Configuring and running Data Lake backups
The Data Lake provides a command line interface for managing Data Lake backup and restore operations. The system checks to make sure there isn't another backup or restore in progress.
Configure the backup
- Create the S3, ABFS, or GCS backup location before performing the backup. For Azure, the container where the backup is stored should be in the same storage account as the Data Lake being backed up.
- Shut down principal services (see Principal services). This will help avoid mismatches between Data Lake metadata and data used by workloads and mismatches among the metadata stored in the Data Lake.
- Stop all Cloudera Data Hub clusters attached to the Data Lake before you perform any backup or restore operations.
- Stop any Virtual Warehouses that are running.
Configuring backups for AWS:
- Apply the IAM policy for Data Lake backup to the following roles:
- DATALAKE_ADMIN_ROLE
- RANGER_AUDIT_ROLE
For more informaiton on IAM roles, see Minimal setup for cloud storage.
In the IAM policy for Data Lake backup, be sure to replace the <BACKUP_BUCKET> variable with the backup location used.
Note that if you plan to restore the Data Lake backup that you are taking, you must also apply a restore policy to certain roles. For more information on restore see Configuring and running Data Lake restore.
Configuring RAZ for backup
This section applies only to RAZ-enabled AWS Data Lakes. For RAZ-enabled Azure Data Lakes, see the section below.
Add a RAZ policy to allow the backups to be written to and read from the backup location.
- Open the Ranger UI.
- Go to the cm_s3 policy list.
- Add a new policy:
- Policy name: backup_policy
- S3 bucket: The bucket where backups will be stored
- Path: The path(s) in the bucket where backup will be written
Note: If more than one bucket will be used for backup, create a separate policy for each bucket.
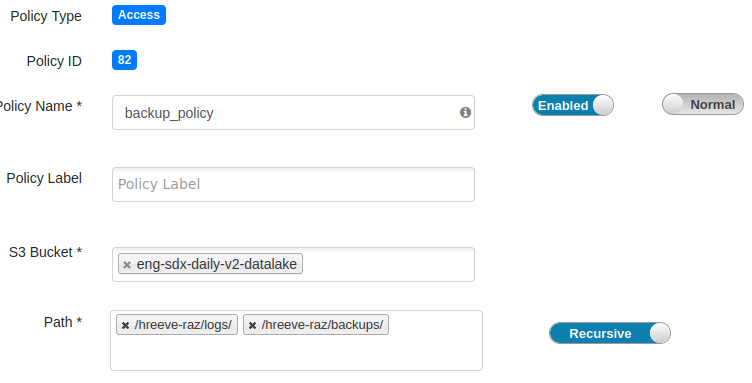
- Add read and write permissions for the
atlas, hbase, hdfs, andsolrusers under “Allow Conditions.”
Configuring backups for Azure:
- Verify that the following identities have the "Storage Blob Data Contributor"
role on the container where the backup is stored:
- Data Lake Admin identity
- Ranger Audit Logger identity
Configuring RAZ for backup
This section applies only to RAZ-enabled Azure Data Lakes. For RAZ-enabled AWS Data Lakes, see the section above.
Add a RAZ policy to allow the backups to be written to and read from the backup location.
- Open the Ranger UI.
- Go to the cm_adls policy list.
- Add a new policy:
- Policy name: backup_policy
- Storage Account: The storage account where backups will be stored
- Storage Account Container: The container where backups will be stored
- Path: The path(s) in the bucket where backup will be writtenNote: If more than one storage account or container will be used for backup, create a separate policy for each account/container.
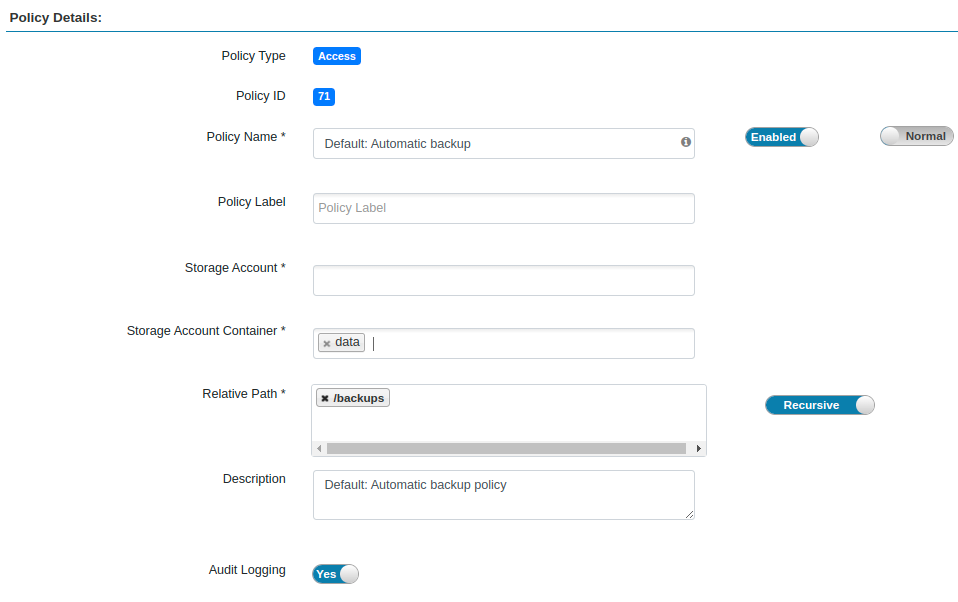
- Add read, write, list, delete, delete recursive, and move permissions for the
atlas, hbase, hdfs, andsolrusers under “Allow Conditions."
Configuring backups for GCP:
- resourcemanager.projects.get
- resourcemanager.projects.list
- storage.buckets.get
- storage.objects.create
- storage.objects.delete
- storage.objects.get
- storage.objects.getIamPolicy
- storage.objects.list
- storage.objects.setIamPolicy
- storage.objects.update
Note that the Ranger Audit service account permissions listed above should be granted to a custom role, not the default Storage Object Admin role.
You should also modify the scope of the Data Lake Admin and Ranger Audit service accounts to include the Backups bucket, if the bucket is different from the main data storage bucket. For more information see Minimum setup for cloud storage.
Run the backup
Checking the status of a Data Lake backup.