
Chapter 5. Deploy an Application
Configure Deployment Settings
About This Task
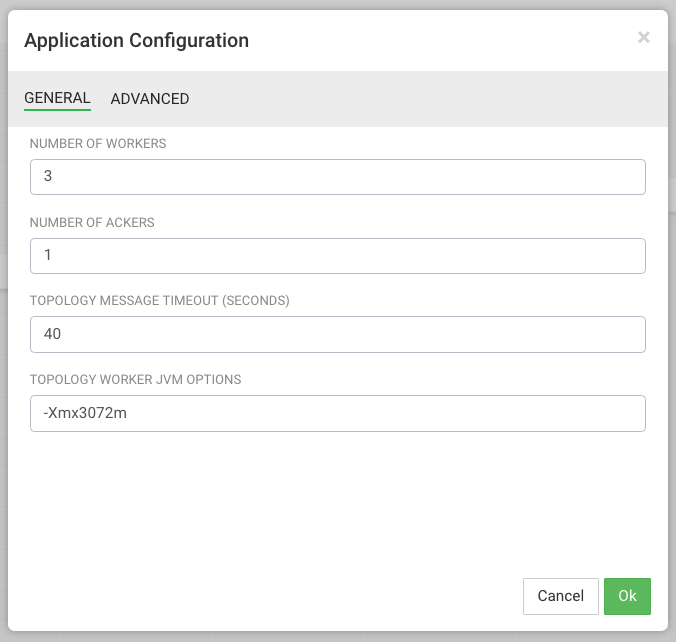
Before deploying the application, you must configure deployment settings such as JVM size, number of ackers, and number of workers. Because this topology uses a number of joins and windows, you should increase the JVM heap size for the workers.
Steps
Click the gear icon on the top right corner of the canvas to display the Application Configuration dialog.
Increase Number of Workers to 5.
Set Topology Worker JVM Options to -Xmx3072m.
Example
Deploy the App
After you have configure the application's deployment settings, click the Deploy button on the lower right of the canvas.
During the deployment process, Streaming Analytics Manager completes the following tasks:
Construct the configurations for the different big data services used in the stream app.
Create a deployable jar of the streaming app.
Upload and deploy the app jar to streaming engine server.
As SAM works through these tasks, it displays a progress bar.
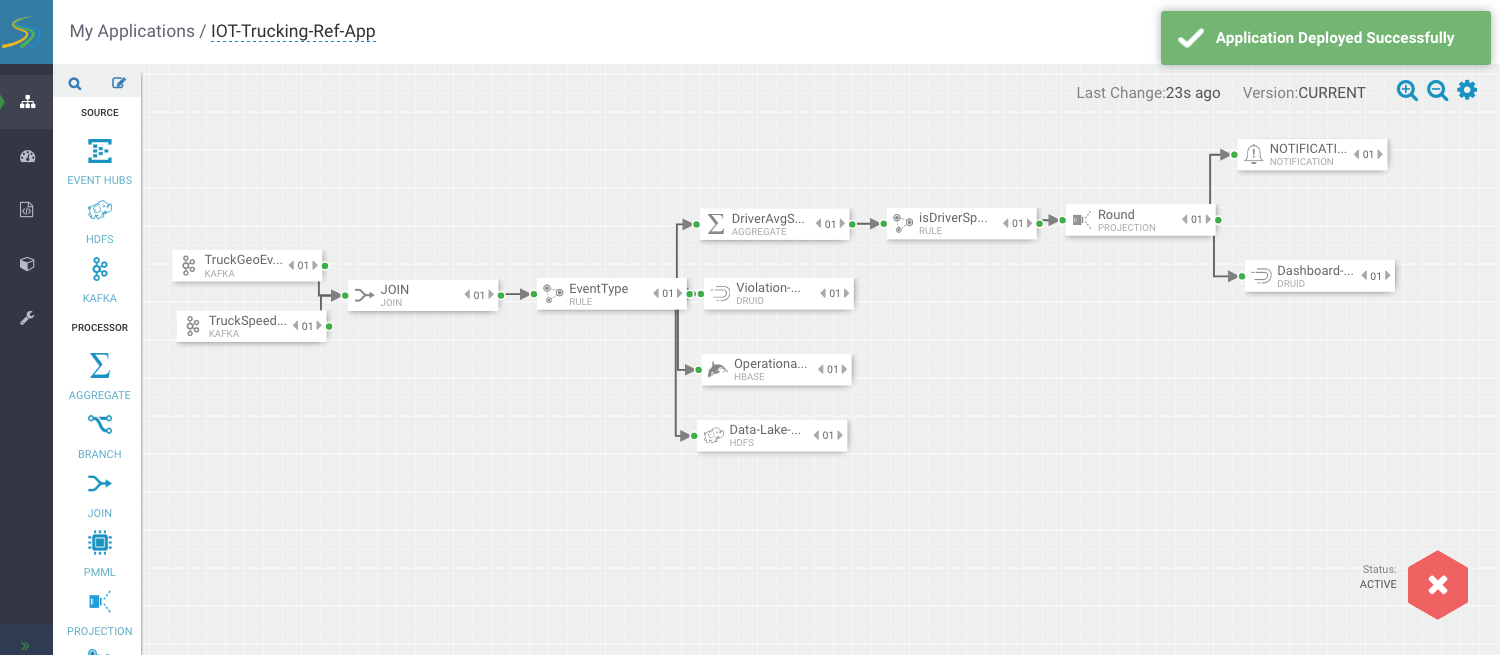
The stream application is deployed to a Storm cluster based on the Storm Service defined in the Environment associated with the application.
After the application has been deployed successfully, SAM notifies you and updates the button to red to indicate it is deployed. Click the red button to kill/undeploy the app.
Running the Stream Simulator
Now that you have developed and deployed the NiFi Flow Application and the Stream Analytics Application, we are ready to run a data simulator that generates truck geo events and sensor events for the apps to process.
To generate the raw truck events serialized into Avro objects using the Schema registry and publish them into the raw Kafka topics, do the following:
Download the Data-Loader.
Unzip it and copy it to the node the cluster. Lets call the directory you unzip it to as: $DATA_LOADER_HOME. Then execute the following. Make sure to replace variables below with your environment specific values (you can find the REST URL to schema registry in Ambari under SAM service for config value registry.url) . Make sure java (jdk 1.8) is on your classpath.
tar -zxvf $DATA_LOADER_HOME/routes.tar.gz nohup java -cp \ stream-simulator-jar-with-dependencies.jar \ hortonworks.hdp.refapp.trucking.simulator.SimulationRegistrySerializerRunnerApp \ 20000 \ hortonworks.hdp.refapp.trucking.simulator.impl.domain.transport.Truck \ hortonworks.hdp.refapp.trucking.simulator.impl.collectors.KafkaEventSerializedWithRegistryCollector \ 1 \ $DATA_LOADER_HOME/routes/midwest/ \ 10000 \ $KAFKA_BROKER_HOST:$KAFKA_PORT \ $REST_URL_TO_SCHEMA_REGISTRY \ ALL_STREAMS \ NONSECURE &
You should see events being published into the Kafka topics called: raw-truck_events_avro and raw-truck_speed_events_avro, Nifi should be consuming those, enriching them and then pushing into the truck_events_avro and truck_speed_events_avro kafka topics and then SAM consumes from those topics.