Flink resource management
As a cluster wide resource, the CRD is the blueprint of a deployment, it defines the schema of the Flink deployments. Custom resources are the core user facing APIs of the Flink Operator that determine the Flink Application and Session cluster deployment modes.
- Flink application managed by the FlinkDeployment resource
- Multiple jobs managed by the FlinkSessionJob resource sharing the same Flink "session", managed by the FlinkDeployment resource. The operations on the session jobs are independent of each other.
You can submit the FlinkDeployment and FlinkSessionJob
configurations as YAML files using kubectl. The resources can be used to
define, configure and manage the cluster and Flink application related resources. The Flink
Operator continuously checks cluster events relating to the custom resources. When a new
update is received for the custom resource, the Kubernetes cluster will be adjusted to reach
the desired state. The custom resources can be applied and reapplied on the cluster anytime as
the Flink Operator makes the adjustment based on the latest version.
The Flink Operator is responsible for managing the full production lifecycle of Flink resources. The following states can be identified for a Flink job resource:
CREATED: The resource is created in Kubernetes, but not yet handled by the Flink OperatorSUSPENDED: The Flink job resource is suspendedUPGRADING: The resource is suspended before upgrading to a new specDEPLOYED: The resource is deployed/submitted to Kubernetes, but not yet considered to be stable and might be rolled back in the futureSTABLE: The resource deployment is considered to be stable and will not be rolled backROLLING_BACK: The resource is being rolled back to the last stable specROLLED_BACK: The resource is deployed with the last stable specFAILED: The job terminally failed
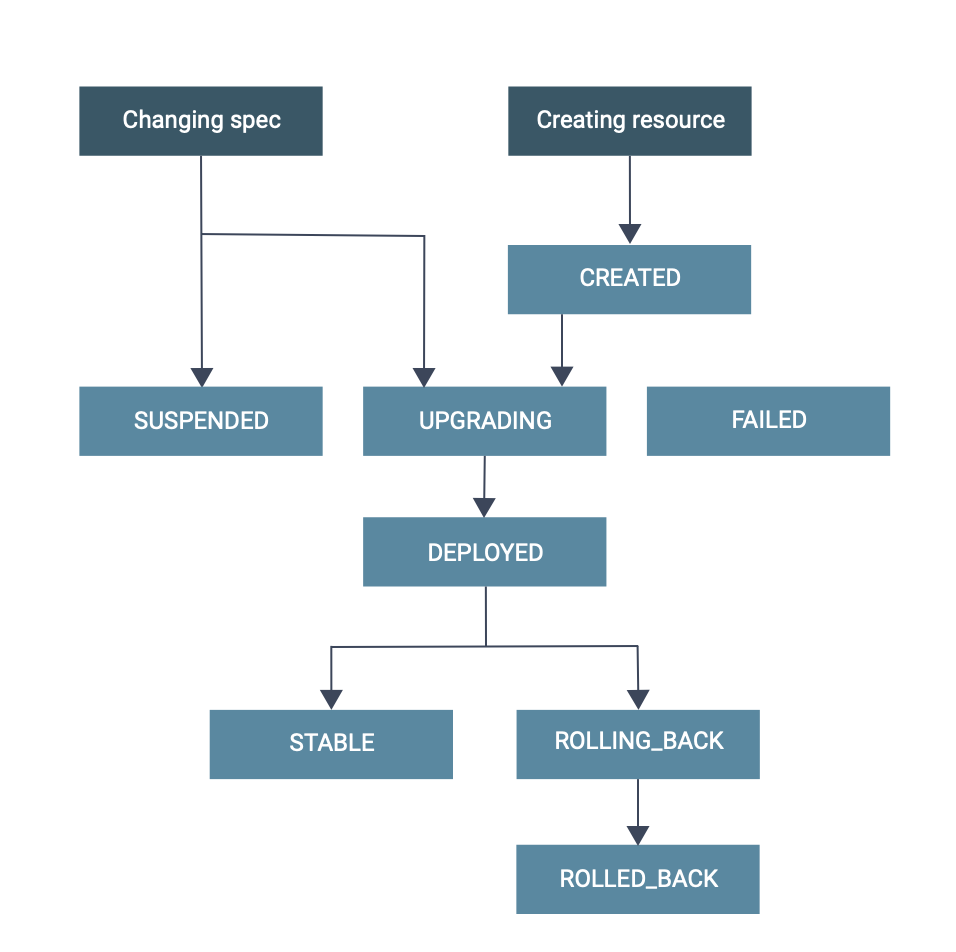
As the Flink Operator is responsible to manage the lifecycle of Flink applications, the
behavior of the Flink Operator is controlled by the respective configuration property of the
spec.job in the FlinkDeployment and
FlinkSessionJob resources.
In case the spec.job is not specified in the
FlinkDeployment, the Flink job will be deployed in a Session job.
Configuring the FlinkDeployment
Learn more about the FlinkDeployment.
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: namespace-of-my-deployment
name: my-deployment
spec:
// Deployment specs of your Flink Session/ApplicationThe apiVersion and kind properties have fixed values, while
metadata and spec can be configured to control the actual
Flink deployment.
kubectl get flinkdeployment my-deployment -o yamljobManagerDeploymentStatus
property:apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
...
spec:
...
status:
clusterInfo:
...
jobManagerDeploymentStatus: READY
jobStatus:
...
reconciliationStatus:
...
To create a session cluster, you need to leave spec.job empty. This will
result in an empty session cluster consisting only of JobManager(s), after which you can use
FlinkSessionJob resources to start jobs on these clusters.
The spec property is the most important part of the FlinkDeployment
resource, as it describes the desired Flink Application or Session cluster specifications. The
spec property contains all the information the Flink Operator needs to
deploy and manage your Flink deployments, which includes Docker images, configurations,
desired state and so on.
| Property | Description |
|---|---|
image |
The Docker image of Flink containing the JAR file of the Flink job. |
flinkVersion |
Flink version used in the Docker image, for example
v1_19. |
serviceAccount |
The Kubernetes service account of Flink that has all the permissions required
to create Flink applications inside the cluster. The default value is
flink. |
mode |
|
taskManager
|
Job and Task manager pod resource specifications (For example, CPU, memory, ephemeralStorage). |
flinkConfiguration |
List of Flink configuration overrides such as for high availability and checkpointing configurations. |
job |
Job specification for Application deployments. Leave it empty to create a session cluster. |
Configuring the FlinkSessionJob
Learn more about the FlinkSessionJob.
FlinkSessionJob resource has a similar structure to the
FlinkDeployment resource, as shown in the following
example:apiVersion: flink.apache.org/v1beta1
kind: FlinkSessionJob
metadata:
name: basic-session-job-example
spec:
deploymentName: basic-session-cluster
job:
jarURI: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.16.1/flink-examples-streaming_2.12-1.16.1-TopSpeedWindowing.jar
parallelism: 4
upgradeMode: statelessWhen using the FlinkSessionJob resource, the kind must be set
to FlinkSessionJob, and the name of the target session cluster must be added
to deploymentName. This target cluster must be a valid
FlinkDeployment resource that you have created previously with an empty
spec.job property. This will ensure that the Session deployment mode is
used and the job is submitted to the session cluster.
- Start session cluster(s)
- Monitor overall cluster health
- Stop and delete session cluster(s)
Using pluggable file systems for FlinkSessionJob resources
The FlinkSessionJob resource can leverage both locally mounted (local
storage and NFS/SAN storage) and pluggable file systems in the jarUri. In
case of a pluggable file system, the Flink Operator requires the appropriate file system
plugin to download the job JARs from the remote location and upload them to the running
JobManager.
FROM apache/flink-kubernetes-operator
ENV FLINK_PLUGINS_DIR=/opt/flink/plugins
COPY flink-hadoop-fs-1.18-SNAPSHOT.jar $FLINK_PLUGINS_DIR/hadoop-fs/flink-kubernetes-operator.postStart property when installing the CSA
Operator using Helm, which will download plugins required by the Flink Operator after it
starts:helm install {...} --set "flink-kubernetes-operator.postStart.exec.command={/bin/sh,-c,curl https://repo1.maven.org/maven2/org/apache/flink/flink-hadoop-fs/1.18.1/flink-hadoop-fs-1.18.1.jar -o /opt/flink/plugins/flink-hadoop-fs-1.18.1.jar}"The following pluggable files ystems are supported pluggable file systems:
- Amazon S3 object storage (flink-s3-fs-presto and flink-s3-fs-hadoop)
- Aliyun Object Storage Service (flink-oss-fs-hadoop)
- Azure Data Lake Store Gen2 (flink-azure-fs-hadoop)
- Azure Blob Storage (flink-azure-fs-hadoop)
- Google Cloud Storage (gcs-connector)
For using additional types of pluggable storage, see the File systems page.