You can update your existing CDP Private Cloud Data Services
1.3.4 or 1.4.0-H1 to 1.4.1 without requiring an uninstall.
Upgrading the Embedded Container Service (ECS) version while CDE service is enabled,
can cause Control Pane upgrade looping forever in error state. You must back up CDE jobs in
the CDE virtual cluster, and then delete the CDE service and CDE virtual cluster. Restore it
after the upgrade. For more information about backup and restore CDE jobs, see
Backing up and restoring CDE jobs.
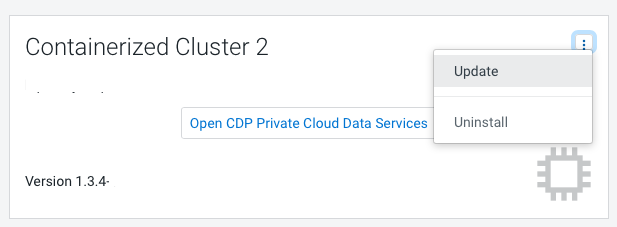
In Cloudera Manager, navigate to CDP Private Cloud Data Services
and click . Click
Update.
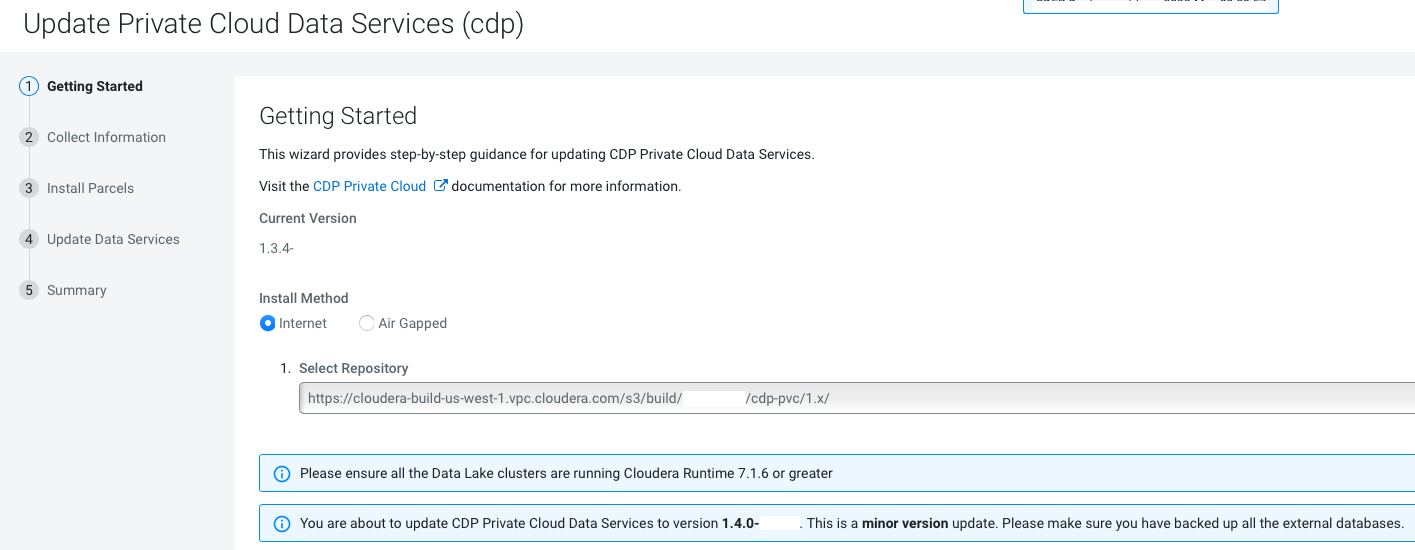
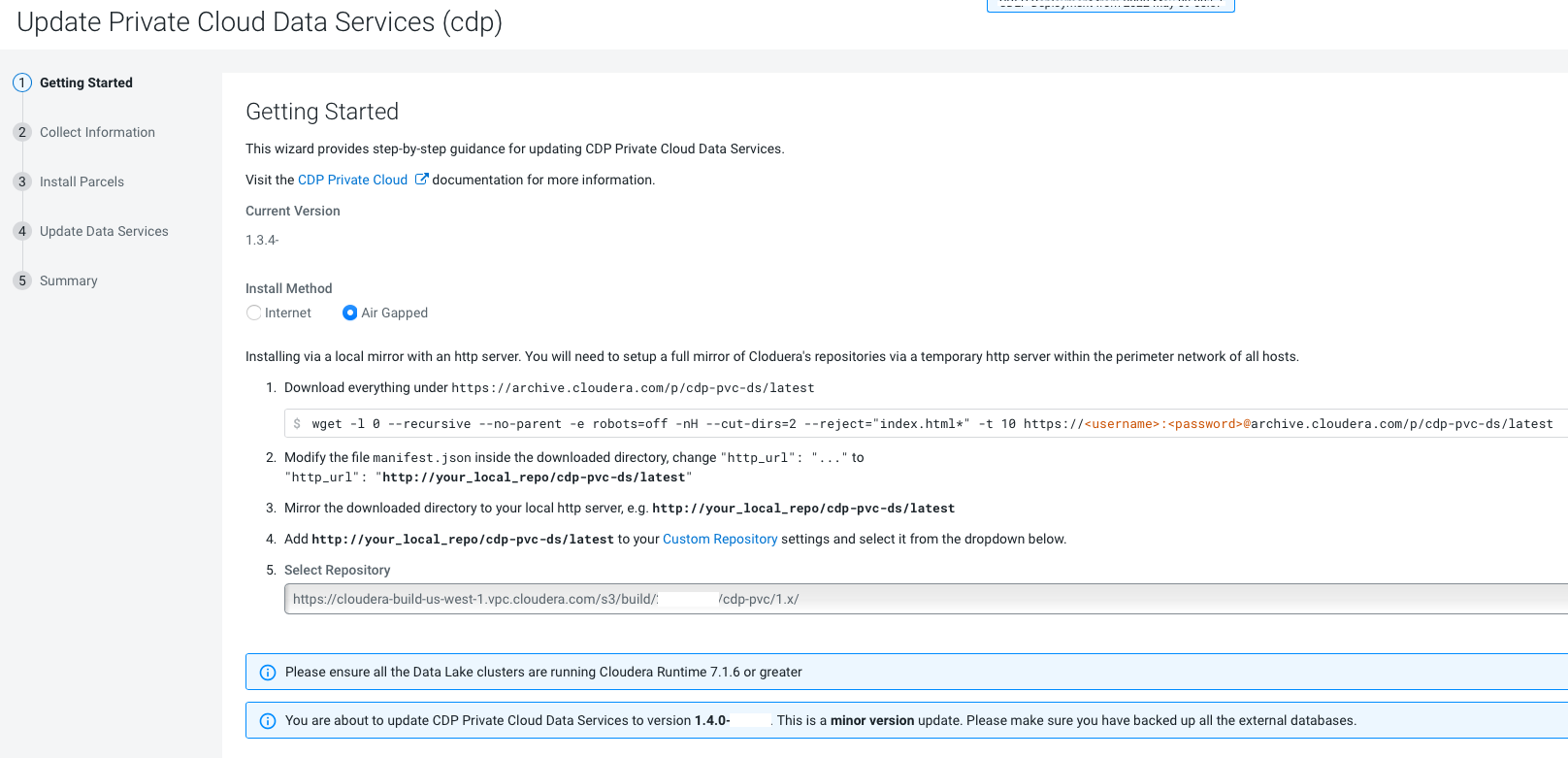
On the Getting Started page, you can select the Install
method - Air Gapped or Internet
and proceed.
Internet install method
Air Gapped install method
Click Continue.
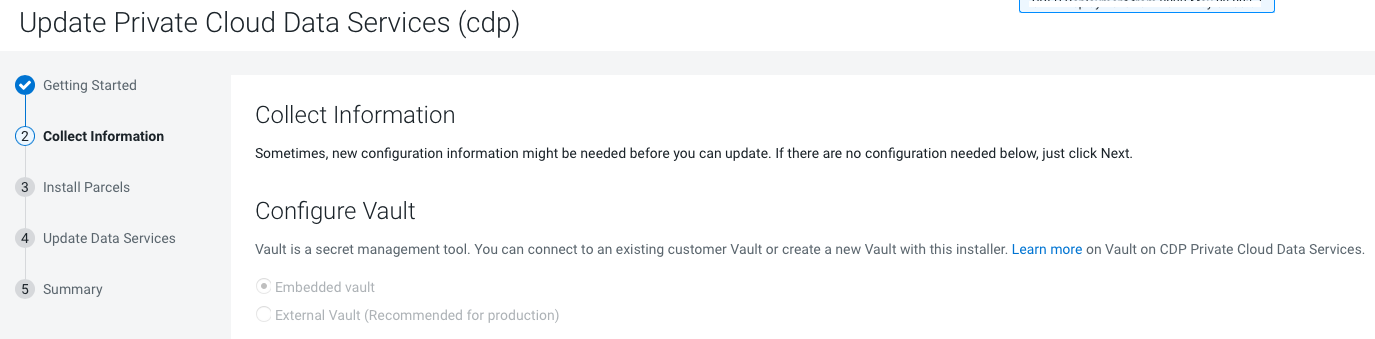
On the Collect Information page, click
Continue.
On the Install Parcels page, click
Continue.
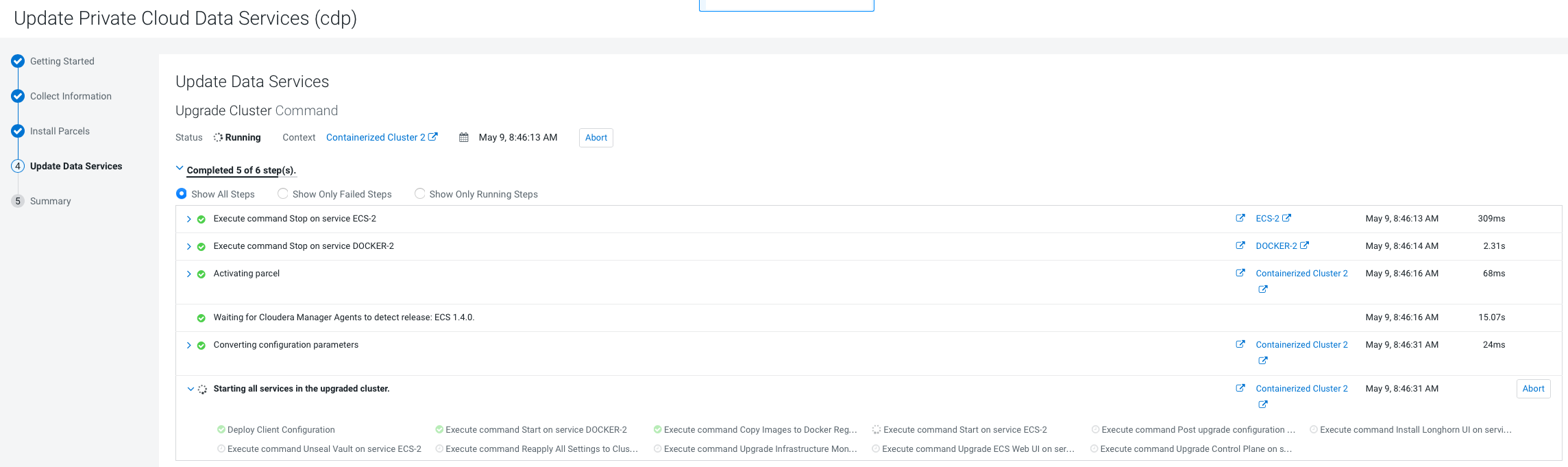
On the Update Progress page, you can see the
progress of your update. Click Continue after
the update is complete .
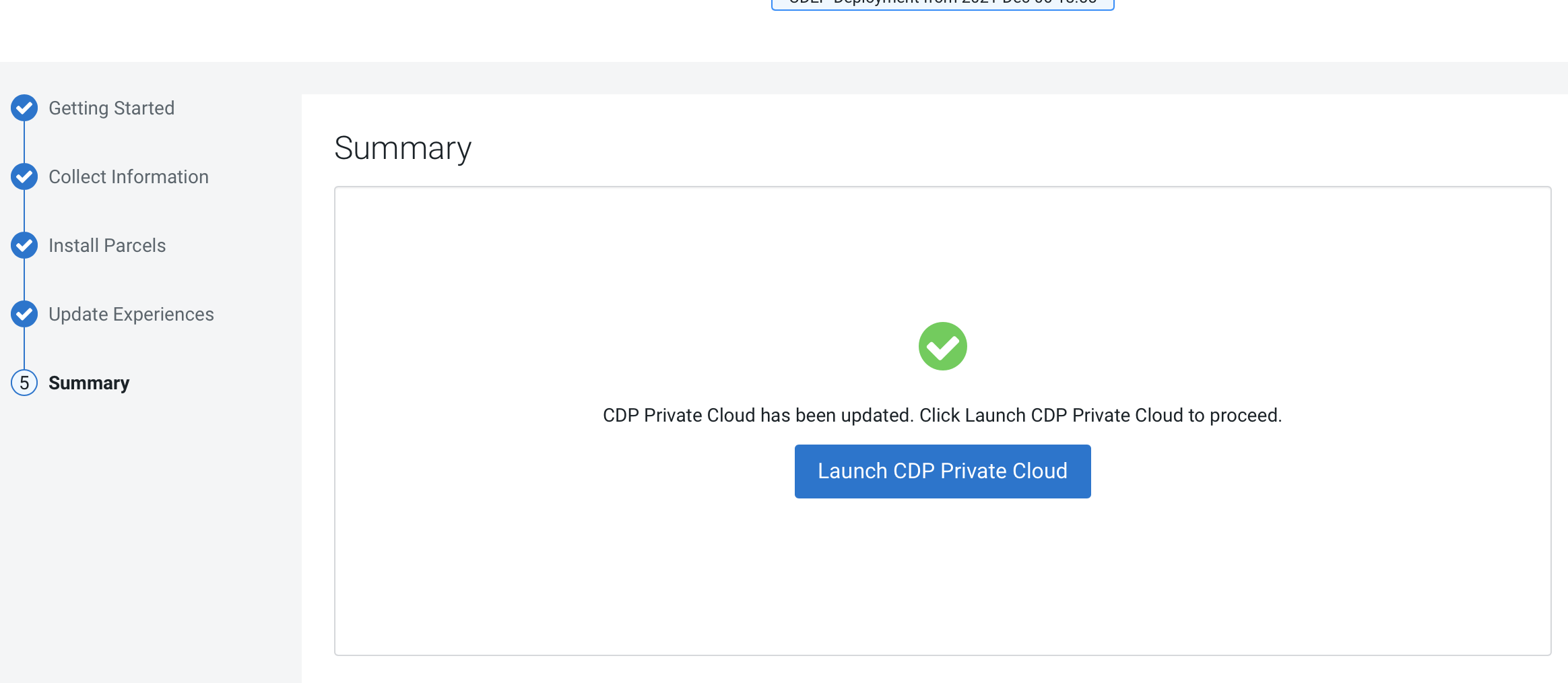
After the update is complete, the Summary
page appears. You can now Launch CDP Private
Cloud from here.
If you see a Longhorn Health Test message about a degraded
Longhorn volume, wait for the cluster repair to complete.
Or you can navigate to the CDP Private Cloud Data
Services page and click Open CDP Private
Cloud Data Services.
CDP Private Cloud Data Services opens
up in a new window.
If the upgrade stalls, do the following:
Check the status of all pods by running the following command on
the ECS server node:
kubectl get pods --all-namespaces
If there are any pods stuck in “Terminating” state, then force
terminate the pod using the following
command:
kubectl delete pods <NAME OF THE POD> -n <NAMESPACE> --grace-period=0 —force
If
the upgrade still does not resume, continue with the remaining
steps.
In the Cloudera Manager Admin Console, go to the ECS service and
click Web UI > Storage
UI.
The Longhorn dashboard opens.
Check the "in Progress" section of the dashboard to see whether
there are any volumes stuck in the attaching/detaching state in.
If a volume is that state, reboot its host.
You may see the following error message during the
Upgrade Cluster > Reapplying all settings > kubectl-patch
:
kubectl rollout status deployment/rke2-ingress-nginx-controller -n kube-system --timeout=5m
error: timed out waiting for the condition
If you see this
error, do the following:
Check whether all the Kubernetes nodes are ready for scheduling.
Run the following command from the ECS Server
node:
kubectl get nodes
You
will see output similar to the
following:
NAME STATUS ROLES AGE VERSION
<node1> Ready,SchedulingDisabled control-plane,etcd,master 103m v1.21.11+rke2r1
<node2> Ready <none> 101m v1.21.11+rke2r1
<node3> Ready <none> 101m v1.21.11+rke2r1
<node4> Ready <none> 101m v1.21.11+rke2r1
Run the following command from the ECS Server node for the node
showing a status of
SchedulingDisabled:
kubectl uncordon
You
will see output similar to the following:
<node1>node/<node1> uncordoned
Scale down and scale up the
rke2-ingress-nginx-controller pod by
running the following command on the ECS Server
node:
kubectl delete pod rke2-ingress-nginx-controller-<pod number> -n kube-system
Resume the upgrade.
This site uses cookies and related technologies, as described in our privacy policy, for purposes that may include site operation, analytics, enhanced user experience, or advertising. You may choose to consent to our use of these technologies, or

 . Click
Update.
. Click
Update.