Operational Database on AWS: Best Practices
- A dynamic data environment, with rapid read/writes/inserts/updates/deletes.
- An “always on” need for compute resources to meet real-time business demands.
- In most cases, requirement for the more performant EBS over the more cost-effective S3.
- Burst ETL to overcome data ingest bottlenecks.
- Rapid provisioning of new persistent clusters.
- Development and testing environments.
Typical Operational Database Scenario
- Applications/use cases require access to real-time data
- The underlying pool of structured/unstructured operational data is updated and appended to on an ongoing basis
- The current infrastructure environment was designed to have limited excess capacity to save on costs, but the business runs into short/medium-term scenarios where infrastructure needs outstrip capacity. Users want the flexibility to respond to business needs.
Basic Architectural Patterns
Cloudera recommends the following architectural patterns for three common types of data warehouse workloads:
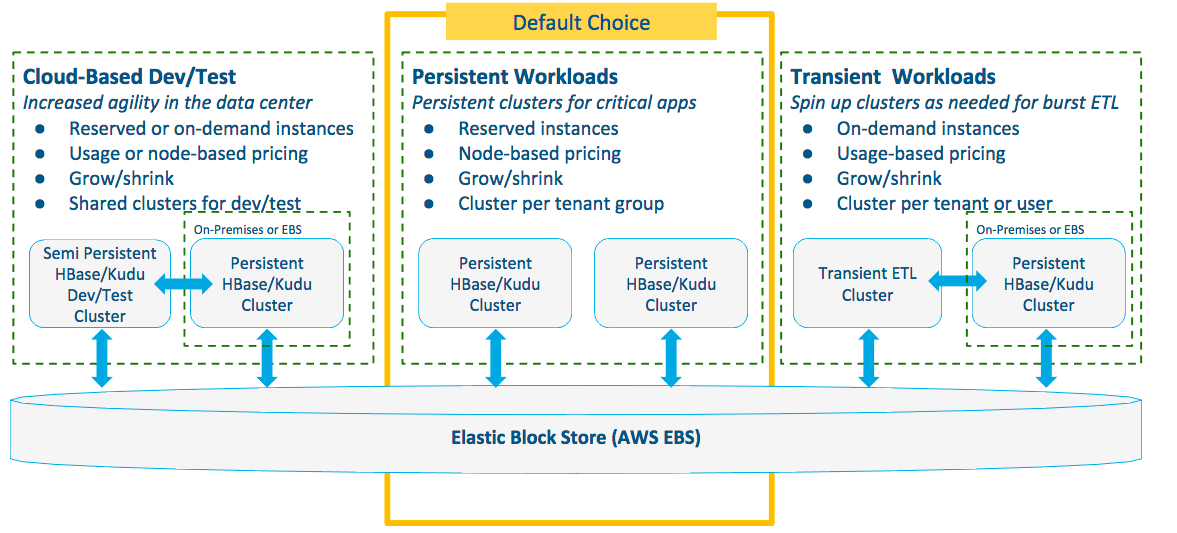
- Different use case requirements may lead to different choices.
- These options can be used for different use cases side-by-side.
- ETL systems run alongside the BI/Analytics use case, sharing a common data platform.
Pattern #1: Provisioning Cloud-based Dev and Test Environments
For provisioning development and testing environments.
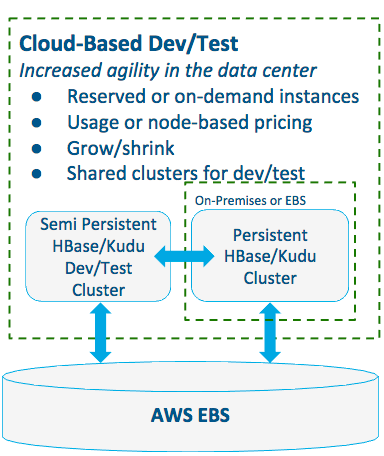
- Best when development and testing faces:
- Long wait periods for development and test environments
- Constraints with on-premises capacity for dev and testing
- Difficulty securing real data
- Benefits include:
- Smaller on-premises data center footprint
- Scale to exact needs of each dev/testing use case; no one-size-fits-all estimating of on-premises resources
- Decreased delay in dev and testing, which translates into increased time-to-value of any use case
- Production-level security means real data is used; real data in dev and testing results in easier production implementation later
- Tradeoffs:
- In the absence of a development and testing bottleneck, new organizational processes may be needed to determine which dev and test projects receive funding
Pattern #2: Persistent Workloads on Block Storage
For on-demand deployment of operational clusters.
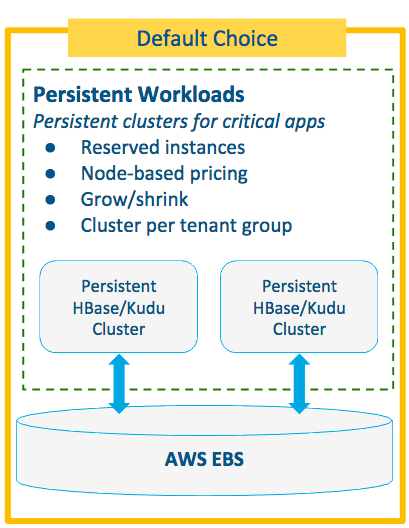
- Best when operational data ingest faces:
- Unexpected surges in traffic
- Regular batch jobs growing in size
- Batch import of net-new data set(s)
- Benefits include:
- Smaller on-premises or persistent cloud cluster footprint results in lower costs
- Tradeoffs:
- Increased complexity relative to carrying excess capacity on premises or in persistent cloud clusters, including:
- Scheduling of ETL process
- Delays in data inherent in burst ETL vs. streaming ETL
- Data movement between storage location/types
- Increased complexity relative to carrying excess capacity on premises or in persistent cloud clusters, including:
Pattern #3: Transient Clusters for Burst ETL
Leverage cloud elasticity to overcome ETL bottlenecks at low-cost.
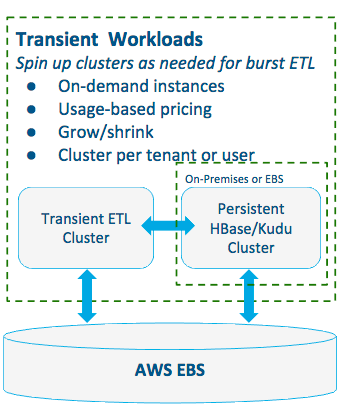
- Best when operational data ingest faces:
- Unexpected surges in traffic
- Regular batch jobs growing in size
- Batch import of net-new data set(s)
- Benefits include:
- Smaller on-premises or persistent cloud cluster footprint results in lower costs
- Tradeoffs:
- Increased complexity relative to carrying excess capacity on premises or in persistent cloud clusters, including:
- Scheduling of ETL process
- Delays in data inherent in burst ETL vs. streaming ETL
- Data movement between storage location/types
- Increased complexity relative to carrying excess capacity on premises or in persistent cloud clusters, including:
Storage and Ingestion
This section provides guidelines for storage and data ingestion for operational databases in the cloud.
Storage
- EBS, as opposed to S3, will provide the most performant and cost-efficient storage.
- Apache Kudu is recommended for use cases requiring real-time analytics.
- Apache HBase is recommended for use cases requiring wide tables and unstructured data.
Stream Processing/Data Ingestion
- Spark Streaming, running on a dedicated permanent cluster, is recommended for real-time processing and serving architectures. It should live in the same availability zone as the permanent operational database cluster. Spark Streaming will play a critical role when using Kudu’s relational structure.
- Apache Kafka can be used to land non-transformed data into the operational database via Apache Sqoop or Apache Flume.
Default Recommendations
This section provides default recommendations for three common types of operational database clusters.
Default recommendations for always-on clusters
Default recommendations for easy provisioning of always-on clusters. Snapshot backups are typically stored in S3.
Data Nodes
| Model | vCPU | Mem (GiB) | Storage (GB) |
|---|---|---|---|
| d2.xlarge | 4 | 30.5 | 3 x 2000 HDD |
| d2.2xlarge | 8 | 61 | 6 x 2000 HDD |
| d2.4xlarge | 16 | 122 | 12 x 2000 HDD |
| d2.8xlarge | 36 | 244 | 24 x 2000 HDD |
Smaller versions are recommended to stagger the impact of full block reports and garbage collection.
Master Nodes
| Model | vCPU | Mem (GiB) | Storage (GB) |
|---|---|---|---|
| c3.8xlarge | 32 | 60 | 2 x 320 SSD |
The master node memory should be sized inline with the cluster size, c3.xlarge supports very large cluster sizes but smaller master nodes are possible.
Default recommendations for transient clusters with permanent storage using Altus Director
Default recommendations for transient clusters with permanent storage using Altus Director:
Data Nodes
| Model | vCPU | Mem (GiB) | Storage |
|---|---|---|---|
| C4.large | 4 | 30.5 | EBS (4000 Mbps dedicated) |
Master Nodes:
| Model | vCPU | Mem (GiB) | Storage (GB) |
|---|---|---|---|
| c3.8xlarge | 32 | 60 | 2 x 320 SSD |
Storage, throughput workloads (ETL, etc.):
| Volume Type | Volume Size | IOPS | Throughput |
|---|---|---|---|
| st1 | 500 GiB - 16 TiB | 500 | 800 MiB/s |
Storage, real time workloads (HBase, etc.):
| Volume Type | Volume Size | IOPS | Throughput |
|---|---|---|---|
| io1 | 4 GiB - 16 TiB | 20,000 | 800 MiB/s |
Default recommendations for an always-on Spark streaming cluster
Spark clusters have homogenous nodes; there is no special master node. Default recommendations for an always-on Spark streaming cluster:
Default
Best balance of memory and compute.
| Model | vCPU | Mem (GiB) | Storage |
|---|---|---|---|
| m4.2xlarge | 8 | 32 | EBS (1000 Mbps dedicated) |
Memory-Intensive Workloads
Examples are workloads that cache RDDs/Dataframes or maintain in-memory state via the updateStateByKey(…) function.
| Model | vCPU | Mem (GiB) | Storage |
|---|---|---|---|
| m3.2xlarge | 8 | 61 | 160 GB SSD |
Compute-Intensive Workloads
Examples are workloads that may perform compute intensive machine learning operations to score incoming events.
| Model | vCPU | Mem (GiB) | Storage |
|---|---|---|---|
| c4.2xlarge | 8 | 15 | EBS (1000 Mbps dedicated) |