October 5, 2023
This release of the Cloudera Data Warehouse (CDW) service on CDP Public Cloud has the following known issues:
New Known Issues in this release
There are no new known issues in this release for CDW. See Data Visualization release notes for known issues in Cloudera Data Visualization 7.1.3.
Carried over from the previous release: Upgrade-related
- Upgrading to EKS 1.24 could result in Impala coordinators shutting down.
- This issue is not seen on the Impala Virtual Warehouse running Runtime 2023.0.15.0-x or later.
- Issue backing up and restoring Workload Aware Auto-Scaling (WAAS)
- You cannot use the CDW backup and restore process to restore the WAAS configurations.
- Certain CDW versions cannot upgrade to EKS 1.22
- AWS environments activated in version 1.4.1-b86 (released June, 22, 2022) or earlier are
not supported for upgrade to EKS 1.22 due to incompatibility of some components with EKS 1.22.
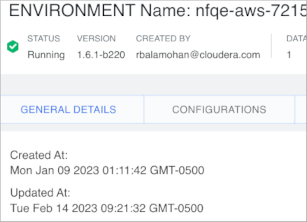
To determine the activation version your pre-existing environment, in the Data Warehouse
service, expand Environments. In Environments, search for and locate the environment that you
want to view. Click Edit. In Environment Details, you see the CDW version.
- DWX-15112 Enterprise Data Warehouse database configuration problems after a Helm-related rollback
- If a Helm rollback fails due to an incorrect Enterprise Data Warehouse database configuration, the Virtual Warehouse and Database Catalog roll back to a previous configuration. The incorrect Enterprise Data Warehouse configuration persists, and can affect subsequent edit, upgrade, and rebuild operations on the rolled-back Virtual Warehouse or Database Catalog.
Carried over from the previous release: General
- Compaction causes data loss under certain conditions
- Data loss occurs during compaction when Apache Ranger policies for masking or row filtering are enabled and compaction users are included in the policies.
- DWX-14923 After JWT authentication, attempting to connect the Impyla client using a user name or password should cause an error
- Using a JWT token, you can connect to a Virtual Warehouse as the user who generated the token.
- DWX-15145 Environment validation popup error after activating an environment
- Activating an environment having a public load balancer can cause an environment validatation popup error.
- To reproduce this problem 1) Create a data lake. 2) Activate an enviroment having a
public load balancer deployment type and subnets in three different availability zones.
A environment validation popup can occur even through subnets are in different
availability zones. Several differnt popups can occur, including the following one:

- DWX-15144 Virtual Warehouse naming restrictions
- You cannot create a Virtual Warehouse having the same name as another Virtual Warehouse even if the like-named Virtual Warehouses are in different environments. You can create a Database Catalog having the same name as another Database Catalog if the Database Catalogs are in different environments.
- DWX-13103 Cloudera Data Warehouse environment activation problem
- When CDW environments are activated, a race condition can occur between the prometheus pod and istiod pod. The prometheus pod can be set up without an istio-proxy container, causing communication failures to/from prometheus to any other pods in the Kubernetes cluster. Data Warehouse prometheus-related functionalities, such as autoscaling, stop working. Grafana dashboards, which get metrics from prometheus, are not populated.
- DWX-5742: Upgrading multiple Hive and Impala Virtual Warehouses or Database Catalogs at the same time fails
- Problem: Upgrading multiple Hive and Impala Virtual Warehouses or Database Catalogs at the same time fails.
Carried over from the previous release: AWS
- AWS availability zone inventory issue
- In this release, you can select a preferred availability zone when you create a Virtual Warehouse; however, AWS might not be able to provide enough compute instances of the type that Cloudera Data Warehouse needs.
- DWX-7613: CloudFormation stack creation using AWS CLI broken for CDW Reduced Permissions Mode
- Problem: If you use the AWS CLI to create a CloudFormation stack to activate an AWS
environment for use in Reduced Permissions Mode, it fails and returns the following error:
The default value of SdxDDBTableName is not being set. If you create the CloudFormation stack using the AWS Console, there is no problem.An error occurred (ValidationError) when calling the CreateStack operation: Parameters: [SdxDDBTableName] must have values - ENGESC-8271: Helm 2 to Helm 3 migration fails on AWS environments where the overlay network feature is in use and namespaces are stuck in a terminating state
- Problem: While using the overlay network feature for AWS environments and after attempting to migrate an AWS environment from Helm 2 to Helm 3, the migration process fails.
- DWX-6970: Tags do not get applied in existing CDW environments
- Problem: You may see the following error while trying to apply tags to Virtual
Warehouses in an existing CDW environment:
An error occurred (UnauthorizedOperation) when calling the CreateTags operation: You are not authorized to perform this operationandCompute node tagging was unsuccessful. This happens because theec2:CreateTagsprivilege is missing from your AWS cluster-autoscaler inline policy for theNodeInstanceRolerole.
Carried over from the previous release: Azure
- Enabling a private CDW environment in Azure Kubernetes Service is unstable
Cloudera rolled back the General Availability (GA) status and support for deploying a private CDW environment in Azure using AKS until a solution for the issue is available.
When working together with Microsoft Azure (Azure), a networking issue has been identified at Azure Software Definition Layer (SDN) that impacts the use of CDW private environments while using the Azure Kubernetes Service (AKS). This issue is highly unpredictable and may cause timeouts during Cloudera Data Warehouse (CDW) environment activation, Virtual Warehouse creation, Virtual Warehouse modification, and/or during start and stop operations in CDW.
- DWX-15214 DWX-15176 Hue frontend may become stuck in CrashLoopBackoff on CDW running on Azure
- The Hue frontend for Apache Impala (Impala) and Apache Hive (Hive) Virtual Warehouses
created in Cloudera Data Warehouse (CDW) can be stuck in a CrashLoopBackoff state on
Microsoft Azure (Azure) platform, making it impossible to reach the Virtual Warehouse
through Hue. In this case, the following error message is displayed:
kubelet Error: failed to create containerd task: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: exec: “run_httpd.sh”: cannot run executable found relative to current directory: unknown
- Workloads from earlier CDW versions cannot be deployed on new Azure environments
- Because new environments are provisioned automatically to use Azure Kubernetes Service (AKS) 1.22, deprecated APIs used in workloads of earlier versions are not supported in this version 2022.0.9.0-120 (released August 4, 2022). This issue affects you only if you have the CDW_VERSIONED_DEPLOY entitlement.
- Incorrect diagnostic bundle location
- Problem:The path you see to the diagnostic bundle is wrong when you create a
Virtual Warehouse, collect a diagnostic bundle of log files for troubleshooting, and
click
 . Your storage account name is missing from the beginning of the
path.
. Your storage account name is missing from the beginning of the
path.
- Changed environment credentials not propagated to AKS
-
Problem: When you change the credentials of a running cloud environment using the Management Console, the changes are not automatically propagated to the corresponding active Cloudera Data Warehouse (CDW) environment. As a result, the Azure Kubernetes Service (AKS) uses old credentials and may not function as expected resulting in inaccessible Hive or Impala Virtual Warehouses.
Workaround: To resolve this issue, you must manually synchronize the changes with the CDW AKS resources. To synchronize the updated credentials, see Update AKS cluster with new service principal credentials in the Azure product documentation.
Carried over from the previous release: Database Catalog
- Non-default Database Catalogs created with several earlier CDW versions fails
- This issue affects you only if you meet the following conditions:
- You have a versioned CDW deployment and the multi default DBC entitlement.
- You are using this release of CDW version 2022.0.9.0-120 (released August 4, 2022).
- You added Database Catalogs (not the automatically generated default Database Catalog)
using either one of these CDW versions:
- 2022.0.8.0-89 (released June, 22, 2022)
- 2022-0.7.1-2 (released May 10, 2022)
Do not attempt to upgrade the Database Catalog you created with these earlier releases. The Database Catalog will fail. Your existing Database Catalog created with the earlier release works fine with CDW Runtime. Recreating your existing Database Catalog updates CDW Runtime for 2022.0.9.0-120 (released August 4, 2022).
- DWX-7349: In reduced permissions mode, default Database Catalog name does not include the environment name
- Problem:
When you activate an AWS environment in reduced permissions mode, the default Database Catalog name does not include the environment name:
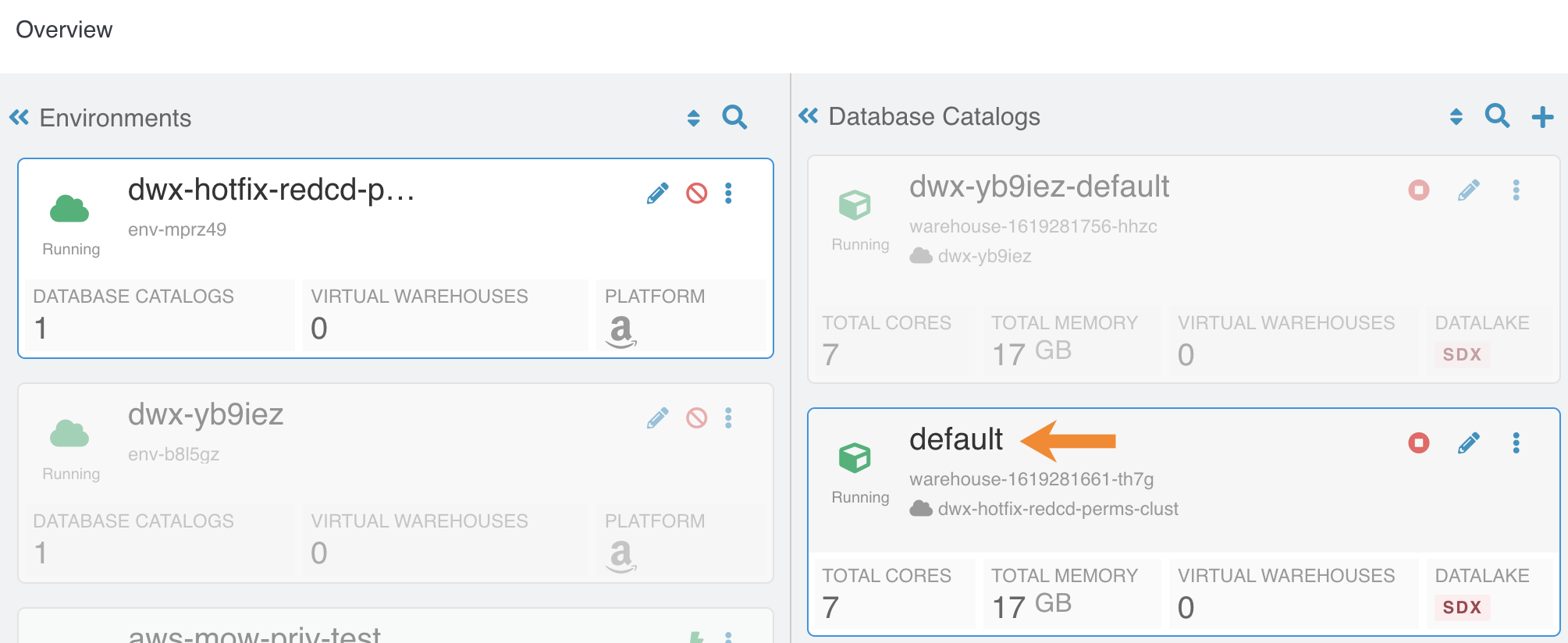
This does not cause collisions because each Database Catalog named "default" is associated with a different environment. For more information about reduced permissions mode, see Reduced permissions mode for AWS environments.
- DWX-6167: Maximum connections reached when creating multiple Database Catalogs
- Problem:After creating 17 Database Catalogs on one AWS environment, Virtual Warehouses failed to start.
Carried over from the previous release: Hive Virtual Warehouse
- DWX-15064 Hive Virtual Warehouse stops but appears healthy
- Due to an istio-proxy problem, the query coordinator can unexpectedly enter a not ready state instead of the expected error-state. Subsequently, the Hive Virtual Warehouse stops when reaching the autosuspend timeout without indicating a problem.
- DWX-14452 Parquet table query might fail
- Querying a table stored in Parquet from Hive might fail with the following exception message: java.lang.RuntimeException: java.lang.StackOverflowError. This problem can occur when the IN predicate has 243 values or more, and a small stack (-Xss = 256k) is configured for Hive in CDW.
- Workaround: Change the value of the Xss in the JVM args to use the default value (1Mb)
as follows: Select Edit from the Options menu of your Virtual Warehouse. Click
Configurations > Query Executor > and select env.
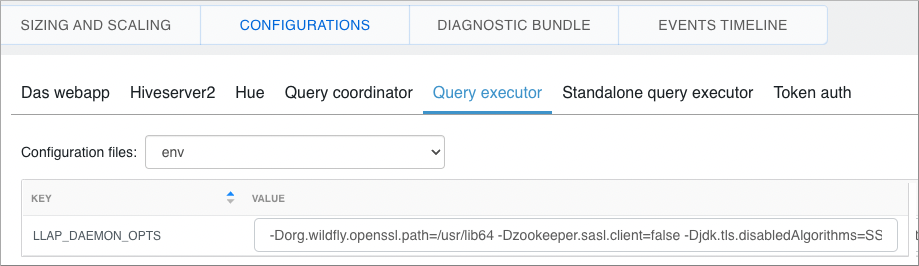
In the third line shown below, change the value of LLAP_DAEMON_OPTS from -Xss256k to -Xss1M, and then click Apply Changes:
FROM:
-Dorg.wildfly.openssl.path=/usr/lib64 -Dzookeeper.sasl.client=false -Djdk.tls.disabledAlgorithms=SSLv3,GCM -Dhttp.maxConnections=12 -Xms24G -Xmx48G -Xss256k ...
TO:
... -Xss1M ...
- Diagnostic bundle download fails
- After upgrading to version 1.4.3 (released September 15, 2022), downloading the diagnostic bundle for the Hive Virtual Warehouse results in an error. New environments do not have this problem. The problem is caused by missing permissions to access Kubernetes resources. Version 1.4.3 adds a requirement for the role-based access control (rbac) permissions to download the diagnostic bundle.
- CDPD-40730 Parquet change can cause incompatibility
- Parquet files written by the parquet-mr library in this version of CDW, where the schema
contains a timestamp with no UTC conversion will not be compatible with older versions of
Parquet readers. The effect is that the older versions will still consider these timestamps as
they would require UTC conversions and will thus end up with a wrong result. You can encounter
this problem only when you write Parquet-based tables using Hive, and tables have the
non-default configuration
hive.parquet.write.int64.timestamp=true.
- DWX-5926: Cloning an existing Hive Virtual Warehouse fails
- Problem: If you have an existing Hive Virtual Warehouse that you clone by selecting Clone from the drop-down menu, the cloning process fails. This does not apply to creating a new Hive Virtual Warehouse.
- Workaround: Make the following configuration change to resolve this issue:
- In the Hive Virtual Warehouse tile, click the edit icon. This launches the Virtual Warehouse details page.
- In the details page for the Virtual Warehouse, click the Configurations tab.
- Click the Hiveserver2 sub-tab.
- Select hive-site from the configuration file drop-down list menu.
- Search for the configuration property
hive.metastore.sasl.enabled. - Set the
hive.metastore.sasl.enabledconfiguration property totrue. - Click Apply in the upper right corner of the page to save the configuration.
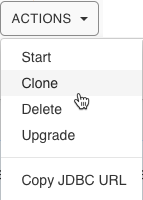
- Click the Actions menu and select Clone to
clone the Hive Virtual Warehouse:
- DWX-2690: Older versions of Beeline return SSLPeerUnverifiedException when submitting a query
-
Problem: When submitting queries to Virtual Warehouses that use Hive, older Beeline clients return an SSLPeerUnverifiedException error:
javax.net.ssl.SSLPeerUnverifiedException: Host name ‘ec2-18-219-32-183.us-east-2.compute.amazonaws.com’ does not match the certificate subject provided by the peer (CN=*.env-c25dsw.dwx.cloudera.site) (state=08S01,code=0)
Carried over from the previous release: Hue Query Editor
- Delay in listing queries in Impala Queries in the Job browser
- Listing an Impala query in the Job browser can take an inordinate amount of time.
- DWX-14927 Hue fails to list Iceberg snapshots
- Hue does not recognize the Iceberg history queries from Hive to list table snapshots.
For example, Hue indicates an error at the . before history when you run the following
query.
select * from <db_name>.<table_name>.history
- DWX-14968 Connection termination error in Impala queries tab after Hue inactivity
- To reproduce the problem: 1) In the Impala job browser, navigate to Impala queries. 2) Wait for a few minutes.
- After a few minutes of inactivity, the follow error is displayed:
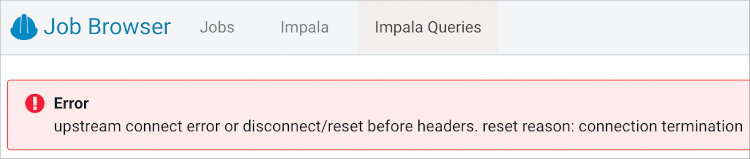
- DWX-15115 Error displayed after clicking on hyperlink below Hue table browser
- In Hue, below the table browser, clicking the hyperlink to a location causes an HTTP 500 error because the file browser is not enabled for environments that are not Ranger authorized (RAZ).
- DWX-15090: CSRF error intermittently seen in the Hue Job Browser
- You may intermittently see the “403 - CSRF” error on the Hue web interface as well as in the Hue logs after running Hive queries from Hue.
- IMPALA-11447 Selecting certain complex types in Hue crashes Impala
- Queries that have structs/arrays in the select list crash Impala if initiated by Hue.
- DWX-8460: Unable to delete, move, or rename directories within the S3 bucket from Hue
- Problem: You may not be able to rename, move, or delete directories within your S3 bucket from the Hue web interface. This is because of an underlying issue, which will be fixed in a future release.
- DWX-6674: Hue connection fails on cloned Impala Virtual Warehouses after upgrading
- Problem: If you clone an Impala Virtual Warehouse from a recently upgraded Impala Virtual Warehouse, and then try to connect to Hue, the connection fails.
- DWX-5650: Hue only makes the first user a superuser for all Virtual Warehouses within a Data Catalog
- Problem: Hue marks the user that logs in to Hue from a Virtual Warehouse for the
first time as the Hue superuser. But if multiple Virtual Warehouses are connected to a single
Data Catalog, then the first user that logs in to any one of the Virtual Warehouses within
that Data Catalog is the Hue superuser.
For example, consider that a Data Catalog DC-1 has two Virtual Warehouses VW-1 and VW-2. If a user named John logs in to Hue from VW-1 first, then he becomes the Hue superuser for all the Virtual Warehouses within DC-1. At this time, if Amy logs in to Hue from VW-2, Hue does not make her a superuser within VW-2.
Iceberg
- DWX-15014 Loading airports table in demo data fails
- This issue occurs only when using a non-default Database Catalog. A invalid path error message occurs when using the load command to load the demo data airports table in Iceberg, ORC, or Parquet format.
- DWX-14163 Limitations reading Iceberg tables in Avro file format from Impala
- The Avro, Impala, and Iceberg specifications describe some limitations related to Avro, and those limitations exist in CDP. In addition to these, the DECIMAL type is not supported in this release.
- DEX-7946 Data loss during migration of a Hive table to Iceberg
- In this release, by default the table property 'external.table.purge' is set to true, which deletes the table data and metadata if you drop the table during migration from Hive to Iceberg.
- DWX-13733 Timeout issue querying Iceberg tables from Hive
- A timeout issue can cause the query to fail.
- DWX-13062 Hive-26507 Converting a Hive table having CHAR or VARCHAR columns to Iceberg causes an exception
- CHAR and VARCHAR data can be shorter than the length specified by the data type. Remaining characters are padded with spaces. Data is converted to a string in Iceberg. This process can yield incorrect results when you query the converted Iceberg table.
- DWX-13276 Multiple inserts into tables having different formats can cause a deadlock.
- Under the following conditions, a deadlock can occur:
- You run a query to insert data into multiple tables comprised of at least one Iceberg table and at least one non-Iceberg table.
- The STAT task locking feature is turned on (default = on).
Carried over from the previous release: Impala Virtual Warehouse
- TSB 2023-684: Automatic metadata synchronization across multiple Impala Virtual Warehouses (in CDW Public Cloud) may encounter an exception
- The Cloudera Data Warehouse (CDW) Public Cloud 2023.0.14.0
(DWX-1.6.3) version incorporated a feature for performing automatic metadata
synchronization across multiple Apache Impala (Impala) Virtual Warehouses. The feature
is enabled by default, and relies on the Hive
MetaStore events. When a certain sequence of Data Definition Language (DDL) SQL commands
are executed as described below, users may encounter a java.lang.NullPointerException
(NPE). The exception causes the event processor to stop processing other metadata
operations.
If a CREATE TABLE command (not CREATE TABLE AS SELECT) is followed immediately (approximately within 1 second interval) by INVALIDATE METADATA or REFRESH TABLE command on the same table (either on the same Virtual Warehouse or on a different one), there is a possibility that the second command will not find the table in the catalog cache of a peer Virtual Warehouse and generate an NPE.
- Knowledge article
- For the latest update on this issue see the corresponding Knowledge article: TSB 2023-684: Automatic metadata synchronization across multiple Impala Virtual Warehouses (in CDW Public Cloud) may encounter an exception
- MT_DOP related issue
- Problem:Impala query with JOIN and LIMIT can hang when MT_DOP is greater than
0.
Workaround: Set MT_DOP to zero.
- DWX-15016 Impala query failure when using Catalog high availability (HA)
- Impala queries could fail with InconsistentMetadataFetchException when using HA feature in CDW. This happens when leader election failover for Impala Catalog Service happens due to a transient network error.
- IMPALA-11045 Impala Virtual Warehouses might produce an error when querying transactional (ACID) table even after you enabled the automatic metadata refresh (version DWX 1.1.2-b2008)
- Problem: Impala doesn't open a transaction for select queries, so you might get a FileNotFound error after compaction even though you refreshed the metadata automatically.
- Impala Virtual Warehouses might produce an error when querying transactional (ACID) tables (DWX 1.1.2-b1949 or earlier)
- Problem: If you are querying transactional (ACID) tables with an Impala Virtual Warehouse and compaction is run on the compacting Hive Virtual Warehouse, the query might fail. The compacting process deletes files and the Impala Virtual Warehouse might not be aware of the deletion. Then when the Impala Virtual Warehouse attempts to read the deleted file, an error can occur. This situation occurs randomly.
- Do not use the start/stop icons in Impala Virtual Warehouses version 7.2.2.0-106 or earlier
- Problem: If you use the stop/start icons in Impala Virtual Warehouses version 7.2.2.0-106 or earlier, it might render the Virtual Warehouse unusable and make it necessary for you to re-create it.
- DWX-6674: Hue connection fails on cloned Impala Virtual Warehouses after upgrading
- Problem: If you clone an Impala Virtual Warehouse from a recently upgraded Impala Virtual Warehouse, and then try to connect to Hue, the connection fails.
- DWX-5841: Virtual Warehouse endpoints are now restricted to TLS 1.2
- Problem: TLS 1.0 and 1.1 are no longer considered secure, so now Virtual Warehouse
endpoints must be secured with TLS 1.2 or later, and then the environment that the Virtual
Warehouse uses must be reactivated in CDW. This includes both Hive and Impala Virtual
Warehouses. To reactivate the environment in the CDW UI:
- Deactivate the environment. See Deactivating AWS environments or Deactivating Azure environments.
- Activate the environment. See Activating AWS environments or Activating Azure environments
- DWX-5276: Upgrading an older version of an Impala Virtual Warehouse can result in error state
- Problem: If you upgrade an older version of an Impala Virtual Warehouse (DWX 1.1.1.1-4) to the latest version, the Virtual Warehouse can get into an Updating or Error state.
- DWX-3914: Collect Diagnostic Bundle option does not work on older environments
- The Collect Diagnostic Bundle menu option in Impala Virtual
Warehouses does not work for older environments:
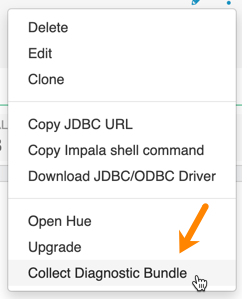
- Data caching:
- This feature is limited to 200 GB per executor, multiplied by the total number of executors.
- Sessions with Impala continue to run for 15 minutes after the connection is disconnected.
- When a connection to Impala is disconnected, the session continues to run for 15 minutes in
case the user or client can reconnect to the same session again by presenting the
session_token. After 15 minutes, the client must re-authenticate to Impala to establish a new connection.
UI Issues
- DWX-14610 Upgrade icon indicates the Database Catalog is the latest version, but might be incorrect for a few seconds
- The cluster fetches data regularly in particular time intervals, or when an action is triggered. Inbetween this time interval, which is very brief, the cluster might not be updated, but will be refreshed in a few seconds.
Technical Service Bulletins
- TSB 2024-723: Hue RAZ is using logger role to Read and Upload/Delete (write) files
- When using Cloudera Data Hub for Public Cloud (Data Hub) on
Amazon Web Services (AWS), users can use the Hue File Browser feature to access the
filesystem, and if permitted, read and write directly to the related S3 buckets. As
AWS does not provide fine-grained access control, Cloudera Data Platform
administrators can use the Ranger Authorization Service (RAZ) capability to take the
S3 filesystem, and overlay it with user and group specific permissions, making it
easier to allow certain users to have limited permissions, without having to grant
those users permissions to the entire S3 bucket.
This bulletin describes an issue when using RAZ with Data Hub, and attempting to use fine-grained access control to allow certain users write permissions.
Through RAZ, an administrator may, for a particular user, specify permissions more limited than what AWS provides for an S3 bucket, allowing the user to have read/write (or other similar fine grained access) permissions on only a subset of the files and directories within that bucket. However, under specific conditions, it is possible for such user to be able to read and write to the entire S3 bucket through Hue, due to Hue using the logger role (which will have full read/write to the S3 bucket) when using Data Hub with a RAZ enabled cluster. This problem also can affect the Hue service itself, by affecting proper access to home directories causing the service role to not start.
The root cause of this issue is, when accessing Amazon cloud resources, Hue uses the AWS Boto SDK library. This AWS Boto library has a bug that restricts permissions in certain AWS regions in such a way that it provides access to users who should not have it, regardless of RAZ settings. This issue only affects users in specific AWS regions, listed below, and it does not affect all AWS customers.
- Knowledge article
-
For the latest update on this issue see the corresponding Knowledge Article: TSB 2024-723: Hue Raz is using logger role to Read and Upload/Delete (write) files.
- TSB 2024-743: Restoration of the Database Catalog can be incomplete due to an incorrect Hue Query Processor configuration in CDW
- Cloudera Data Warehouse (CDW) customers using the CDW Automated Backup/Restore feature might encounter
an issue with the restoration of the Database Catalog, if
the hue-query-processor.jsonconfiguration file of the Database Catalog has been edited. Even a minor edit to thehue-query-processor.jsonconfiguration file can result in this failure.During the restoration process the Database Catalog will be created, but it will fail to start after a short period of time, and the Database Catalog will be in a
Inside the Kubernetes Cluster (Azure Kubernetes Service on Azure / Elastic Kubernetes Service on AWS) the StatefulSet of Hue Query Processor (hue-query-processor) is inBad Healthstate on the CDW User Interface.CrashLoop. This is indicated with the following log in the Hue Query Processor StatefulSet Pod:SQL State : 3D000 Error Code : 0 Message : FATAL: database "warehouse-1707832123-abcd_hueqpdb" does not exist at org.flywaydb.core.internal.jdbc.JdbcUtils.openConnection(JdbcUtils.java:65) - Knowledge article
-
For the latest update on this issue see the corresponding Knowledge Article: TSB 2024-743: Restoration of the Database Catalog can be incomplete due to an incorrect Hue Query Processor configuration in CDW.
- TSB 2024-745: Impala returns incorrect results for Iceberg V2 tables when optimized operator is being used in CDW
- Cloudera Data Warehouse (CDW) customers using Apache Impala (Impala) to read Apache Iceberg (Iceberg) V2 tables can encounter an issue of Impala returning incorrect results when the optimized V2 operator is used. The optimized V2 operator is enabled by default in the affected versions below. The issue only affects Iceberg V2 tables that have position delete files.
- Knowledge article
-
For the latest update on this issue see the corresponding Knowledge Article: TSB 2024-745: Impala returns incorrect results for Iceberg V2 tables when optimized operator is being used in CDW.
- TSB 2024-746: Concurrent compactions and modify statements can corrupt Iceberg tables
- Apache Hive (Hive) and Apache Impala (Impala) modify statements
(
DELETE/UPDATE/MERGE) on Apache Iceberg (Iceberg) V2 tables can corrupt the tables if there is a concurrent table compaction from Apache Spark. The issue happens when the compaction and modify statement run in parallel, and when the compaction job commits before the modify statement. In this case the position delete files of the modify statement still point to the old files. This means the following in case ofDELETEstatements- Deleting records pointing to old files have no effect
UPDATE/MERGEstatements- Deleting records pointing to old files have no effect
- The table will also have the newly added data records
- Rewritten records will still be active
This issue does not affect Apache NiFi (NiFi) and Apache Flink (Flink) as these components write equality delete files.
- Knowledge article
-
For the latest update on this issue see the corresponding Knowledge article: TSB 2024-746: Concurrent compactions and modify statements can corrupt Iceberg tables.
- TSB 2024-752: Dangling delete issue in Spark rewrite_data_files procedure causes incorrect results for Iceberg V2 tables
- The Spark Iceberg library includes two procedures -
rewrite_data_filesandrewrite_position_delete_files. The current implementation ofrewrite_data_fileshas a limitation that the position delete files are not deleted and still tracked by the table metadata, even if they no longer refer to an active data file. This is called the dangling delete problem. To solve this, therewrite_position_delete_filesprocedure is implemented in the Spark Iceberg library to remove these old “dangling” position delete files.Due to the dangling delete limitation, when an Iceberg table with dangling deletes is queried in Impala, Impala tries to optimize
select count(*) from iceberg_tablequery to return the results using stats. This optimization returns incorrect results.The following conditions must be met for this issue to occur:
- All delete files in the Iceberg table are “dangling”
- This would occur immediately after running Spark
rewrite_data_filesAND- Before any further delete operations are performed on the table OR
- Before Spark
rewrite_position_delete_filesis run on the table
- This would occur immediately after running Spark
- Only stats optimized plain
select count(*) from iceberg_tablequeries are affected. For example, the query should not have:- Any
WHEREclause -
Any
GROUP BYclause -
Any
HAVINGclause
- Any
For more information, see the Apache Iceberg documentation.
Remove dangling deletes: After
rewrite_data_files, position delete records pointing to the rewritten data files are not always marked for removal, and can remain tracked by the live snapshot metadata of the table. This is known as the dangling delete problem. - All delete files in the Iceberg table are “dangling”
- Knowledge article
- For the latest update on this issue see the corresponding Knowledge article: TSB 2024-752: Dangling delete issue in Spark rewrite_data_files procedure causes incorrect results for Iceberg V2 tables.
- TSB 2024-758: Truncate command on Iceberg V2 branches cause unintentional data deletion
- When working with Apache Hive (Hive) and Apache Iceberg (Iceberg) V2 tables, using the
TRUNCATEstatement may lead to unintended data deletion. This issue arises when thetruncatecommand is applied to a branch of an Iceberg table. Instead of truncating the branch itself, the command affects the original (main) table, which results in unintended loss of data. - Knowledge article
- For the latest update on this issue see the corresponding Knowledge article: TSB 2024-758: Truncate command on Iceberg V2 branches cause unintentional data deletion