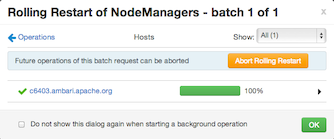
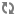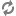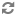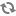When you restart multiple services, components, or hosts, use rolling restarts to distribute the task; minimizing cluster downtime and service disruption. A rolling restart stops, then starts multiple, running slave components such as DataNodes, TaskTrackers, NodeManagers, RegionServers, or Supervisors, using a batch sequence. You set rolling restart parameter values to control the number of, time between, tolerance for failures, and limits for restarts of many components across large clusters.
To run a rolling restart:
Select a Service, then link to a lists of specific components or hosts that Require Restart.
Select Restart, then choose a slave component option.
Review and set values for Rolling Restart Parameters.
Optionally, reset the flag to only restart components with changed configurations.
Choose Trigger Restart.
Use Background Operations to monitor progress of rolling restarts.
When you choose to restart slave components, use parameters to control how restarts of components roll. Parameter values based on ten percent of the total number of components in your cluster are set as default values. For example, default settings for a rolling restart of components in a 3-node cluster restarts 1 component at a time, waits 2 minutes between restarts, will proceed if only one failure occurs, and restarts all existing components that run this service.
If you trigger a rolling restart of components, Restart components with stale configs defaults to true. If you trigger a rolling restart of services, Restart services with stale configs defaults to false.
Rolling restart parameter values must satisfy the following criteria:
Table 2.7. Validation Rules for Rolling Restart Parameters
| Parameter | Required | Value | Description |
|---|---|---|---|
| Batch Size | Yes | Must be an integer > 0 | Number of components to include in each restart batch. |
| Wait Time | Yes | Must be an integer > = 0 | Time (in seconds) to wait between queuing each batch of components. |
| Tolerate up to x failures | Yes | Must be an integer > = 0 | Total number of restart failures to tolerate, across all batches, before halting the restarts and not queuing batches. |