Managing Metadata
This topic describes tasks for enabling and disabling metadata extraction and purging obsolete metadata.
Enabling and Disabling Metadata Extraction
Minimum Required Role: Navigator Administrator (also provided by Full Administrator)
Enabling Hive Metadata Extraction in a Secure Cluster
The Navigator Metadata Server uses the hue user to connect to the Hive Metastore. The hue user can connect to the Hive Metastore by default. However, if the Hive service Hive Metastore Access Control and Proxy User Groups Override property or the HDFS service Hive Proxy User Groups property have been changed from their default values to settings that prevent the hue user from connecting to the Hive Metastore, Navigator Metadata Server is unable to extract metadata from Hive. If this is the case, modify the Hive service Hive Metastore Access Control and Proxy User Groups Override property or the HDFS service Hive Proxy User Groups property as follows:- Go to the Hive or HDFS service.
- Click the Configuration tab.
- In the Search box, type proxy.
- In the Hive service Hive Metastore Access Control and Proxy User Groups Override or the HDFS service Hive Proxy User Groups
property, click
 to add a new row.
to add a new row.
If more than one role group applies to this configuration, edit the value for the appropriate role group. See Modifying Configuration Properties Using Cloudera Manager.
- Type hue.
- Click Save Changes to commit the changes.
- Restart the service.
Enabling Spark Metadata Extraction
Spark is an unsupported service and by default Spark metadata extraction is disabled. To enable Spark metadata extraction:- Do one of the following:
- Select .
- On the tab, in Cloudera Management Service table, click the Cloudera Management Service link.
- Click the Configuration tab.
- Select .
- In Navigator Metadata Server Advanced Configuration Snippet (Safety Valve) for cloudera-navigator.properties, set the property
nav.spark.extraction.enable=true
If more than one role group applies to this configuration, edit the value for the appropriate role group. See Modifying Configuration Properties Using Cloudera Manager.
- Click Save Changes to commit the changes.
- Restart the role.
Managing Metadata Capacity
Minimum Required Role:: Full Administrator
The metadata maintained by Navigator Metadata Server can grow rapidly and exceed the capacity of the Solr instance storing the data. Navigator Metadata Server purge allows you to delete unwanted metadata to improve performance and reduce noise during search and lineage. Currently purge is available only through the Metadata Server API.
Purging Metadata
The purge method supports deleting the metadata of deleted HDFS entities. Purge is a long-running job that requires exclusive access to the Solr instance and does not allow any other concurrent activities, including extraction.
- Back up the Navigator Metadata Server storage directory.
- Invoke the http://Navigator_Metadata_Server_host:port/api/v9/maintenance/purge endpoint with the following parameters:
For example, the following call purges the metadata of all deleted entities because the number of elapsed minutes is set to 0:
Purge Parameters Parameter Description deleteTimeThresholdMinutes Number of minutes that must have elapsed since an entity was deleted before that entity can be purged. Default: 86400 minutes (60 days).
runtimeCapMinutes Number of minutes that the purge task can run. When this limit is reached, the purge state is saved and the purge task terminates. However, eligible entities may remain and must be purged in another invocation. Default: 720 minutes (12 hours).
$ curl -X POST -u admin:admin "http://Navigator_Metadata_Server_host:port/api/v9/maintenance/purge?deleteTimeThresholdMinutes=0"
Click Continue to refresh the maintenance status. After the purge task starts, it displays status messages about the entities it has purged. For example:
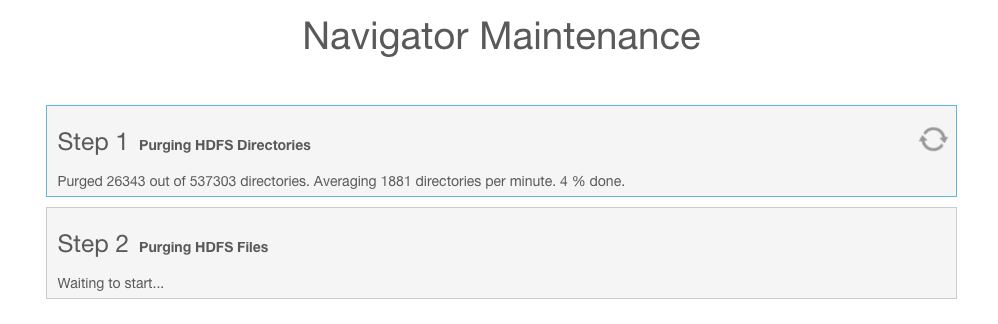
When all tasks have completed, a Continue link displays. Click Continue to return to the Navigator Metadata UI.
Retrieving Purge Status
To view the status of the purge process, invoke the http://Navigator_Metadata_Server_host:port/api/v9/maintenance/running endpoint. For example:$ curl -X GET -u admin:admin "http://Navigator_Metadata_Server_host:port/api/v9/maintenance/running"A result would look similar to:
[{
"id" : 5,
"type" : "PURGE",
"startTime" : "2016-03-10T23:17:41.884Z",
"endTime" : "1970-01-01T00:00:00.000Z",
"status" : "IN_PROGRESS",
"message" : "Purged 2661984 out of 4864714 directories. Averaging 1709 directories per minute.",
"username" : "admin",
"stage" : "HDFS_DIRECTORIES",
"stagePercent" : 54
}]Retrieving Purge History
To view the purge history, invoke the http://Navigator_Metadata_Server_host:port/api/v9/maintenance/history endpoint with the following parameters:| Parameter | Description |
|---|---|
| offset | First purge history entry to retrieve.
Default: 0. |
| limit | Number of history entries to retrieve from the offset.
Default: 100. |
$ curl -X GET -u admin:admin "http://Navigator_Metadata_Server_host:port/api/v9/maintenance/history?offset=0&limit=100"A result would look similar to:
[
{
"id": 1,
"type": "PURGE",
"startTime": "2016-03-09T18:57:43.196Z",
"endTime": "2016-03-09T18:58:33.337Z",
"status": "SUCCESS",
"username": "admin",
"stagePercent": 0
},
{
"id": 2,
"type": "PURGE",
"startTime": "2016-03-09T19:47:39.401Z",
"endTime": "2016-03-09T19:47:40.841Z",
"status": "SUCCESS",
"username": "admin",
"stagePercent": 0
},
{
"id": 3,
"type": "PURGE",
"startTime": "2016-03-10T01:27:39.632Z",
"endTime": "2016-03-10T01:27:46.809Z",
"status": "SUCCESS",
"username": "admin",
"stagePercent": 0
},
{
"id": 4,
"type": "PURGE",
"startTime": "2016-03-10T01:57:40.461Z",
"endTime": "2016-03-10T01:57:41.174Z",
"status": "SUCCESS",
"username": "admin",
"stagePercent": 0
},
{
"id": 5,
"type": "PURGE",
"startTime": "2016-03-10T23:17:41.884Z",
"endTime": "2016-03-10T23:18:06.802Z",
"status": "SUCCESS",
"username": "admin",
"stagePercent": 0
}
]