connector option. - Locate the StatelessNiFiSourceConnector or
StatelessNiFiSinkConnector cards. The version is located
on the card.
The version is made up of multiple digits. The first three represent the NiFi version. For example, if the version on the card is
1.18.0.2.4.3.0-63, then you should use NiFi1.18.0to build your flow.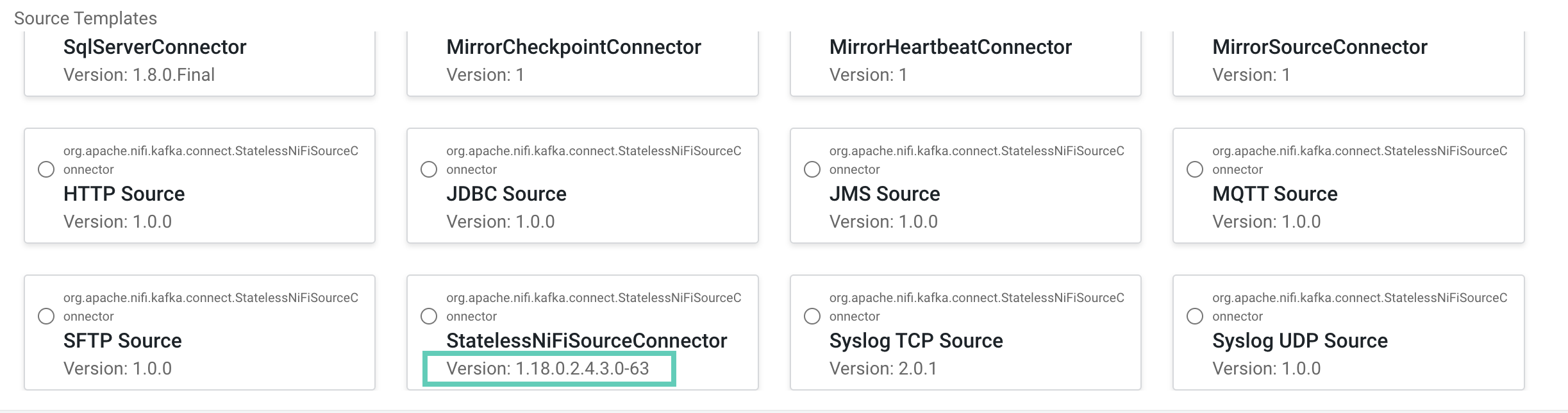
- Access the SMM UI, and click
- Design and parameterize your dataflow.For example, you can build a dataflow that you deploy as a source connector. The following is an example dataflow for a simple MQTT source connector. It consists of a ConsumeMQTT processor and an output port (representing a Kafka topic).
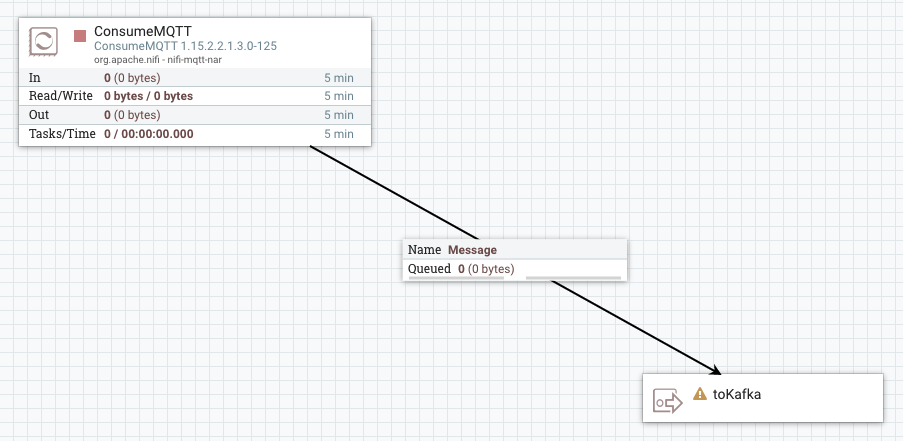
Alternatively, you can also build a dataflow to deploy as a sink connector. The following is an example dataflow for a simple MQTT sink connector. It consists of an input port (representing a Kafka topic), a PublishMQTT processor, and two output ports.
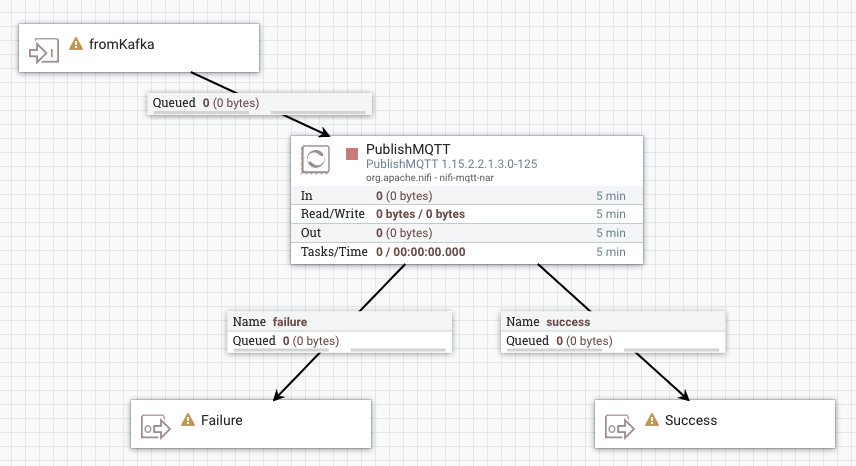
In the case of this example, a failure output port is required. This is done so that in case the destination is not available, the session can be rolled back and the Kafka message can be declined. The failure port is specified in the configuration of the connector when deploying it through SMM.
When designing and building your dataflow, ensure that you update your parameter context and reference the parameters in your components. For example:
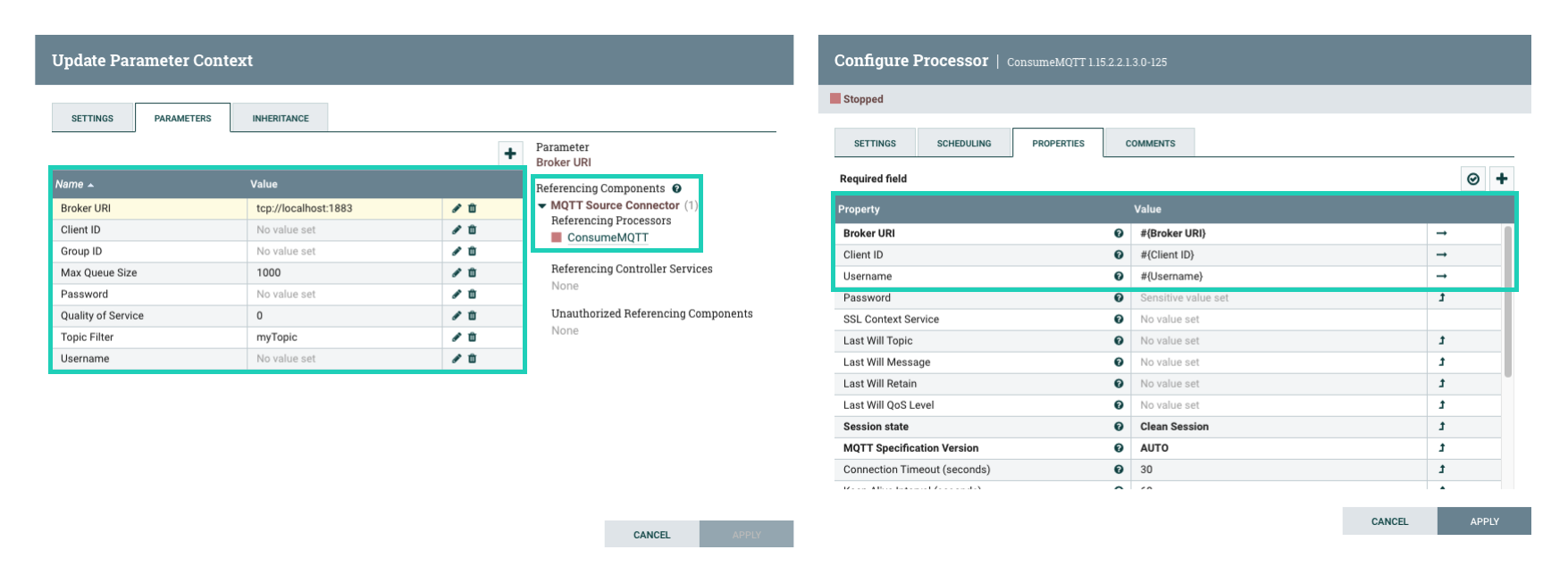
Keep in mind that sensitive properties in processors or controller services must always be parametrized. That is, they must get their values from a parameter in the process group’s parameter context. This is because the values of sensitive properties are not exported with the process group, therefore, they must be configurable when deploying the connector.
Additionally, sensitive processor or controller service properties can only reference sensitive parameter context parameters. That is, the parameter must be marked as sensitive during creation.
For more information on building dataflows, parameters, and referencing parameters, see the Flow Management library.