Cloudera Enterprise 5.x with EMC Isilon Scale-out Storage as DFS
Executive Summary
This document is a high-level design and best-practices guide for deploying Cloudera Enterprise Distribution on bare-metal infrastructure with EMC’s Isilon scale-out NAS solution as a shared storage backend.
Audience and Scope
This guide is for IT architects who are responsible for the design and deployment of infrastructure and a shared storage platform in the data center, as well as for Hadoop administrators and architects who will be data center architects or engineers and/or collaborate with specialists in that space.
This document describes Cloudera recommendations on the following topics:
- Storage array considerations
- Data network considerations
- Hardware/platform considerations
Glossary of Terms
| Term | Description |
| DataNode | Worker nodes of the cluster to which the HDFS data is written. |
| HBA | Host bus adapter. An I/O controller that is used to interface a host with storage devices. |
| HDD | Hard disk drive. |
| HDFS | Hadoop Distributed File System. |
| High Availability |
Configuration that addresses availability issues in a cluster. In a standard configuration, the NameNode is a single point of failure (SPOF). Each cluster has a single NameNode, and if that machine or process became unavailable, the cluster as a whole is unavailable until the NameNode is either restarted or brought up on a new host. The secondary NameNode does not provide failover capability. High availability enables running two NameNodes in the same cluster: the active NameNode and the standby NameNode. The standby NameNode allows a fast failover to a new NameNode in case of machine crash or planned maintenance. |
| ISL | Inter-switch Link |
| JBOD | Just a Bunch of Disks (this is in contrast to Disks configured via software or hardware with redundancy mechanisms for data protection) |
| Job History Server | Process that archives job metrics and metadata. One per cluster. |
| NameNode | The metadata master of HDFS essential for the integrity and proper functioning of the distributed filesystem. |
| NIC | Network interface card. |
| NodeManager | The process that starts application processes and manages resources on the DataNodes. |
| PDU | Power distribution unit. |
|
QJM |
Quorum Journal Manager. Provides a fencing mechanism for high availability in a Hadoop cluster. This service is used to distribute HDFS edit logs to multiple hosts (at least three are required) from the active NameNode. The standby NameNode reads the edits from the JournalNodes and constantly applies them to its own namespace. In case of a failover, the standby NameNode applies all of the edits from the JournalNodes before promoting itself to the active state. |
| QJN | Quorum JournalNodes. Nodes on which the journal services are installed. |
| RM | ResourceManager. The resource management component of YARN. This initiates application startup and controls scheduling on the DataNodes of the cluster (one instance per cluster). |
| ToR | Top of rack. |
| ZK | Zookeeper. A centralized service for maintaining configuration information, naming, and providing distributed synchronization and group services. |
Isilon Distributed Storage Array for HDFS and Bare-metal Nodes as Compute Nodes
In this model Isilon replaces HDFS shipped in Cloudera Enterprise.
In this architecture, Isilon acts as the HDFS/storage layer and the bare-metal nodes only provide the compute resources needed.
Considerations for a storage component are not required, but care has to be taken to ensure reasonable over-subscription ratio between Isilon switches and the compute node switches.
Physical Cluster Topology
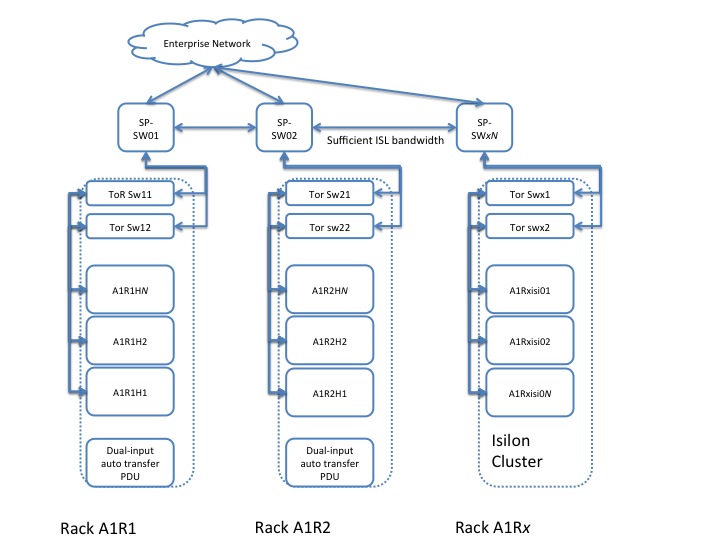
NOTE: Here SP-SW stands for Spine Switch and ToR stands for Top of Rack
Physical Cluster Component List
| Component | Configuration | Description | Quantity |
| Physical servers | Two-socket, 6-10 cores per socket > 2 GHz; minimally 256GB RAM. | Hosts that house the various NodeManager and compute instances. | Minimum 3 master + 5 compute (8 nodes) |
| NICs |
Dual-port 10 Gbps Ethernet NICs. The connector type depends on the network design; could be SFP+ or Twinax. |
Provide the data network services | At least two per server. |
| Internal HDDs | Standard OS sizes - 300 - 1TB drives. Can be larger but not necessary. | These ensure continuity of service on server resets. | Two per physical server configured as a RAID-1 volume (mirrored). |
| Ethernet ToR/leaf switches | Minimally 10 Gbps switches with sufficient port density to accommodate the compute cluster. These require enough ports to create a realistic spine-leaf topology providing ISL bandwidth above a 1:4 oversubscription ratio (preferably 1:1). | Although most enterprises have mature data network practices, consider building a dedicated data network for the Hadoop cluster. | At least two per rack. |
| Ethernet spine switches | Minimally 10 Gbps switches with sufficient port density to accommodate incoming ISL links and ensure required throughput over the spine (for inter-rack traffic). | Same considerations as for ToR switches. | Depends on the number of racks. |
Logical Cluster Topology
For the YARN NodeManager instances, data protection at the HDFS level is not required, because the physical nodes are running only the compute part of the cluster.
The minimum requirements to build out the cluster are:
- Three Master Nodes
- Five Compute nodes
The following table identifies service roles for different node types.
| Master Node | Master Node | Master Node | YARN NodeManager nodes 1..n | |
| ZooKeeper | ZooKeeper | ZooKeeper | ZooKeeper | |
| YARN | ResourceManager | ResourceManager | History Server | NodeManager |
| Hive | MetaStore, WebHCat, HiveServer2 | |||
| Management( misc) | Cloudera Agent | Cloudera Agent | Cloudera Agent, Oozie, Cloudera Manager, Management Services | Cloudera Agent |
| Navigator | Navigator, Key Management Services | |||
| HUE | HUE | |||
| HBASE | HMaster | HMaster | HMaster | RegionServer |
| Impala | StateStore, Catalog | Impala Daemon |
NOTE: Low-latency workloads are subject to network latency, because all data traffic between compute nodes and HDFS (Isilon-based) is north-south traffic.
The following table provides size recommendations for the Physical nodes.
| Component | Configuration | Description | Quantity |
|
Master Nodes: two-socket with 6-10 cores/socket > 2GHz; minimally 128 GB RAM; 8-10 disks |
2RU 2-socket nodes with at least 256 GB RAM | These nodes house the Cloudera Master services and serve as the gateway/edge device that connects the rest of the customer’s network to the Cloudera cluster. | Three (for scaling up to 100 cluster nodes). |
|
compute instances: two-socket with 6-10 cores/socket > 2GHz; minimally 256 GB RAM 2 x OS disks, 8 SATA or SAS drives or 2x SSDs |
Have at least 8 SATA or SAS Drives, or 2 SSD drives for intermediate storage. |
These nodes will house the YARN node managers, as well as additional required services. |
Results in the field shows that 1:2 ratio of Isilon nodes to compute nodes is reasonable for most use cases. In case of Heavy Impala workloads, use 1:1.5 ratio. So if Isilon has 5 nodes, have 8 compute nodes. |
The following table provides recommendations for storage allocation.
| Node/Role | Disk Layout | Description |
| Management/Master |
|
Avoid fracturing the filesystem layout into multiple smaller filesystems. Instead, keep a separate “/” and “/var”. |
| Compute nodes |
|
Avoid fracturing the filesystem layout into multiple smaller filesystems. Instead, keep a separate “/” and “/var”. For example, for 10 TB of total storage in Isilon, 2 TB is needed for intermediate storage. Having more or faster local spindles will speed up the intermediate shuffle stage of MapReduce. |
Supportability/Compatibility Matrix
| CDH | CM | OneFS | Supported |
|
5.4.4 and higher (HDFS 2.6) |
5.4 | 7.2.x.x | All services except Navigator* |
*Navigator support is contingent on iNotify and fsmanage functionality being added into OneFS.
Environment sizing and Platform Tuning Considerations
The throughput consideration of an Isilon cluster is predicated upon the type of nodes being used (for instance X-series or S-series). Typically the X-series provides the best balance between capacity and performance, and each X-series node is capable of roughly 900MB/s of Read and 500MB/s of Write throughput.
What that implies is that to get an aggregate Write throughput of 3GB/s, we would need roughly 6 nodes. These 6 nodes can then provide ~ 4.8GB/s Read throughput. What this also implies is that there needs to be adequate network bandwidth to handle 4.8GB/s throughput (~ 40gbps). This also implies that the compute nodes should be able to drive this volume of throughput.
Assuming that each CPU core on the compute node can drive ~ 50MB/s, we would need ~ 100 cores to drive this. If we are using 10-core sockets, we would need 10 such sockets. In other words, we would need 5 2-socket 2 RU hosts to drive this volume of throughput.
The throughput capabilities on a per core basis can be evaluated by running a stress tool/benchmark tool such as teragen (write throughput). If we find that we are not able to get close to 50MB/s per core throughput, the number of nodes needed to drive the throughput will of course change.
Similarly, needing additional throughput in the backend will require adding more nodes in the storage backend.
| Isilon Model | Description | Per Node Read Throughput (MB/s) | Per Node Write Throughput (MB/s) |
| S-series | S-210 is a high performance platform, with SSD based acceleration. It has 18-24 spindles per node, including up to 6 SSDs, and up to 256GB RAM | TBD | TBD |
| X-series | Available models are X-210 and X-410. Typically X-410 is the platform of choice for Hadoop. The X-410 has 30-36 spindles per node, with up to 6 SSD drives and up to 256GB RAM. The X-210 comes with 6-12 drives and up to 6 SSDs. It is limited to only up to 48GB of RAM per node. | TBD | TBD |
| NL-series | The NL series is ideal for active archiving | N/A | N/A |
| HD-series | This platform is high density and ideal for deep archival | N/A | N/A |
Platform Tuning Recommendations
NOTE: In this section, there are generic recommendations, but they should be applied only after sufficient testing.
CPU
CPU BIOS Settings
In your compute nodes’ BIOS, set CPU to Performance mode for best performance.
CPUfreq Governor
Following CPUfreq governor types are available in RHEL 6 (check other OS-specific governors if you are not using CentOS or RHEL 6) –
| Governor Type | Description |
| cpufreq_performance | Forces the CPU to use the highest possible clock frequency. It is meant for heavy workloads. This is best fit for interactive workloads. |
| Cpufreq_powersave | Forces the CPU to stay at the lowest clock frequency possible. |
| Cpufreq_ondemand | This allows CPU frequency to scale to maximum under heavy load, but drops down to lowest frequency under light or no load. This is the ideal governor and subject to appropriate testing, and can be used (as it will reduce power consumption under low load/idle conditions) |
| Cpufreq_userspace | This allows userspace programs to set the frequency. This is used in conjunction with the cpuspeed daemon. |
| Cpufreq_conservative | Similar to the cpufreq_ondemand but it switches frequencies more gradually |
Find the appropriate kernel modules for available on the system. And then use modprobe to add the driver needed.
# modprobe cpufreq_performance
Once a particular governor is loaded into the kernel, it can be enabled by using –
# cpupower frequency-set –governor cpufreq_performance
The available drivers can be found in the /lib/modules/<kernel version>/kernel/arch/<architecture>/kernel/cpu/cpufreq/ directory
/lib/modules/2.6.32-358.14.1.el6.centos.plus.x86_64/kernel/arch/x86/kernel/cpu/cpufreq
[root@ip-10-5-152-126 cpufreq]# ls
acpi-cpufreq.ko mperf.ko p4-clockmod.ko pcc-cpufreq.ko powernow-k8.ko speedstep-lib.ko
[root@ip-10-5-152-126 cpufreq]#
If the necessary cpufreq drivers are not available, you can get them from the /lib/modules/<kernel version>/kernel/drivers/cpufreq –
[root@ip-10-5-152-126 cpufreq]# cd /lib/modules/2.6.32-358.14.1.el6.centos.plus.x86_64/kernel/drivers/cpufreq
[root@ip-10-5-152-126 cpufreq]# ls
cpufreq_conservative.ko cpufreq_ondemand.ko cpufreq_powersave.ko cpufreq_stats.ko freq_table.ko
[root@ip-10-5-152-126 cpufreq]#
NOTE: The “uname –r” command will give you the kernel version.
The “cpupower” utility is provided by the cpupowerutils package.
If you don’t have it installed, you can set the tunables in /sys/devices/system/cpu/<cpu id>/cpufreq/
Memory
Minimize anonymous page faults
Minimize anonymous page faults by setting vm.swappiness = 1 , thereby freeing from page cache before “Swapping” application pages (this reduces the OOM-killer invocation)
Edit /etc/sysctl.conf in editor of choice and add following line –
vm.swappiness=1
After that, run –
# sysctl –p # sysctl –a|grep "vm.swappiness"
Disable transparent huge-page compaction
echo "never" > /sys/kernel/mm/redhat_transparent_hugepage/enabled[
Disable transparent huge-page defragmentation
echo "never" > /sys/kernel/mm/redhat_transparent_hugepage/defrag
Add these commands to /etc/rc.local to ensure that transparent hugepage compaction and defragmentation remain disabled across reboots.
Network
Following parameters are to be added in /etc/sysctl.conf
Disable TCP timestamps to improve CPU utilization (this is an optional parameter and will depend on your NIC vendor) –
net.ipv4.tcp_timestamps=0
Enable TCP sacks to improve throughput –
net.ipv4.tcp_sack=1
Increase the maximum length of processor input queues –
net.core.netdev_max_backlog=250000
Increase the TCP max and default buffer sizes using setsockopt() –
net.core.rmem_max=4194304 net.core.wmem_max=4194304 net.core.rmem_default=4194304 net.core_wmem_default=4194304 net.core.optmem_max=4194304
Increase memory thresholds to prevent packet dropping –
net.ipv4.tcp_rmem="4096 87380 4194304" net.ipv4.tcp_wmem="4096 65536 4194304"
Set the socket buffer to be divided evenly between TCP window size and application buffer –
net.ipv4.tcp_adv_win_scale=1
Verify NIC advanced features
Check what features are available with your NIC by using “ethtool” –
$ sudo ethtool -k Features for eth0: rx-checksumming: on tx-checksumming: off scatter-gather: off tcp-segmentation-offload: off udp-fragmentation-offload: off generic-segmentation-offload: off generic-receive-offload: on large-receive-offload: off rx-vlan-offload: on tx-vlan-offload: on ntuple-filters: off receive-hashing: off
There are various offload capabilities modern NICs (and especially high-performance NICs) have and it is always recommended to enable them.
A few features such as tcp-segmentation-offload (TSO), scatter-gather (SG) and generic-segmentation-offload (GSO) are usually good features to enable (if not enabled by default).
NIC ring buffer configurations
Check existing ring buffer sizes by running
$ ethtool -g eth0 Ring parameters for eth0: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 256 RX Mini: 0 RX Jumbo: 0 TX: 256
After checking the pre-set maximum values, and the current hardware settings, the following command can be used to resize the ring buffers –
# ethtool –G <interface> rx <newsize>
or
# ethtool –G <interface> tx <newsize>
NOTE: The ring buffer sizes will depend on the network topology to a certain degree and might need to be tuned depending on the nature of the workload. We have seen for 10G NICs, setting the RX and TX buffers to maximum is reasonable. This will of course have to be tuned based on the network architecture and type of traffic.
Storage
Disk/FS mount options
Disable “atime” from the data disks (and root fs for that matter) - use “noatime” option during mounting the FS
In the /etc/fstab file ensure that the appropriate filesystems have the “noatime” mount option specified -
LABEL=ROOT / ext4 noatime 0 0
FS Creation Options
FS creation - enable journal mode, reduce superuser block reservation from 5% to 1% for root (using the -m1 option), the sparse_super,dir_index,extent options (minimize number of super block backups and use b-tree indexes for directory trees, extent based allocations)
# mkfs –t ext4 –m1 –O sparse_super,dir_index,extent,has_journal /dev/sdb1
Cloudera Software stack
Guidelines for installing the Cloudera stack on this platform are nearly identical to those for Direct attached storage. This is addressed in various documents on Cloudera’s website.
To configure the Isilon service (instead of HDFS), follow the instructions here -- Managing Isilon.
