Data Warehouse on AWS: Best Practices
- A SQL-based ETL/data engineering phase to prepare the data, typically using either Hive on MapReduce or Hive on Spark.
- A BI/SQL analytics phase, typically using Impala and possibly BI tools or SQL applications.
The first of these phases, the ETL or data engineering phase, should generally follow the best practices for data engineering workloads that are described in the previous section of this document, Data Engineering on AWS.
The section will concentrate on the second phase, the BI and SQL analytics phase. This is where reports, visualizations, or applications are produced for people to use in real time, requiring interactive response times and higher concurrency.
For most data warehouse workloads, greatest flexibility and lowest cost can be achieved using the default recommendations described below.
Basic Architectural Patterns
Cloudera recommends the following architectural patterns for three common types of data warehouse workloads:
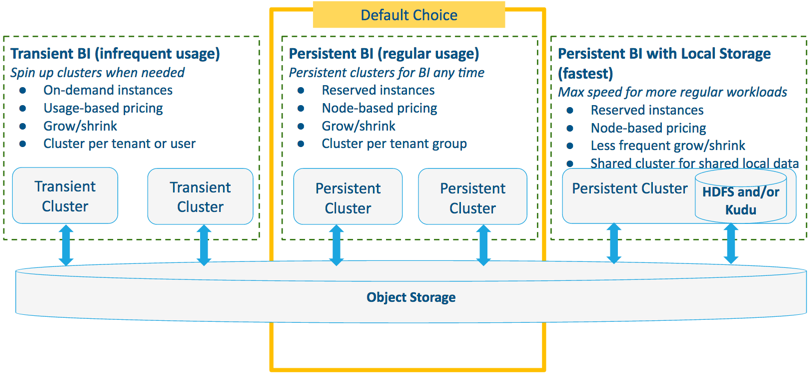
Choose one of these patterns, depending on your particular workloads, to ensure optimal price, performance, and convenience.
Pattern #1: Transient BI Workloads on Object Storage
For transient business intelligence (BI) workloads where there is infrequent usage, use on-demand instances, and spin up clusters when needed.
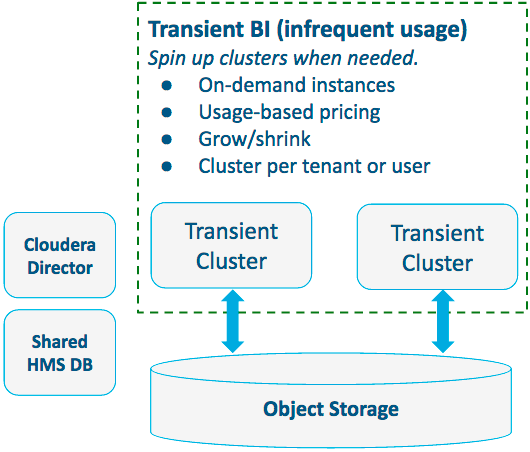
- You only spin up clusters as they are needed, and only pay only for the cloud resources you use
- You are able to select an instance type for each job, ensuring that jobs run on the most suitable hardware, with maximum efficiency
- Enables quick iteration with different instance types and settings
- Instances and software can be tailored to specific workloads
- Workloads run in complete isolation
- You can use spot instances for worker nodes, which lowers costs even further
- You can size your environment optimally, depending on the batch size
- You incur the cost of start and stop time for each cluster
- On-demand instances cost more per hour than long-running instances
- You cannot use Cloudera Navigator with transient instances, since instances are terminated when a job completes
- On-demand instances
- Usage-based pricing
- Grow and shrink clusters to minimize cost
- Cluster per tenant or user
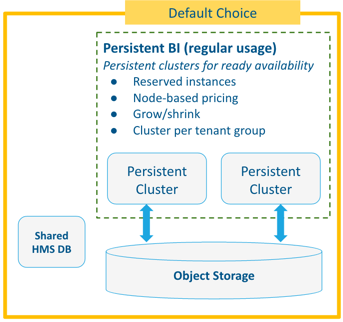
Pattern #2: Persistent BI on Object Storage
This pattern is usually the best choice when BI workloads run frequently but are flexible and changeable, and are not scheduled for fixed hours.
- Flexible and changing
- Frequent during most working days
- Not scheduled for fixed hours
- Predictable results are readily available
- Full multi-tenant isolation
- Common data can be placed in shared object storage
- Minimal cost can be achieved by growing and shrinking clusters as needed
- Per node performance is lower with S3 object storage. You can compensate for this by using more, cheaper nodes.
- Reserved instances
- Node-based pricing
- Grow and shrink clusters to minimize cost
- Cluster per tenant group (where a single cluster is shared by a group of tenants)
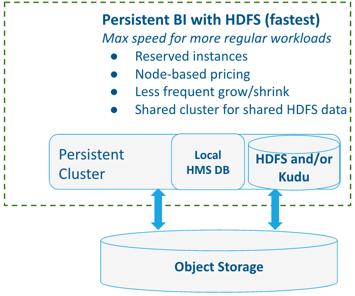
Pattern #3: Persistent BI with Locally-Attached Storage
To run frequent, regular BI workloads at maximum speed, Cloudera recommends using persistent clusters and local HDFS or Kudu storage.
- Regular and consistent
- Consistently querying common data
- Tight SLAs for performance
- Fast changing data (that needs Kudu)
- Running without object storage (eg. Azure, GCE)
- Faster performance per node on local data
- Ability to query object storage for rest of data
- Less elastic than object stored based clusters
- Less isolation for multi-tenant workloads using same HDFS data
- Cost if there are off-peak hours
- Use of reserved instances
- Node-based pricing
- Less frequent grow/shrink
- Shared cluster for shared local data
Typical Data Warehouse Scenario
- You have data stored in AWS S3 in an unprocessed, raw format.
- Users prepare their ETL tasks in a development environment using some sample of the raw data.
- Final ETL jobs go to a production environment where they are typically executed in recurring transient clusters (as described in the Data Engineering on AWS section).
- Processed data is often served for BI and SQL analytics in one the patterns above.
Basic Guidelines for BI in the Cloud
- Compute engine:
- Impala for most BI workloads
- See the section Data Engineering on AWS for SQL-based ETL via Hive and Hive-on-Spark
- Data Formats:
- Use Parquet, Snappy, and 256 MB blocks for best IO efficiency, especially on object storage
- Avoid small files for better performance, especially with object storage
- Metadata, including Hive Metastore Service (HMS):
- Use local RDBMS for clusters that use locally stored HDFS or Kudu data (as described in Pattern#3 above).
- Use a shared RDBMS for clusters that share common object store data (as described in Pattern #1 and
Pattern #2 above).
- For information on using a shared Amazon RDS as a metastore, see the Cloudera Engineering blog How To Set Up a Shared Amazon RDS as Your Hive Metastore
- Avoid sharing a RDBMS for non-data sharing clusters
- Deployment and Administration:
- Use either Cloudera Manager or Altus Director for persistent clusters. Cloudera recommends using Altus Director for persistent clusters that will grow and shrink. Use Altus Director 2.4 or higher for this because of enhanced interaction and synchronization between Altus Director and Cloudera Manager.
- Use Altus Director for transient clusters
- Deploy a network load balancer (NLB) for persistent clusters as usual, and only when needed for transience
- Monitor workloads with Cloudera Manager
- Security:
- Transient BI clusters: configure a VPC with strict security groups
- Persistent BI clusters: see Security Guidelines for BI in the Cloud below.
Security Guidelines for BI in the Cloud
- Identity:
- Tie the cluster to the corporate user directory (AD or LDAP) using Linux SSSD
- Authentication:
- Kerberos for internal CDH services
- AD (LDAP) for BI user/tools with Impala
- Authorization:
- Use Sentry for authorization per BI cluster (shared RDBMS with Sentry is not yet available)
- Encryption:
- With AWS, use SSE-S3 server-side encryption
- If you need HDFS-level encryption or keys outside AWS, then use Persisted Cluster with local storage using Cloudera Manager
Instance Recommendations
- For worker nodes, scale-up rather than out:
- Around 100 nodes for optimal performance
- If CPU constrained for cost efficiency
- Use EBS (st1) for spill to disk with r4 instances (size depends on usage)
- For CM master at >50 worker nodes:
- Add 2nd Cloudera Manager master for CM monitoring services
- Start with ~50 GB EBS (gp2) for CM
- For greater flexibility and cost savings, consider using common reserved instances for data engineering and data warehouse workloads.
| Type | AWS |
|---|---|
| Worker nodes | r4.2xlarge |
| Cloudera Manager master | m4.4xlarge |
| CDH masters | r4.4xlarge |
| Type | AWS | Azure | |
|---|---|---|---|
| Worker nodes | d2.4xlarge (reserved) | DS13v2 + P30 disks | n1-highmem -8 |
| Cloudera Manager master | m4.4xlarge | DS13v2 | n1-standard -16 |
| CDH masters | r4.4xlarge | DS14v2 | n1-highmem -16 |
Additional Suggestions
-
Be sure to use the same instance type for all worker nodes.
- Default scale-up choice for worker nodes: r4.4xlarge, then r4.8xlarge, and so on.
- If running with higher concurrency, use d2.8xlarge, DS14v2, or n1-highmem-16 instead for better concurrent performance.
- Cloudera recommends that you do not use d2.2xlarge instances. There is a risk of data loss with this instance type because AWS can put up to 4 nodes on the same host.
- If running Azure, set rack to equal fault domain to avoid data loss per Azure Guard Rails.
- Reserve pricing is typically expected for locally-attached storage clusters.
- With on-demand pricing, r4 instances coupled with st1 EBS storage is cheaper than the equivalent d2 instances.
- AWS EBS should use st1 disks for larger disks for best cost-performance and gp2 for smaller EBS volumes because:
- st1 provides 40 MB/s per TB provisioned up to 500 MB/s (eg 4 TB st1 volume = 160 MB/s)
- gp2 peaks at 160 MB/s
- gp2 provides better random IO which should be atypical for Impala workloads
- gp2 is over 2x the cost of st1