Tuning YARN
This topic applies to YARN clusters only, and describes how to tune and optimize YARN for your cluster.
Overview
This overview provides an abstract description of a YARN cluster and the goals of YARN tuning.
|
A YARN cluster is composed of host machines. Hosts provide memory and CPU resources. A vcore, or virtual core, is a usage share of a host CPU. |
 |
|
Tuning YARN consists primarily of optimally defining containers on your worker hosts. You can think of a container as a rectangular graph consisting of memory and vcores. Containers perform tasks. |
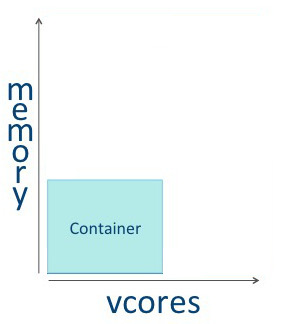 |
|
Some tasks use a great deal of memory, with minimal processing on a large volume of data. |
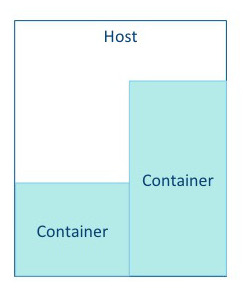 |
|
Other tasks require a great deal of processing power, but use less memory. For example, a Monte Carlo Simulation that evaluates many possible "what if?" scenarios uses a great deal of processing power on a relatively small dataset. |
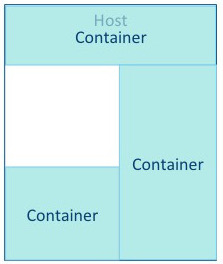 |
|
The YARN ResourceManager allocates memory and vcores to use all available resources in the most efficient way possible. Ideally, few or no resources are left idle. |
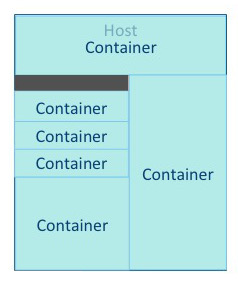 |
|
An application is a YARN client program consisting of one or more tasks. Typically, a task uses all of the available resources in the container. A task cannot consume more than its designated allocation, ensuring that it cannot use all of the host CPU cycles or exceed its memory allotment. |
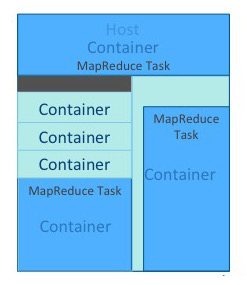 |
|
Tune your YARN hosts to optimize the use of vcores and memory by configuring your containers to use all available resources beyond those required for overhead and other services. |
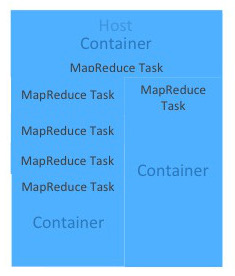 |
- Cluster configuration, where you configure your hosts.
- YARN configuration, where you quantify memory and vcores.
- MapReduce configuration, where you allocate minimum and maximum resources for specific map and reduce tasks.
YARN and MapReduce have many configurable properties. For a complete list, see Cloudera Manager Configuration Properties. The YARN tuning spreadsheet lists the essential subset of these properties that are most likely to improve performance for common MapReduce applications.
Cluster Configuration
In the Cluster Configuration tab, you define the worker host configuration and cluster size for your YARN implementation.
Step 1: Worker Host Configuration
Step 1 is to define the configuration for a single worker host computer in your cluster.

As with any system, the more memory and CPU resources available, the faster the cluster can process large amounts of data. A machine with 4 CPUs with HyperThreading, each with 6 cores, provides 48 vcores per host.
3 TB hard drives in a 2-unit server installation with 12 available slots in JBOD (Just a Bunch Of Disks) configuration is a reasonable balance of performance and pricing at the time the spreadsheet was created. The cost of storage decreases over time, so you might consider 4 TB disks. Larger disks are expensive and not required for all use cases.
Two 1-Gigabit Ethernet ports provide sufficient throughput at the time the spreadsheet was published, but 10-Gigabit Ethernet ports are an option where price is of less concern than speed.
Step 2: Worker Host Planning
Step 2 is to allocate resources on each worker machine.
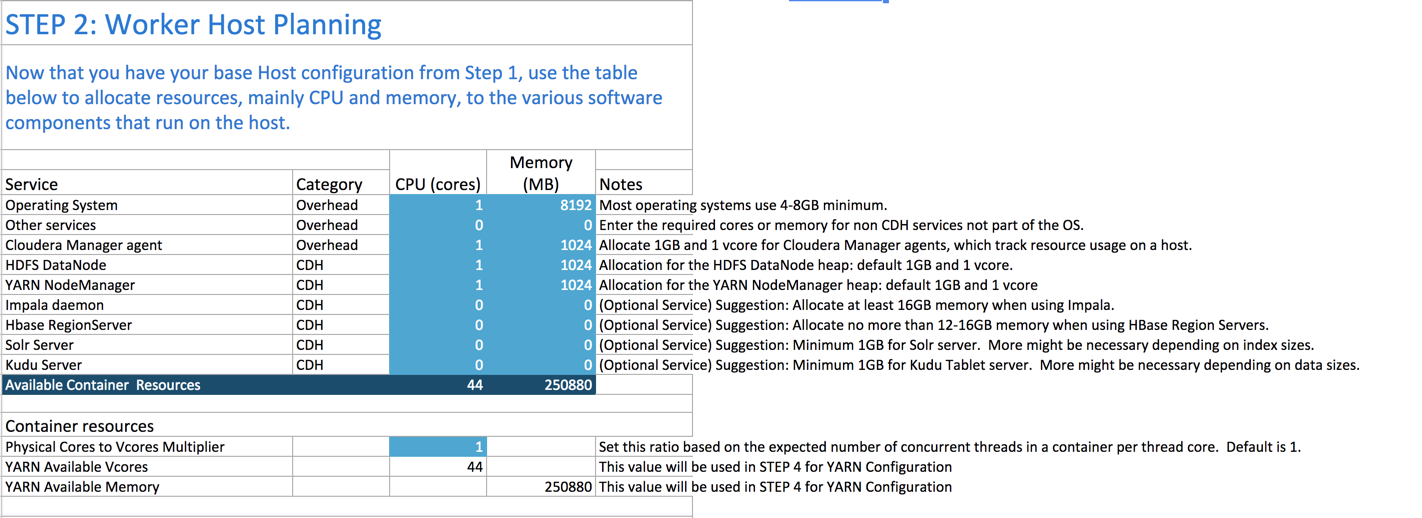
Start with at least 8 GB for your operating system, and 1 GB for Cloudera Manager. If services outside of CDH require additional resources, add those numbers under Other Services.
The HDFS DataNode uses a minimum of 1 core and about 1 GB of memory. The same requirements apply to the YARN NodeManager.
- Impala daemon requires at least 16 GB for the daemon.
- HBase Region Servers requires 12-16 GB of memory.
- Solr server requires a minimum of 1 GB of memory.
- Kudu Tablet server requires a minimum of 1 GB of memory.
Any remaining resources are available for YARN applications (Spark and MapReduce). In this example, 44 CPU cores are available. Set the multiplier for vcores you want on each physical core to calculate the total available vcores.
Step 3: Cluster Size
Having defined the specifications for each host in your cluster, enter the number of worker hosts needed to support your business case. To see the benefits of parallel computing, set the number of hosts to a minimum of 10.

YARN Configuration
On the YARN Configuration tab, you verify your available resources and set minimum and maximum limits for each container.
Steps 4 and 5: Verify Settings
Step 4 pulls forward the memory and vcore numbers from step 2. Step 5 shows the total memory and vcores for the cluster.
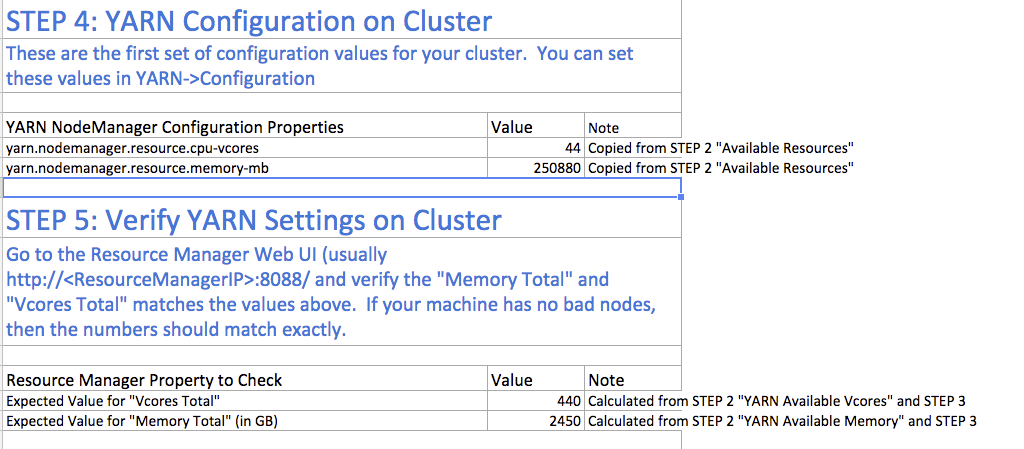
Step 6: Verify Container Settings on Cluster
In step 6, you can change the values that impact the size of your containers.
The minimum number of vcores should be 1. When additional vcores are required, adding 1 at a time should result in the most efficient allocation. Set the maximum number of vcore reservations to the size of the node.
Set the minimum and maximum reservations for memory. The increment should be the smallest amount that can impact performance. Here, the minimum is approximately 1 GB, the maximum is approximately 8 GB, and the increment is 512 MB.

Step 6A: Cluster Container Capacity
Step 6A lets you validate the minimum and maximum number of containers in your cluster, based on the numbers you entered.

Step 6B: Container Sanity Checking
Step 6B lets you see, at a glance, whether you have over-allocated resources.

MapReduce Configuration
On the MapReduce Configuration tab, you can plan for increased task-specific memory capacity.
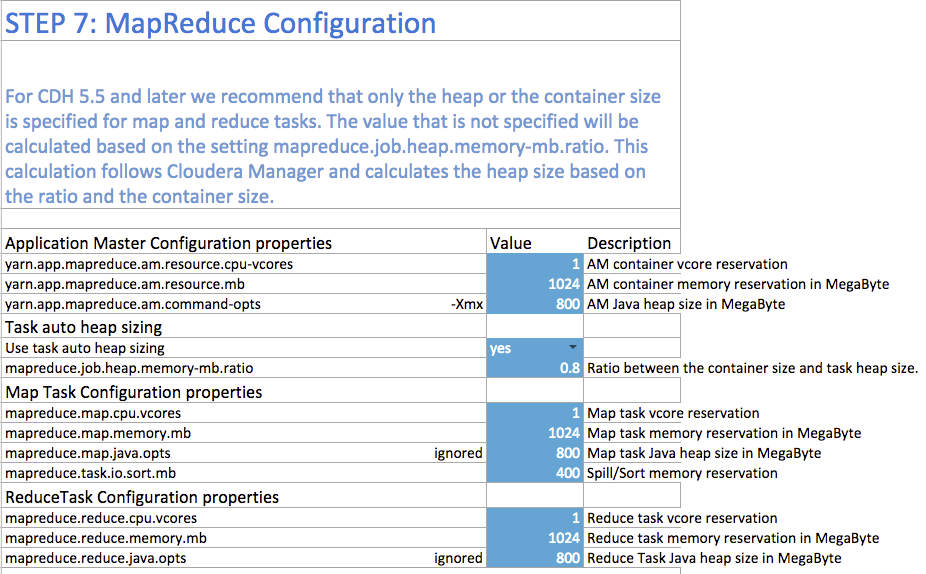
Step 7: MapReduce Configuration
You can increase the memory allocation for the ApplicationMaster, map tasks, and reduce tasks. The minimum vcore allocation for any task is always 1. The Spill/Sort memory allocation of 400 should be sufficient, and should be (rarely) increased if you determine that frequent spills to disk are hurting job performance.
In CDH 5.5 and higher, the common MapReduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and yarn.app.mapreduce.am.command-opts are configured for you automatically based on the Heap to Container Size Ratio.
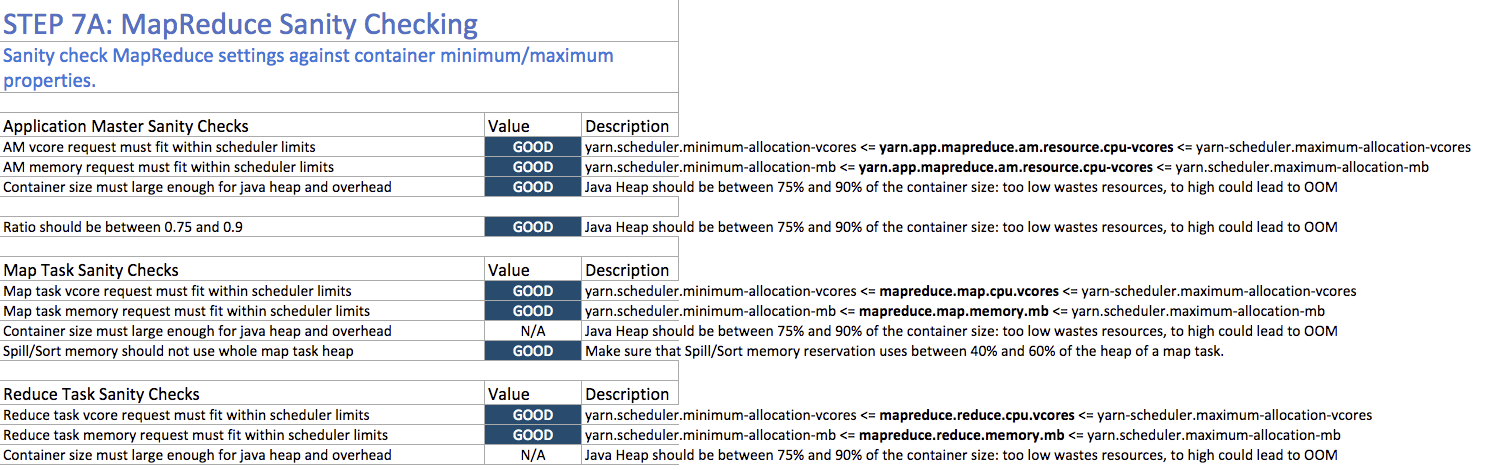
Step 7A: MapReduce Sanity Checking
Step 7A lets you verify at a glance that all of your minimum and maximum resource allocations are within the parameters you set.
Continuous Scheduling
- yarn.scheduler.fair.continuous-scheduling-enabled should be false
- yarn.scheduler.fair.assignmultiple should be true
For more information about continuous scheduling tuning, see the following knowledge base article: FairScheduler Tuning with assignmultiple and Continuous Scheduling
Configuring Your Cluster In Cloudera Manager
When you are satisfied with the cluster configuration estimates, use the values in the spreadsheet to set the corresponding properties in Cloudera Manager. For more information, see Modifying Configuration Properties Using Cloudera Manager.
| Step | YARN/MapReduce Property | Cloudera Manager Equivalent |
|---|---|---|
| 4 | yarn.nodemanager.resource.cpu-vcores | Container Virtual CPU Cores |
| 4 | yarn.nodemanager.resource.memory-mb | Container Memory |
| 6 | yarn.scheduler.minimum-allocation-vcores | Container Virtual CPU Cores Minimum |
| 6 | yarn.scheduler.maximum-allocation-vcores | Container Virtual CPU Cores Maximum |
| 6 | yarn.scheduler.increment-allocation-vcores | Container Virtual CPU Cores Increment |
| 6 | yarn.scheduler.minimum-allocation-mb | Container Memory Minimum |
| 6 | yarn.scheduler.maximum-allocation-mb | Container Memory Maximum |
| 6 | yarn.scheduler.increment-allocation-mb | Container Memory Increment |
| 7 | yarn.app.mapreduce.am.resource.cpu-vcores | ApplicationMaster Virtual CPU Cores |
| 7 | yarn.app.mapreduce.am.resource.mb | ApplicationMaster Memory |
| 7 | mapreduce.map.cpu.vcores | Map Task CPU Virtual Cores |
| 7 | mapreduce.map.memory.mb | Map Task Memory |
| 7 | mapreduce.reduce.cpu.vcores | Reduce Task CPU Virtual Cores |
| 7 | mapreduce.reduce.memory.mb | Reduce Task Memory |
| 7 | mapreduce.task.io.sort.mb | I/O Sort Memory |
