Data Engineering on AWS: Best Practices
For most data engineering and ETL workloads, best performance and lowest cost can be achieved using the default recommendations described below.
Basic Architectural Patterns
Cloudera recommends the following architectural patterns for three common types of data engineering workloads:

Choose one of these patterns, depending on your particular workloads, to ensure optimal price, performance, and convenience.
Pattern #1: Transient Batch Clusters on Object Storage
Use transient clusters and batch jobs to process data in object storage on demand.
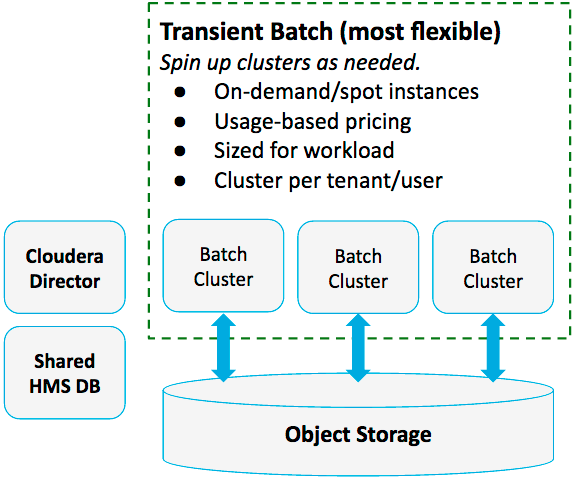
- You only spin up clusters as they are needed, and only pay for the cloud resources you use
- You are able to select an instance type for each job, ensuring that jobs run on the most suitable hardware, with maximum efficiency
- Enables quick iteration with different instance types and settings
- Instances and software can be tailored to specific workloads
- Workloads run in complete isolation
- You can use spot instances for worker nodes, which lowers costs even further
- You can size your environment optimally, depending on the batch size
- You incur the cost of start and stop time for each cluster
- On-demand instances cost more per hour than long-running instances
- You cannot use Cloudera Navigator with transient instances, since instances are terminated when a job completes
Pattern #2: Persistent Batch Clusters on Object Storage
Use persistent clusters to process data in object storage when your jobs are so frequent that you are able to keep a single cluster working for 50% or more of weekly hours with a series of separate jobs.
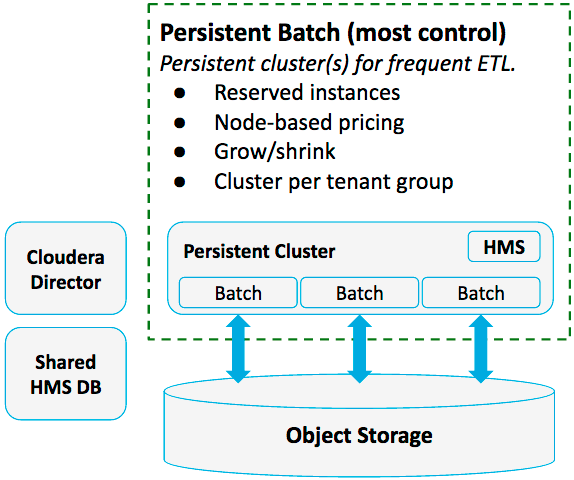
This pattern results in a lower cost per job, and works well for homogeneous jobs that can run efficiently with the same cluster setup, using the same hardware and software.
- No costly job time is spent in starting and stopping clusters
- You can use cheaper reserved instances to lower overall cost
- You can grow and shrink your clusters as needed, always maintaining the most cost-effective number of instances
- Cloudera Navigator is supported with Cloudera Enterprise 5.10 and higher
- Less workload isolation
- Less flexibility in terms of instance types and cluster settings
Pattern #3: Persistent Batch Clusters on Local Storage
Use persistent “lift and shift” clusters on data in local HDFS storage for maximum performance.
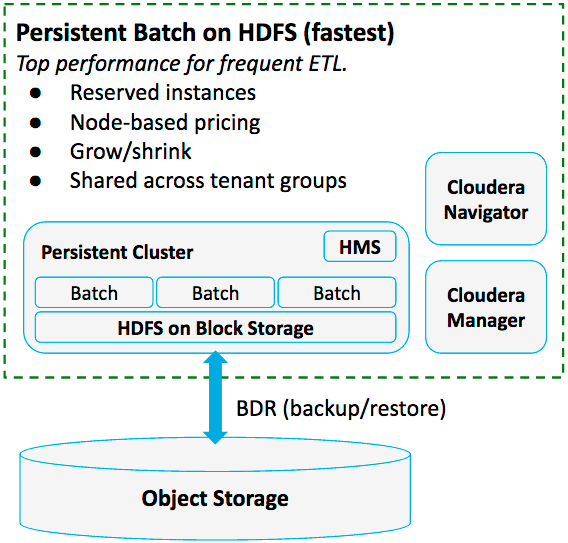
- Performance. When you have, for example, AWS workloads that run too slowly on object storage, or Azure workloads that are unsupported with object storage, use block storage with HDFS.
- Encryption. Cloudera Enterprise doesn’t support Amazon S3 client-side encryption. If you need to manage your own encryption keys, you should use HDFS and encrypt your data there.
- Efficiency. With lift-and-shift jobs, you may want to combine data engineering and data warehouse workloads in the same cluster. For more information, refer to Data Warehouse on AWS.
- No costly job time is spent in starting and stopping clusters
- You can use cheaper reserved instances to lower overall cost
- Faster performance per node on local data
- The full Cloudera Enterprise feature set is available, including encryption, lineage, and audit.
- Clusters are less elastic with HDFS than with object storage
- Less workload isolation
- Less flexibility in terms of instance types and cluster settings
Typical Data Engineering Scenario
- You have data stored in AWS S3 in an unprocessed, raw format.
- Data engineers prepare ETL queries in a development environment using some sample of the raw data.
- Final queries go to a production environment where they are executed in recurring transient clusters provisioned by Altus Director.
- Processed data is often read by a data warehouse.
Summary of Default Recommendations
- Altus Director: Use Altus Director to deploy Cloudera Manager and provision and scale CDH clusters.
- Transient clusters: Recommended for lowest cost if clusters will be busy less than 50% of the time.
- Master nodes:
- Place all master services on a single node, with Cloudera Manager on a separate node.
- Do not use spot instances for master nodes.
- Worker nodes:
- Use more nodes for better performance and maximum S3 bandwidth.
- For lower cost, use spot instances for worker nodes. Be aware that spot instances are less stable than on-demand instances. See Spot Instances in the AWS documentation for more information.
- Compute engines: MapReduce, Hive, Spark, Hive-on-Spark. Use Spark or Hive-on-Spark rather than MapReduce for faster execution.
- EC2 instance types: Use m4.2xlarge for workloads with a balance of compute and memory requirements.
- Use c4.2xlarge for compute-intensive workloads, such as parallel Monte Carlo simulations.
- Use r3.2xlarge or r4.2xlarge for memory-intensive workloads, such as large cached data structures.
- Storage: Use S3 for storage of input data and final output, and use HDFS for storage of intermediate data.
- Compress all data to improve performance.
- Avoid small files when defining your partitioning strategy.
- Use Parquet columnar data format on S3.
- Impala block size: 256 MB
- Change S3A to “fs.s3a.block.size” to match block size.
- Security: Launch the cluster in a VPC with strict security groups, as described in Cloudera Enterprise Reference Architecture for AWS Deployments (PDF).
Transient Clusters vs. Permanent Clusters
- On the cloud, you have a choice of transient or permanent clusters. Most batch ETL and data engineering workloads are transient: they are intended to prepare a set of data for some downstream use, and the clusters don't need to stay up 24x7. A transient cluster is launched to run a particular job and is terminated when the job is done. This results in a lower total cost of ownership (TCO), since you only pay for what you use in a cloud environment.
- Transient clusters have additional benefits over permanent clusters besides lowering your Amazon bill for EC2 compute hours. They offer maximum flexibility, enabling you to choose different cluster configurations for different jobs instead of running all jobs on the same permanent cluster with a particular configuration of hardware and a given set of CDH services. With transient clusters, you can experiment with different tools with lower risk and see which work best for your needs. You can also ensure that instance types are ideally suited for each job, depending on factors such as whether your workload is compute intensive or memory intensive.
- When a cluster running transient workloads is used on a very frequent basis, running ETL jobs 50% or more of total weekly hours, a permanent long-running cluster may be more cost effective than a series of transient clusters because it allows you to take advantage of EC2 Reserved Instance pricing instead of more expensive on-demand instances. For more information on EC2 Reserved Instances pricing see Amazon EC2 Reserved Instances Pricing.
Data Storage Considerations
Amazon S3 Object Storage
While not the highest performing storage option, Amazon S3 has considerable advantages, including low cost, fault tolerance, scalability, data persistence, as well as compatibility with other AWS services.
Processing data directly in S3, instead of relying on HDFS, for ETL workloads also increases flexibility by decoupling storage and compute. You can keep your data on S3, process or query it on a transient cluster with a variety of CDH tools, store the output data back on S3, and then access the data later for other purposes after terminating the cluster.
- It lowers costs by reducing local HDFS storage requirements.
- It avoids consistency problems with S3.
- If you store intermediate results in S3, that data is streamed between every worker node in the cluster and S3, significantly impacting performance.
Additional Suggestions
- For jobs where I/O is a bottleneck to performance:
- Preload data from S3 into HDFS if the data does not fit in memory thereby requiring multiple roundtrips to disk. This can speed things up whether HDFS is running on ephemeral disk or on EBS.
- Use gzip to reduce the size of input data.
- Consider using Snappy for data compression if your bottleneck is CPU-related.
- On S3, avoid over-partitioning at too fine a granularity, since small files are not handled efficiently on S3. S3 may limit performance if too many files are requested. For more information, see Request Rate and Performance Considerations in the AWS documentation.
- Use Cloudera Manager to monitor workloads. Use one instance of Altus Director per user or user group based on AWS resource permissions.
- A user group in this context means a set of users who have the same level of permissions to launch EC2 instances or create AWS resources.
- Deploy Altus Director on an instance with the right IAM role for that group.
- Copy all relevant cluster log files to S3 before destroying the cluster to enable debugging later.
- Use a single cluster to run multiple jobs if the jobs run continuously or as a dependent sequential pipeline, especially if cluster start/stop time exceeds job runtime.
- With applications that benefit from low network latency, high network throughput, or both, use placement groups to locate cluster instances close to each other. See Placement Groups in the AWS documentation for more information.
For Workloads Using Cloudera Navigator
- Use a persistent cluster.
- The cluster should be managed by Cloudera Manager.
- The cluster should use HDFS for storage.