

HBase Cluster Replication Details
A Write Ahead Log edit goes through a series of steps to complete the replication process.
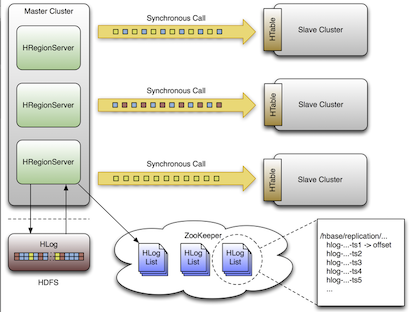
WAL (Write Ahead Log) Edit Process
A single WAL edit goes through the following steps when it is replicated to a slave cluster:
- An HBase client uses a Put or Delete operation to manipulate data in HBase.
- The RegionServer writes the request to the WAL in such a way that it can be replayed if the write operation is not successful.
- If the changed cell corresponds to a column family that is scoped for replication, the edit is added to the queue for replication.
- In a separate thread, the edit is read from the log as part of a batch process. Only the KeyValues that are eligible for replication are kept.
KeyValues that are eligible for replication are those KeyValues that are:
- Part of a column family whose schema is scoped GLOBAL.
- Not part of a catalog such as
hbase:meta. - Have not originated from the target slave cluster.
- Have not already been consumed by the target slave cluster.
- The WAL edit is tagged with the master’s UUID and added to a buffer. When the buffer is full or the reader reaches the end of the file, the buffer is sent to a random RegionServer on the slave cluster.
- The RegionServer reads the edits sequentially and separates them into buffers, one buffer per table. After all edits are read, each buffer is flushed using Table, the HBase client. The UUID of the master RegionServer and the UUIDs of the slaves, which have already consumed the data, are preserved in the edits when they are applied. This prevents replication loops.
- The offset for the WAL that is currently being replicated in the master is registered in ZooKeeper.
- The edit is inserted as described in Steps 1, 2, and 3.
- In a separate thread, the RegionServer reads, filters, and edits the log edits as described in Step 4. The slave RegionServer does not answer the RPC call.
- The master RegionServer sleeps and tries again. The number of attempts can be configured.
- If the slave RegionServer is still not available, the master selects a new subset of RegionServers to replicate to, and tries again to send the buffer of edits.
- Meanwhile, the WALs are rolled and stored in a queue in ZooKeeper. Logs that are archived by their RegionServer (by moving them from the RegionServer log directory to a central log directory) update their paths in the in-memory queue of the replicating thread.
- When the slave cluster is finally available, the buffer is applied in the same way as during normal processing. The master RegionServer then replicates the backlog of logs that accumulated during the outage.