Understanding Data Pipelines
A data pipeline consists of a dataset and processing that acts on the dataset across your HDFS cluster.
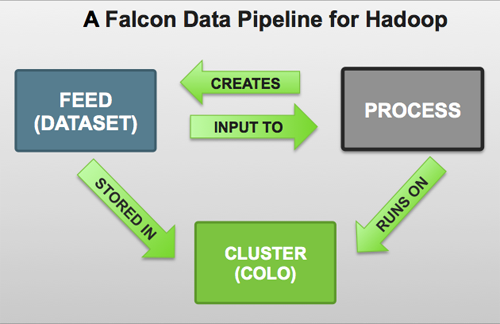
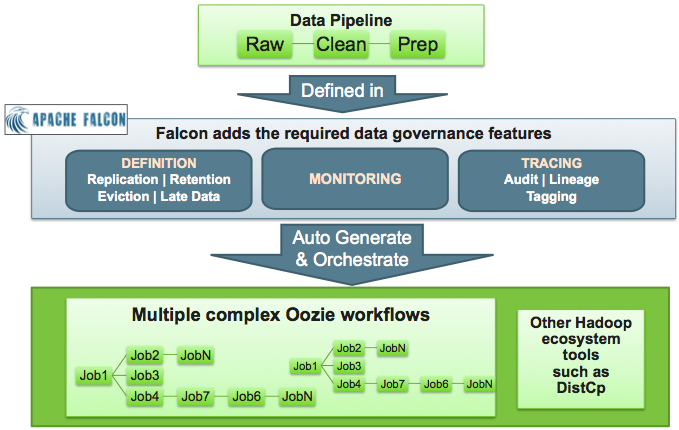
Each pipeline consists of XML pipeline specifications, called entities. These entities act together to provide a dynamic flow of information to load, clean, and process data.
There are three types of entities:
Cluster: Defines where data and processes are stored.
Feed: Defines the datasets to be cleaned and processed.
Process: Consumes feeds, invokes processing logic, and produces further feeds. A process defines the configuration of the Oozie workflow and defines when and how often the workflow should run. Also allows for late data handling.
Each entity is defined separately and then linked together to form a data pipeline. Falcon provides predefined policies for data replication, retention, late data handling, and replication. These sample policies are easily customized to suit your needs.
These entities can be reused many times to define data management policies for Oozie jobs, Pig scripts, and Hive queries. For example, Falcon data management policies become Oozie coordinator jobs: