
Managing Apache HBase Clusters
Monitoring Apache HBase Clusters
If you have an Ambari-managed HBase cluster, you can monitor cluster performance with Grafana-based dashboards. The dashboards provide graphical visualizations of data distribution and other boilerplate performance metrics. You can hover over and click graphs to focus on specific metrics or data sets, as well as to redraw visualizations dynamically.
The interactive capabilities of the dashboards can help you to discover potential bottlenecks in your system. For example, you can scan the graphs to get an overview of cluster activity and scroll over a particular time interval to enlarge details about the activity in the time frame to uncover when the data load is unbalanced. Another potential use case is to help you examine if RegionServers need to be reconfigured.
See Using Grafana Dashboards in Ambari for information about how to access the dashboards and for details about what cluster metrics are displayed.
Optimizing Apache HBase I/O
This section introduces HBase I/O and describes several ways to optimize HBase it.
The information in this section is oriented toward basic BlockCache and MemStore tuning. As such, it describes only a subset of cache configuration options. HDP supports additional BlockCache and MemStore properties, as well as other configurable performance optimizations such as remote procedure calls (RPCs), HFile block size settings, and HFile compaction. For a complete list of configurable properties, see the hbase-default.xml source file in GitHub.
An Overview of HBase I/O
The following table describes several concepts related to HBase file operations and memory (RAM) caching.
HBase Component | Description |
|---|---|
HFile | An HFile contains table data, indexes over that data, and metadata about the data. |
Block | An HBase block is the smallest unit of data that can be read from an HFile. Each HFile consists of a series of blocks. (Note: an HBase block is different from an HDFS block or other underlying file system blocks.) |
BlockCache | BlockCache is the main HBase mechanism for low-latency random read operations. BlockCache is one of two memory cache structures maintained by HBase. When a block is read from HDFS, it is cached in BlockCache. Frequent access to rows in a block cause the block to be kept in cache, improving read performance. |
MemStore | MemStore ("memory store") is in-memory storage for a RegionServer. MemStore is the second of two cache structures maintained by HBase. MemStore improves write performance. It accumulates data until it is full, and then writes ("flushes") the data to a new HFile on disk. MemStore serves two purposes: it increases the total amount of data written to disk in a single operation, and it retains recently written data in memory for subsequent low-latency reads. |
Write Ahead Log (WAL) | The WAL is a log file that records all changes to data until the data is successfully written to disk (MemStore is flushed). This protects against data loss in the event of a failure before MemStore contents are written to disk. |
BlockCache and MemStore reside in random-access memory (RAM). HFiles and the Write Ahead Log are persisted to HDFS.
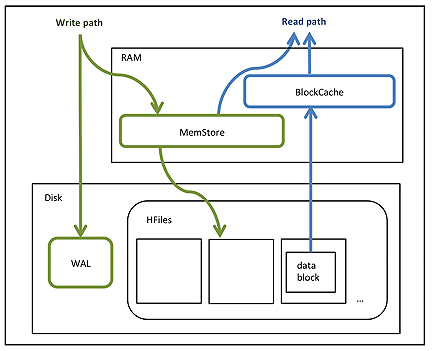
The following figure shows these simplified write and read paths:
During write operations, HBase writes to WAL and MemStore. Data is flushed from MemStore to disk according to size limits and flush interval.
During read operations, HBase reads the block from BlockCache or MemStore if it is available in those caches. Otherwise, it reads from disk and stores a copy in BlockCache.
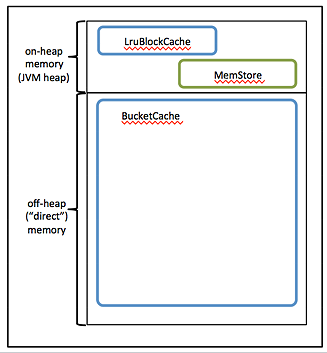
By default, BlockCache resides in an area of RAM that is managed by the Java Virtual Machine (JVM) garbage collector; this area of memory is known as on-heap memory or the JVM heap. The BlockCache implementation that manages the on-heap cache is called LruBlockCache.
If you have stringent read latency requirements and you have more than 20 GB of RAM available on your servers for use by HBase RegionServers, consider configuring BlockCache to use both on-heap and off-heap memory. BucketCache is the off-heap memory equivalent to LruBlockCache in on-heap memory. Read latencies for BucketCache tend to be less erratic than LruBlockCache for large cache loads because BucketCache (not JVM garbage collection) manages block cache allocation. The MemStore always resides in the on-heap memory.
Additional notes:
BlockCache is enabled by default for all HBase tables.
BlockCache is beneficial for both random and sequential read operations although it is of primary consideration for random reads.
All regions hosted by a RegionServer share the same BlockCache.
You can turn BlockCache caching on or off per column family.
Configuring BlockCache
If you have less than 20 GB of RAM available for use by HBase, consider tailoring the default on-heap BlockCache implementation (LruBlockCache) for your cluster.
If you have more than 20 GB of RAM available, consider adding off-heap BlockCache (BucketCache).
To configure either LruBlockCache or BucketCache, start by specifying the maximum amount of on-heap RAM to allocate to the HBase RegionServers on each node. The default is 1 GB, which is too small for production. You can alter the default allocation either with Ambari or in a manual installation:
Ambari: Set a value for the RegionServer maximum Java heap size.
Manual Installation: Set the
HBASE_HEAPSIZEenvironment variable in thehbase-env.shfile. Specify the value in megabytes. For example,HBASE_HEAPSIZE=20480sets the maximum on-heap memory allocation to 20 GB inhbase-env.sh. The HBase startup script uses$HBASE_HEAPSIZEto override the default maximum JVM heap size (-Xmx).
If you want to configure off-heap BlockCache (BucketCache) only, you are done with configuration.
Additional On-Heap BlockCache (LruBlockCache) Configuration Steps
Determine (or estimate) the proportions of reads and writes in your workload, and use these proportions to specify on-heap memory for BlockCache and MemStore.
The sum of the two allocations must be less than or equal to 0.8. The following table describes the two properties :
|
Property |
Default Value |
Description |
|
|
0.4 |
Proportion of maximum JVM heap size (Java |
|
|
0.4 |
Proportion of maximum JVM heap size (Java |
Use the following guidelines to determine the two proportions:
The default configuration for each property is 0.4, which configures BlockCache for a mixed workload with roughly equal proportions of random reads and writes.
If the amount of avaiable RAM in the off-heap cache is less than 20 GB, your workload is probably read-heavy. In this case, do not plan to configure off-heap cache, your amount of available RAM is less than 20 GB. In this case, increase the
hfile.block.cache.sizeproperty and decrease thehbase.regionserver.global.memstore.upperLimitproperty so that the values reflect your workload proportions. These adjustments optimize read performance.If your workload is write-heavy, decrease the
hfile.block.cache.sizeproperty and increase thehbase.regionserver.global.memstore.upperLimitproperty proportionally.As noted earlier, the sum of
hfile.block.cache.sizeandhbase.regionserver.global.memstore.upperLimitmust be less than or equal to 0.8 (80%) of the maximum Java heap size specified byHBASE_HEAPSIZE(-Xmx).If you allocate more than 0.8 across both caches, the HBase RegionServer process returns an error and does not start.
Do not set
hfile.block.cache.sizeto zero.At a minimum, specify a proportion that allocates enough space for HFile index blocks. To review index block sizes, use the RegionServer Web GUI for each server.
Edit the corresponding values in your hbase-site.xml files.
Here are the default definitions:
<property> <name>hfile.block.cache.size</name> <value>0.4</value> <description>Percentage of maximum heap (-Xmx setting) to allocate to block cache used by HFile/StoreFile. Default of 0.4 allocates 40%. </description> </property> <property> <name>hbase.regionserver.global.memstore.upperLimit</name> <value>0.4</value> <description>Maximum size of all memstores in a region server before new updates are blocked and flushes are forced. Defaults to 40% of heap. </description> </property>
If you have less than 20 GB of RAM for use by HBase, you are done with the configuration process. You should restart (or perform a rolling restart on) your cluster and check log files for error messages. If you have more than 20 GB of RAM for use by HBase, consider configuring the variables and properties described next.
Compressing BlockCache
BlockCache compression caches data and encoded data blocks in their on-disk formats, rather than decompressing and decrypting them before caching. When compression is enabled on a column family, more data can fit into the amount of memory dedicated to BlockCache. Decompression is repeated every time a block is accessed, but the increase in available cache space can have a positive impact on throughput and mean latency.
BlockCache compression is particularly useful when you have more data than RAM allocated to BlockCache, but your compressed data can fit into BlockCache. (The savings must be worth the increased garbage collection overhead and overall CPU load).
If your data can fit into block cache without compression, or if your workload is sensitive to extra CPU or garbage collection overhead, we recommend against enabling BlockCache compression.
Block cache compression is disabled by default.
![[Important]](../common/images/admon/important.png) | Important |
|---|---|
Before you can use BlockCache compression on an HBase table, compression must be enabled for the table. For more information, see Enable Compression on a ColumnFamily on the Apache website. |
To enable BlockCache compression, follow these steps:
Set the hbase.block.data.cachecompressed to
truein thehbase-site.xmlfile on each RegionServer.Restart or perform a rolling restart of your cluster.
Check logs for error messages.
Configuring Off-Heap Memory (BucketCache)
![[Note]](../common/images/admon/note.png) | Note |
|---|---|
Before configuring off-heap memory, complete the tasks in the previous "Configuring BlockCache" section. |
To prepare for BucketCache configuration, compare the figure and table below before proceeding to the "Configuring BucketCache" steps.
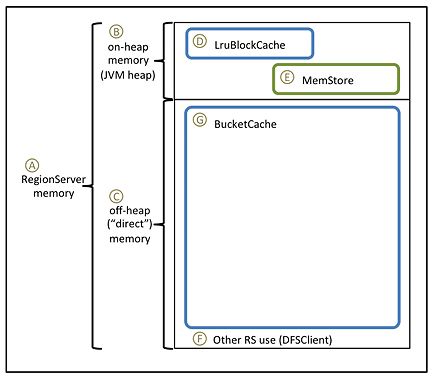
In the following table:
The first column refers to the elements in the figure.
The second column describes each element and, if applicable, its associated variable or property name.
The third column contains values and formulas.
The fourth column computes values based on the following sample configuration parameters:
128 GB for the RegionServer process (there is additional memory available for other HDP processes)
A workload of 75% reads, 25% writes
HBASE_HEAPSIZE= 20 GB (20480 MB)
| Note |
|---|---|
Most of the following values are specified in megabytes; three are proportions. |
|
Item |
Description |
Value or Formula |
Example |
|
A |
Total physical memory for RegionServer operations: on-heap plus off-heap ("direct") memory (MB) |
(hardware dependent) |
131072 |
|
B |
The This value was set when the BlockCache was configured. |
Recommendation: 20480 |
20480 |
|
C |
The -XX: MaxDirectMemorySize option:
Amount of off-heap ("direct")
memory to allocate to HBase (MB)
|
A - B |
131072 - 20480 = 110592 |
|
Dp |
The This value was set when the BlockCache was configured. |
(proportion of reads) * 0.8 |
0.75 * 0.8 = 0.6 |
|
Dm |
Maximum amount of JVM heap to allocate to BlockCache (MB) |
B * Dp |
20480 * 0.6 = 12288 |
|
Ep |
The |
0.8 - Dp |
0.8 - 0.6 = 0.2 |
|
F |
Amount of off-heap memory to reserve for other uses (DFSClient; MB) |
Recommendation: 1024 to 2048 |
2048 |
|
G |
Amount of off-heap memory to allocate to BucketCache (MB) |
C - F |
110592 - 2048 = 108544 |
|
The |
G |
108544 | |
|
The |
G / (Dm + G) |
108544 / 120832 = 0.89830508474576 |
Configuring BucketCache
To configure BucketCache:
In the
hbase-env.shfile for each RegionServer, or in thehbase-env.shfile supplied to Ambari, set the-XX:MaxDirectMemorySizeargument forHBASE_REGIONSERVER_OPTSto the amount of direct memory you want to allocate to HBase.In the sample configuration, the value would be
110592m(-XX:MaxDirectMemorySizeaccepts a number followed by a unit indicator;mindicates megabytes);HBASE_OPTS="$HBASE_OPTS -XX:MaxDirectMemorySize=110592m"In the
hbase-site.xmlfile, specify BucketCache size and percentage.For the sample configuration, the values would be
120832and0.89830508474576, respectively. You can round up the proportion. This allocates space related to the rounding error to the (larger) off-heap memory area.<property> <name>hbase.bucketcache.size</name> <value>108544</value> </property> <property> <name>hbase.bucketcache.percentage.in.combinedcache</name> <value>0.8984</value> </property>In the
hbase-site.xmlfile, sethbase.bucketcache.ioenginetooffheapto enable BucketCache:<property> <name>hbase.bucketcache.ioengine</name> <value>offheap</value> </property>
Restart (or perform a rolling restart on) the cluster.
It can take a minute or more to allocate BucketCache, depending on how much memory you are allocating. Check logs for error messages.
Importing Data into HBase with Bulk Load
Importing data with a bulk load operation bypasses the HBase API and writes content, properly formatted as HBase data files (HFiles), directly to the file system. Bulk load uses fewer CPU and network resources than using the HBase API for similar work.
| Note |
|---|---|
The following recommended bulk load procedure uses Apache HCatalog and Apache Pig. |
To bulk load data into HBase:
Prepare the input file, as shown in the following
data.tsvexample input file:row1 c1 c2 row2 c1 c2 row3 c1 c2 row4 c1 c2 row5 c1 c2 row6 c1 c2 row7 c1 c2 row8 c1 c2 row9 c1 c2 row10 c1 c2
Make the data available on the cluster, as shown in this continuation of the example:
hadoop fs -put data.tsv /tmp/
Define the HBase schema for the data, shown here as creating a script file called
simple.ddl, which contains the HBase schema fordata.tsv:CREATE TABLE simple_hcat_load_table (id STRING, c1 STRING, c2 STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ( 'hbase.columns.mapping' = 'd:c1,d:c2' ) TBLPROPERTIES ( 'hbase.table.name' = 'simple_hcat_load_table' );
Create and register the HBase table in HCatalog:
hcat -f simple.ddl
Create the import file.
The following example instructs Pig to load data from
data.tsvand store it insimple_hcat_load_table. For the purposes of this example, assume that you have saved the following statement in a file namedsimple.bulkload.pig.A = LOAD 'hdfs:///tmp/data.tsv' USING PigStorage('\t') AS (id:chararray, c1:chararray, c2:chararray); -- DUMP A; STORE A INTO 'simple_hcat_load_table' USING org.apache.hive.hcatalog.pig.HCatStorer();Note Modify the filenames and table schema for your environment.
Execute the following command on your HBase server machine. The command directs Pig to populate the HBase table by using HCatalog
bulkload.pig -useHCatalog simple.bulkload.pig
Using Snapshots
Prior to HBase 0.94.6, the only way to back up or clone a table was to use the CopyTable or ExportTable utility, or to copy all of the HFiles in HDFS after disabling the table. The disadvantage of these methods is that using the first might degrade RegionServer performance, and using the second requires you to disable the table, which means no reads or writes can occur.
HBase snapshot support enables you to take a snapshot of a table without much impact on RegionServers, because snapshot, clone, and restore operations do not involve data copying. In addition, exporting a snapshot to another cluster has no impact on RegionServers.
Configuring a Snapshot
Snapshots are enabled by default starting with HBase 0.95, To enable snapshot
support in HBase 0.94.6 up to HBase 0.95, set the hbase.snapshot.enabled
property to true. (Snapshots are enabled by default in 0.95+.)
<property> <name>hbase.snapshot.enabled</name> <value>true</value> </property>
Taking a Snapshot
As shown in the following example, start the HBase shell and clone the table:
$ hbase shell hbase> snapshot 'myTable', 'myTableSnapshot-122112'
Listing Snapshots
You can list and describe all snapshots taken as follows:
$ hbase shell hbase> list_snapshots
Deleting Snapshots
You can remove a snapshot, and the files associated with that snapshot will be removed if they are no longer needed.
$ hbase shell hbase> delete_snapshot 'myTableSnapshot-122112'
Cloning a Table from a Snapshot
From a snapshot you can create a new table (clone operation) that contains the same data as the original when the snapshot was taken. The clone operation does not involve data copies . A change to the cloned table does not impact the snapshot or the original table.
$ hbase shell hbase> clone_snapshot 'myTableSnapshot-122112', 'myNewTestTable'
Restoring a Snapshot
The restore operation requires the table to be disabled so that it can be restored to its state when the snapshot was taken, changing both data and schema, if required.
| Important |
|---|---|
Because replication works at the log level and snapshots work at the file system level, after a restore, the replicas will be in a different state than the master. If you want to use restore, you need to stop replication and redo the bootstrap. In case of partial data loss due to client issues, you can clone the table from the snapshot and use a MapReduce job to copy the data that you need from the clone to the main one (instead of performing a full restore, which requires the table to be disabled). |
The following is an example of commands for a restore operation:
$ hbase shell hbase> disable 'myTable' hbase> restore_snapshot 'myTableSnapshot-122112'
Snapshot Operations and ACLs
If you are using security with the AccessController coprocessor, only a global administrator can take, clone, or restore a snapshot. None of these actions capture ACL rights. Restoring a table preserves the ACL rights of the existing table, while cloning a table creates a new table that has no ACL rights until the administrator adds them.
Exporting to Another Cluster
The ExportSnapshot tool copies all the data related to a snapshot (HFiles, logs, and snapshot metadata) to another cluster. The tool executes a MapReduce job, similar to distcp, to copy files between the two clusters. Because it works at the file system level, the HBase cluster does not have to be online.
The HBase ExportSnapshot
tool must be run as user hbase. The HBase ExportSnapshot tool uses the temp directory specified
by hbase.tmp.dir (for
example,
/grid/0/var/log/hbase),
created on HDFS with user hbase as the owner.
For example, to copy a snapshot called MySnapshot to an HBase
cluster srv2 (hdfs://srv2:8020/hbase) using 16
mappers, input the following:
$ hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot MySnapshot -copy-to hdfs://yourserver:8020/hbase_root_dir -mappers 16