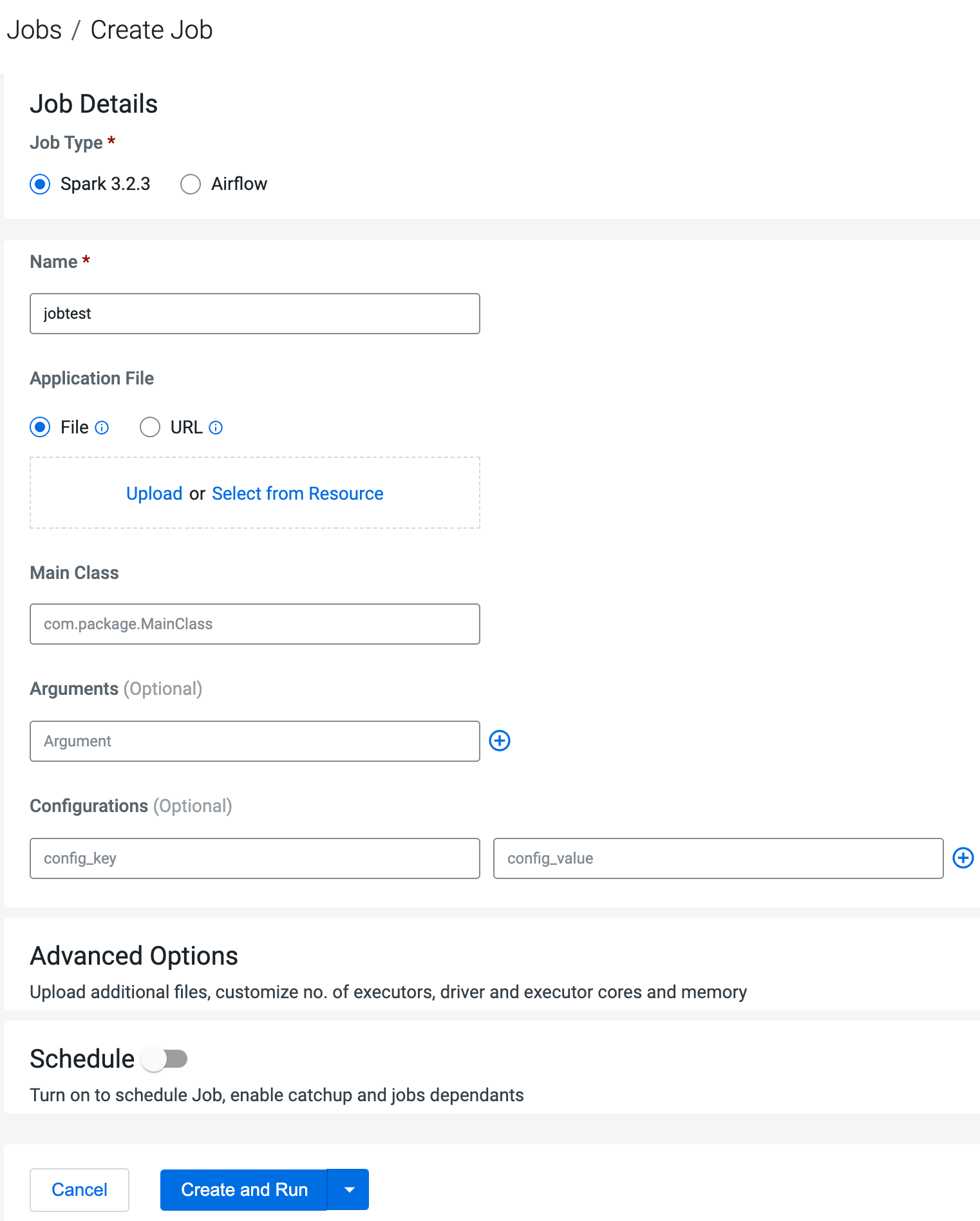
Creating jobs in Cloudera Data Engineering
A job in Cloudera Data Engineering (CDE) consists of defined configurations and resources (including application code). Jobs can be run on demand or scheduled.
In Cloudera Data Engineering (CDE), jobs are associated with virtual clusters. Before you can create a job, you must create a virtual cluster that can run it. For more information, see Creating virtual clusters.
-
In the CDE Home page, in Jobs, click
Create New under Spark or click
Jobs in the left navigation menu and then click Create
Job.