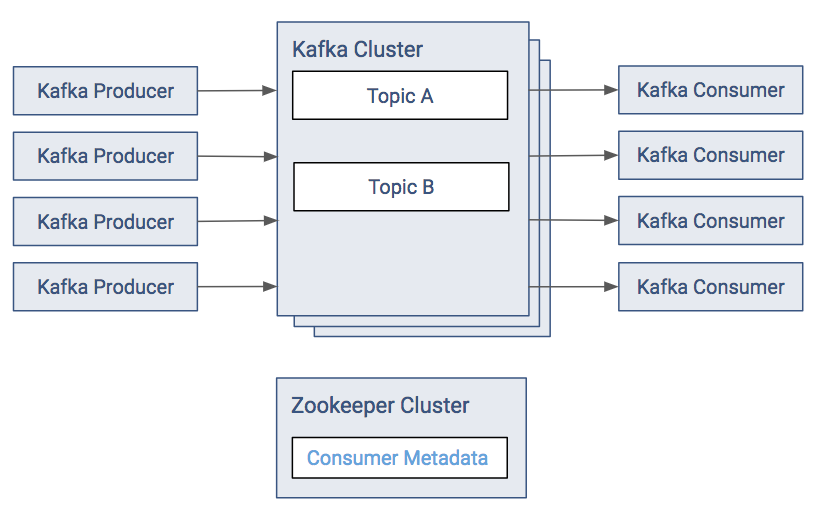
Kafka Clients
Kafka clients are created to read data from and write data to the Kafka system. Clients can be producers, which publish content to Kafka topics. Clients can be subscribers, which read content from Kafka topics.
Commands for Client Interactions
Assuming you have Kafka running on your cluster, here are some commands that describe the typical steps you would need to exercise Kafka functionality:
- Create a topic
-
kafka-topics --create --zookeeper zkinfo --replication-factor 1 --partitions 1 --topic testwhere the ZooKeeper connect string zkinfo is a comma-separated list of the Zookeeper nodes in host: port format.
- Validate the topic was created successfully
-
kafka-topics --list --zookeeper zkinfo - Produce messages
-
The following command can be used to publish a message to the Kafka cluster. After the command, each typed line is a message that is sent to Kafka. After the last message, send an EOF or stop the command with Ctrl-D.
$ kafka-console-producer --broker-list kafkainfo --topic test My first message. My second message. ^D
where kafkainfo is a comma-separated list of the Kafka brokers in host:port format. Using more than one makes sure that the command can find a running broker.
- Consume messages
-
The following command can be used to subscribe to a message from the Kafka cluster.
kafka-console-consumer --bootstrap-server kafkainfo --topic test --from-beginningThe output shows the same messages that you entered during your producer.
- Set a ZooKeeper root node
-
It’s possible to use a root node (chroot) for all Kafka nodes in ZooKeeper by setting a value for zookeeper.chroot in Cloudera Manager. Append this value to the end of your ZooKeeper connect string.
Set chroot in Cloudera Manager:
zookeeper.chroot=/kafka
Form the ZooKeeper connect string as follows:
--zookeeper zkinfo/kafka
If you set chroot and then use only the host and port in the connect string, you'll see the following exception:
InvalidReplicationFactorException: replication factor: 3 larger than available brokers: 0
Kafka Producers
Kafka producers are the publishers responsible for writing records to topics. Typically, this means writing a program using the KafkaProducer API. To instantiate a producer:
KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfig);
Most of the important producer settings, and mentioned below, are in the configuration passed by this constructor.
Serialization of Keys and Values
For each producer, there are two serialization properties that must be set, key.serializer (for the key) and value.serializer (for the value). You can write custom code for serialization or use one of the ones already provided by Kafka. Some of the more commonly used ones are:
- ByteArraySerializer: Binary data
- StringSerializer: String representations
Managing Record Throughput
There are several settings to control how many records a producer accumulates before actually sending the data to the cluster. This tuning is highly dependent on the data source. Some possibilities include:
- batch.size: Combine this fixed number of records before sending data to the cluster.
- linger.ms: Always wait at least this amount of time before sending data to the cluster; then send however many records has accumulated in that time.
- max.request.size: Put an absolute limit on data size sent. This technique prevents network congestion caused by a single transfer request containing a large amount of data relative to the network speed.
- compression.type: Enable compression of data being sent.
- retries: Enable the client for retries based on transient network errors. Used for reliability.
Acknowledgments
The full write path for records from a producer is to the leader partition and then to all of the follower replicas. The producer can control which point in the path triggers an acknowledgment. Depending on the acks setting, the producer may wait for the write to propagate all the way through the system or only wait for the earliest success point.
Valid acks values are:
- 0: Do not wait for any acknowledgment from the partition (fastest throughput).
- 1: Wait only for the leader partition response.
- all: Wait for follower partitions responses to meet minimum (slowest throughput).
Partitioning
In Kafka, the partitioner determines how records map to partitions. Use the mapping to ensure the order of records within a partition and manage the balance of messages across partitions. The default partitioner uses the entire key to determine which partition a message corresponds to. Records with the same key are always mapped to the same partition (assuming the number of partitions does not change for a topic). Consider writing a custom partitioner if you have information about how your records are distributed that can produce more efficient load balancing across partitions. A custom partitioner lets you take advantage of the other data in the record to control partitioning.
If a partitioner is not provided to the KafkaProducer, Kafka uses a default partitioner.
The ProducerRecord class is the actual object processed by the KafkaProducer. It takes the following parameters:
- Kafka Record: The key and value to be stored.
- Intended Destination: The destination topic and the specific partition (optional).
Kafka Consumers
Kafka consumers are the subscribers responsible for reading records from one or more topics and one or more partitions of a topic. Consumers subscribing to a topic can happen manually or automatically; typically, this means writing a program using the KafkaConsumer API.
To instantiate a consumer:
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(consumerConfig);
The KafkaConsumer class has two generic type parameters. Just as producers can send data (the values) with keys, the consumer can read data by keys. In this example both the keys and values are strings. If you define different types, you need to define a deserializer to accommodate the alternate types. For deserializers you need to implement the org.apache.kafka.common.serialization.Deserializer interface.
The most important configuration parameters that we need to specify are:
- bootstrap.servers: A list of brokers to initially connect to. List 2 to 3 brokers; you don't needed to list the full cluster.
- group.id: Every consumer belongs to a group. That way they’ll share the partitions of a topic.
- key.deserializer/value.deserializer: Specify how to convert the Java representation to a sequence of bytes to send data through the Kafka protocol.
Subscribing to a topic
Subscribing to a topic using the subscribe() method call:
kafkaConsumer.subscribe(Collections.singletonList(topic), rebalanceListener);
Here we specify a list of topics that we want to consume from and a 'rebalance listener.' Rebalancing is an important part of the consumer's life. Whenever the cluster or the consumers’ state changes, a rebalance will be issued. This will ensure that all the partitions are assigned to a consumer.
After subscribing to a topic, the consumer polls to see if there are new records:
while (true) {
data = kafkaConsumer.poll();
// do something with 'data'
}
The poll returns multiple records that can be processed by the client. After processing the records the client commits offsets synchronously, thus waiting until processing completes before continuing to poll.
The last important point is to save the progress. This can be done by the commitSync() and commitAsync() methods respectively.
PLACEHOLDER FOR CODE SNIPPET
Auto commit is not recommended; manual commit is appropriate in the majority of use cases.
Groups and Fetching
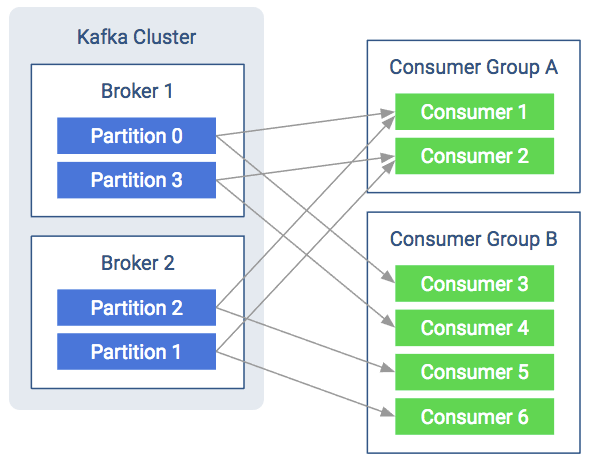
Kafka consumers are usually assigned to a group. This happens statically by setting the group.id configuration property in the consumer configuration. Consuming with groups will result in the consumers balancing the load in the group. That means each consumer will have their fair share of partitions. Also it can never be more consumers than partitions as that way there would be idling consumers.
As shown in the figure below, both consumer groups share the partitions and each partition multicasts messages to both consumer groups. The consumers pull messages from the broker instead of the broker periodically pushing what is available. This helps the consumer as it won’t be overloaded and it can query the broker at its own speed. Furthermore, to avoid tight looping, it uses a so called “long-poll”. The consumer sends a fetch request to poll for data and receives a reply only when enough data accumulates on the broker.
Protocol between Consumer and Broker
This section details how the protocol works, what messages are going on the wire and how that contributes to the overall behavior of the consumer. When discussing the internals of the consumers, there are a couple of basic terms to know:
- Heartbeat
- When the consumer is alive and is part of the consumer group, it sends heartbeats. These are short periodic messages that tell the brokers that the consumer is alive and everything is fine.
- Session
- Often one missing heartbeat is not a big deal, but how do you know if a consumer is not sending heartbeats for long enough to indicate a problem? A session is such a time interval. If the consumer didn’t send any heartbeats for longer than the session, the broker can consider the consumer dead and remove it from the group.
- Coordinator
- The special broker which manages the group on the broker side is called the coordinator. The coordinator handles heartbeats and assigns the leader. Every group has a coordinator that organizes the startup of a consumer group and assist whenever a consumer leaves the group.
- Leader
- The leader consumer is elected by the coordinator. Its job is to assign partitions to every consumer in the group at startup or whenever a consumer leaves or joins the group. The leader holds the assignment strategy, it is decoupled from the broker. That means consumers can reconfigure the partition assignment strategy without restarting the brokers.
Startup Protocol
As mentioned before, the consumers are working usually in groups. So a major part of the startup process is spent with figuring out the consumer group.
At startup, the first step is to match protocol versions. It is possible that the broker and the consumer are of different versions (the broker is older and the consumer is newer, or vice versa). This matching is done by the API_VERSIONS request.
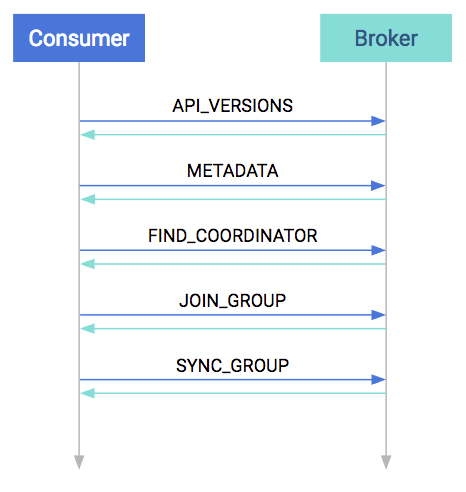
The next step is to collect cluster information, such as the addresses of all the brokers (prior to this point we used the bootstrap server as a reference), partition counts, and partition leaders. This is done in the METADATA request.
After acquiring the metadata, the consumer has the information needed to join the group. By this time on the broker side, a coordinator has been selected per consumer group. The consumers must find their coordinator with the FIND_COORDINATOR request.
After finding the coordinator, the consumer(s) are ready to join the group. Every consumer in the group sends their own member-specific metadata to the coordinator in the JOIN_GROUP request. The coordinator waits until all the consumers have sent their request, then assigns a leader for the group. At the response plus the collected metadata are sent to the leader, so it knows about its group.
The remaining step is to assign partitions to consumers and propagate this state. Similar to the previous request, all consumers send a SYNC_GROUP request to the coordinator; the leader provides the assignments in this request. After it receives the sync request from each group member, the coordinator propagates this member state in the response. By the end of this step, the consumers are ready and can start consuming.
Consumption Protocol
When consuming, the first step is to query where should the consumer start. This is done in the OFFSET_FETCH request. This is not mandatory: the consumer can also provide the offset manually. After this, the consumer is free to pull data from the broker. Data consumption happens in the FETCH requests. These are the long-pull requests. They are answered only when the broker has enough data; the request can be outstanding for a longer period of time.
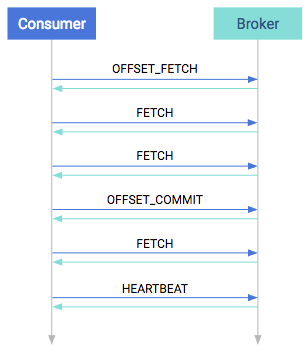
From time to time, the application has to either manually or automatically save the offsets in an OFFSET_COMMIT request and send heartbeats too in the HEARTBEAT requests. The first ensures that the position is saved while the latter ensures that the coordinator knows that the consumer is alive.
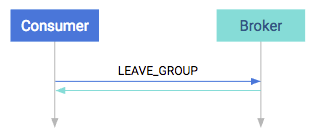
Rebalancing Partitions
You may notice that there are multiple points in the protocol between consumers and brokers where failures can occur. There are points in the normal operation of the system where you need to change the consumer group assignments. For example, to consume a new partition or to respond to a consumer going offline. The process or responding to cluster information changing is called rebalance. It can occur in the following cases:
- A consumer leaves. It can be a software failure where the session times out or a connection stalls for too long, but it can also be a graceful shutdown.
- A consumer joins. It can be a new consumer but an old one that just recovered from a software failure (automatically or manually).
- Partition is adjusted. A partition can simply go offline because of a broker failure or a partition coming back online. Alternatively an administrator can add or remove partitions to/from the broker. In these cases the consumers must reassign who is consuming.
- The cluster is adjusted. When a broker goes offline, the partitions that are lead by this broker will be reassigned. In turn the consumers must rebalance so that they consume from the new leader. When a broker comes back, then eventually a preferred leader election happens which restores the original leadership. The consumers must follow this change as well.
On the consumer side, this rebalance is propagated to the client via the ConsumerRebalanceListener interface. It has two methods. The first, onPartitionsRevoked, will be invoked when any partition goes offline. This call happens before the changes would reflect in any of the consumers, so this is the chance to save offsets if manual offset commit is used. On the other hand onPartitionsAssigned is invoked after partition reassignment. This would allow for the programmer to detect which partitions are currently assigned to the current consumer. Complete examples can be found in the development section.
Consumer Configuration Properties
There are some very important configurations that any user of Kafka must know:
- heartbeat.interval.ms: The interval of the heartbeats. For example, if the heartbeat interval is set to 3 seconds, the consumer sends a short heartbeat message to the broker every 3 seconds to indicate that it is alive.
- session.timeout.ms: The consumer tells this timeout to the coordinator. This is used to control the heartbeats and remove the dead consumers. If it’s set to 10 seconds, the consumer can miss sending 2 heartbeats, assuming the previous heartbeat setting. If we increase the timeout, the consumer has more room for delays but the broker notices lagging consumers later.
- max.poll.interval.ms: It is a very important detail: the consumers must maintain polling and should never do long-running processing. If a consumer is taking too much time between two polls, it will be detached from the consumer group. We can tune this configuration according to our needs. Note that if a consumer is stuck in processing, it will be noticed later if the value is increased.
- request.timeout.ms: Generally every request has a timeout. This is an upper bound that the client waits for the server’s response. If this timeout elapses, then retries might happen if the number of retries are not exhausted.
Retries
In Kafka retries typically happen on only for certain kinds of errors. When a retriable error is returned, the clients are constrained by two facts: the timeout period and the backoff period.
The timeout period tells how long the consumer can retry the operation. The backoff period how often the consumer should retry. There is no generic approach for "number of retries." Number of retries are usually controlled by timeout periods.
Kafka Clients and ZooKeeper
The default consumer model provides the metadata for offsets in the Kafka cluster. There is a topic named __consumer_offsets that the Kafka Consumers write their offsets to.
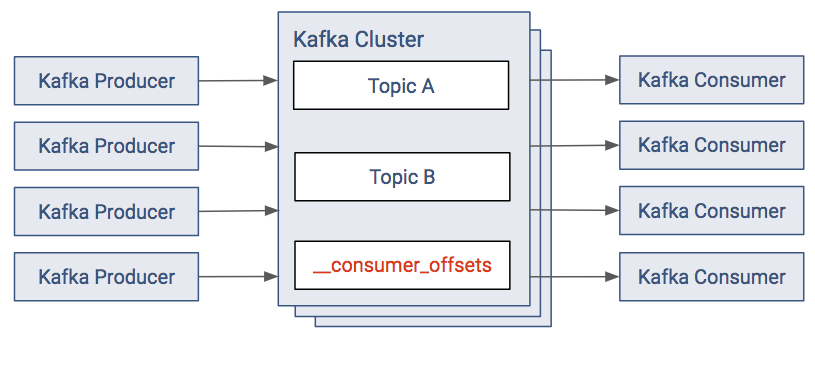
In releases before version 2.0 of CDK Powered by Apache Kafka, the same metadata was located in ZooKeeper. The new model removes the dependency and load from Zookeeper. In the old approach:
- The consumers save their offsets in a "consumer metadata" section of ZooKeeper.
- With most Kafka setups, there are often a large number of Kafka consumers. The resulting client load on ZooKeeper can be significant, therefore this solution is discouraged.