Modifying Custom Metadata
You can add and modify the following custom metadata associated with entities: display name, description, tags, and user-defined name-value pairs using the Navigator Metadata UI, MapReduce service and job properties, HDFS metadata files, and the Navigator Metadata API.
Continue reading:
- Modifying Custom Metadata Using the Navigator UI
- Modifying MapReduce Custom Metadata
- Example: Setting Properties Dynamically
- Modifying HDFS Custom Metadata Using Metadata Files
- Modifying HDFS and Hive Custom Metadata Using the Navigator API
- HDFS PUT Example for /user/admin/input_dir Directory
- HDFS POST Example for /user/admin/input_dir Directory
- Hive POST Example for total_emp Column
Modifying Custom Metadata Using the Navigator UI
- Run a search in the Navigator UI.
- Click an entity link returned in the search. The entity Details tab displays.
- To the left of the Details tab, click . The Edit Custom Metadata dialog box drops down.
- Edit any of the fields. Press Enter or Tab to create new tag entries. In the following screenshot, a description, the tags
occupations and salaries, and property year with value 2015 have been added to the file sample_07.csv:
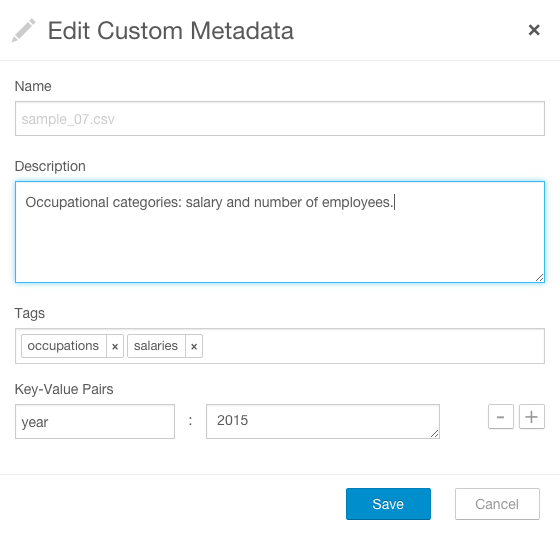
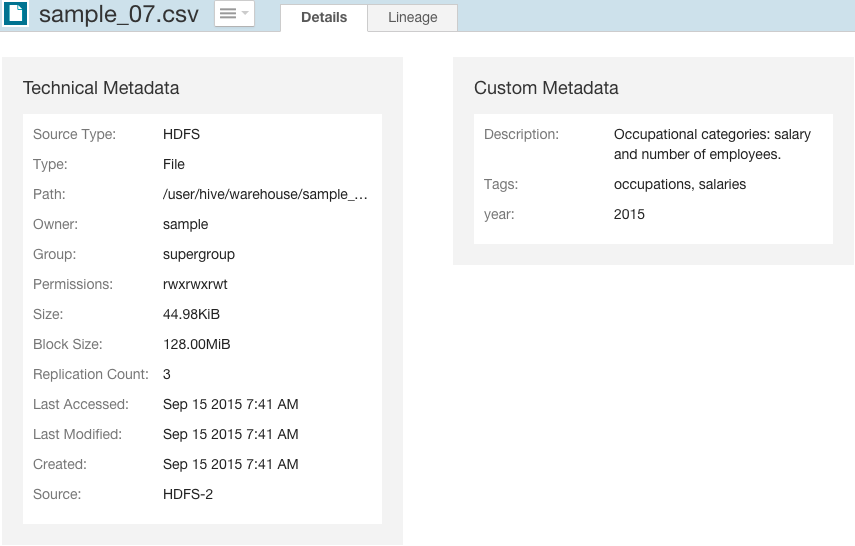
You can specify special characters (for example, ".", " ") in the name, but it will make searching for the entity more difficult as some characters collide with special characters in the search syntax. - Click Save. The new metadata appears in the Custom Metadata pane:
Modifying MapReduce Custom Metadata
You can associate custom metadata with arbitrary configuration parameters to MapReduce jobs and job executions. The specific configuration parameters to be extracted by Navigator can be specified statically or dynamically.
- Do one of the following:
- Select .
- On the Status tab of the tab, in Cloudera Management Service table, click the Cloudera Management Service link.
- Click the Configuration tab.
- Select .
- Select .
- Click Navigator Metadata Server Advanced Configuration Snippet for cloudera-navigator.properties.
- Specify values for the following properties:
- nav.user_defined_properties = comma-separated list of user-defined property names
- nav.tags = comma-separated list of property names that serve as tags. The property nav.tags can point to multiple property names that serve as tags, but each of those property names can only specify a single tag.
- Click Save Changes to commit the changes.
- Click the Instances tab.
- Restart the role.
- In the MapReduce job configuration, set the value of the property names you specified in step 6.
- Specify one or more of the following properties in a job configuration:
- job properties (type:OPERATION)
- nav.job.user_defined_properties = comma-separated list of user-defined property names
- nav.job.tags = comma-separated list of property names that serve as tags
- job execution properties (type:OPERATION_EXECUTION)
- nav.jobexec.user_defined_properties = comma-separated list of user-defined property names
- nav.jobexec.tags = comma-separated list of property names that serve as tags
- job properties (type:OPERATION)
- In the MapReduce job configuration, set the value of the property names you specified in step 1.
Example: Setting Properties Dynamically
Add the tags onetag and twotag to a job:- Dynamically add the job_tag1 and job_tag2 properties:
conf.set("nav.job.tags", "job_tag1, job_tag2"); - Set the job_tag1 property to onetag:
conf.set("job_tag1", "onetag"); - Set the job_tag2 property to twotag:
conf.set("job_tag2", "twotag");
- Dynamically add the job_tag property:
conf.set("nav.jobexec.tags","job_exec_tag"); - Set the job_exec_tag property to atag:
conf.set("job_exec_tag", "atag");
- Dynamically add the user-defined property bar:
conf.set("nav.job.user_defined_properties", "bar"); - Set the value of the user-defined property foo to bar:
conf.set("foo", "bar")
Modifying HDFS Custom Metadata Using Metadata Files
You can add tags and properties to HDFS entities using metadata files. The reasons to use metadata files are to assign metadata to entities in bulk and to create metadata before the metadata is extracted. A metadata file is a JSON file with the following structure:
{
"name" : "aName",
"description" : "a description",
"properties" : {
"prop1" : "value1", "prop2" : "value2"
},
"tags" : [ "tag1" ]
}
- File - The path of the metadata file must be .filename.navigator. For example, to apply properties to the file /user/test/file1.txt, the metadata file path is /user/test/.file1.txt.navigator.
- Directory - The path of the metadata file must be dirpath/.navigator. For example, to apply properties to the directory /user, the metadata path must be /user/.navigator.
Modifying HDFS and Hive Custom Metadata Using the Navigator API
You can use the Cloudera Navigator Data Management API to modify the metadata of HDFS or Hive entities whether or not the entities have been extracted. If an entity has been extracted at the time the API is called, the metadata will be applied immediately. If the entity has not been extracted, you can preregister metadata which is then applied once the entity is extracted. Metadata is saved regardless of whether or not a matching entity is extracted, and Navigator does not perform any cleanup of unused metadata.
curl http://Navigator_Metadata_Server_host:port/api/v8/entities/?query=-internalType:* -u username:password -X GET
The metadata provided via the API overwrites existing metadata. If, for example, you call the API with an empty name and description, empty array for tags, and empty dictionary for properties, the call removes this metadata. If you leave out the tags or properties fields, the existing values remain unchanged.
Modifying metadata using HDFS metadata files and the metadata API at the same time is not supported. You must use one or the other, because the two methods behave slightly differently. Metadata specified in files is merged with existing metadata whereas the API overwrites metadata. Also, the updates provided by metadata files wait in a queue before being merged, but API changes are committed immediately. This means there may be some inconsistency if a metadata file is being merged around the same time the API is in use.
You modify metadata using either the PUT or POST method. Use the PUT method if the entity has been extracted and the POST method to preregister metadata. The syntax of the methods are:- PUT
curl http://Navigator_Metadata_Server_host:port/api/v8/entities/identity -u username:password -X PUT -H\ "Content-Type: application/json" -d '{properties}'where identity is an entity ID and properties are:- name: name metadata
- description: description metadata
- tags: tag metadata
- properties: property metadata
- POST
curl http://Navigator_Metadata_Server_host:port/api/v8/entities/ -u username:password -X POST -H\ "Content-Type: application/json" -d '{properties}'where properties are:- sourceId (required): An existing source ID. After the first extraction, you
can retrieve source IDs using the call:
curl http://Navigator_Metadata_Server_host:port/api/v8/entities/?query=type:SOURCE -u username:password -X GET
For example:[ ... { "identity" : "a09b0233cc58ff7d601eaa68673a20c6", "originalName" : "HDFS-1", "sourceId" : null, "firstClassParentId" : null, "parentPath" : null, "extractorRunId" : null, "name" : "HDFS-1", "description" : null, "tags" : null, "properties" : null, "clusterName" : "Cluster 1", "sourceUrl" : "hdfs://hostname:8020", "sourceType" : "HDFS", "sourceExtractIteration" : 4935, "type" : "SOURCE", "internalType" : "source" }, ...If you have multiple services of a given type, you must specify the source ID that contains the entity you're expecting it to match. - parentPath: The path of the parent entity, defined as:
- HDFS file or directory: fileSystemPath of the parent directory (do not provide this field if the entity being affected is the root directory). Example parentPath for /user/admin/input_dir: /user/admin. If you add metadata to a directory, the metadata does not propagate to any files and folders in that directory.
- Hive database: If you are updating database metadata, you do not specify this field.
- Hive table or view: The name of database containing the table or view. Example for a table in the default database: default.
- Hive column: database name/table name/view name. Example for a column in the sample_07 table: default/sample_07.
- originalName (required): The name as defined by the source system.
- HDFS file or directory: name of file or directory (ROOT if the entity is the root directory). Example originalName for /user/admin/input_dir: input_dir.
- Hive database, table, view, or column: the name of the database, table, view, or column.
- Example for default database: default
- Example for sample_07 table: sample_07
- name: name metadata
- description: description metadata
- tags: tag metadata
- properties: property metadata
- sourceId (required): An existing source ID. After the first extraction, you
can retrieve source IDs using the call:
HDFS PUT Example for /user/admin/input_dir Directory
curl http://Navigator_Metadata_Server_host:port/api/v8/entities/e461de8de38511a3ac6740dd7d51b8d0 -u username:password -X PUT -H "Content-Type: application/json"\
-d '{"name":"my_name","description":"My description", "tags":["tag1","tag2"],"properties":{"property1":"value1","property2":"value2"}}'HDFS POST Example for /user/admin/input_dir Directory
curl http://Navigator_Metadata_Server_host:port/api/v8/entities/ -u username:password -X POST -H "Content-Type: application/json"\
-d '{"sourceId":"a09b0233cc58ff7d601eaa68673a20c6", "parentPath":"/user/admin","originalName":"input_dir", "name":"my_name","description":"My description",\
"tags":["tag1","tag2"],"properties":{"property1":"value1","property2":"value2"}}'Hive POST Example for total_emp Column
curl http://Navigator_Metadata_Server_host:port/api/v8/entities/ -u username:password -X POST -H "Content-Type: application/json"\
-d '{"sourceId":"4fbdadc6899638782fc8cb626176dc7b", "parentPath":"default/sample_07","originalName":"total_emp",\
"name":"my_name","description":"My description", "tags":["tag1","tag2"],"properties":{"property1":"value1","property2":"value2"}}'