Hive Replication
Minimum Required Role: BDR Administrator (also provided by Full Administrator)
Hive replication enables you to copy (replicate) your Hive metastore and data from one cluster to another and synchronize the Hive metastore and data set on the destination cluster with the source, based on a specified replication schedule. The destination cluster must be managed by the Cloudera Manager Server where the replication is being set up, and the source cluster can be managed by that same server or by a peer Cloudera Manager Server.
- If the hadoop.proxyuser.hive.groups configuration has been changed to restrict access to the Hive Metastore Server to certain users or groups, the hdfs group or a group containing the hdfs user must also be included in the list of groups specified for Hive replication to work. This configuration can be specified either on the Hive service as an override, or in the core-site HDFS configuration. This applies to configuration settings on both the source and destination clusters.
- If you configured Synchronizing HDFS ACLs and Sentry Permissions on the target cluster for the directory where HDFS data is copied during Hive replication, the permissions that were copied during replication, are overwritten by the HDFS ACL synchronization and are not preserved
- If you are using Kerberos to secure your clusters, see Enabling Replication Between Clusters in Different Kerberos Realms for details about configuring it.
Network Latency and Replication
High latency among clusters can cause replication jobs to run more slowly, but does not cause them to fail. For best performance, latency between the source cluster NameNode and the destination cluster NameNode should be less than 80 milliseconds. (You can test latency using the Linux ping command.) Cloudera has successfully tested replications with latency of up to 360 milliseconds. As latency increases, replication performance degrades.
Host Selection for Hive Replication
If your cluster has Hive clients installed on hosts with limited resources, Hive replication may use these hosts to run commands for the replication, which can cause the performance of the replication to degrade. To improve performance, you can specify the hosts (a ”white list”) to use during replication so that the lower-resource hosts are not used.
- Click .
- Type Hive Replication in the search box.
- Locate the Hive Replication Environment Advanced Configuration Snippet (Safety Valve) property.
- Add the HOST_WHITELIST property. Enter a comma-separated list of hostnames to use for Hive replication. For example:
HOST_WHITELIST=host-1.mycompany.com,host-2.mycompany.com
- Click Save Changes to commit the changes.
Hive Tables and DDL Commands
- If you configure replication of a Hive table and then later drop that table, the table remains on the destination cluster. The table is not dropped when subsequent replications occur.
- If you drop a table on the destination cluster, and the table is still included in the replication job, the table is re-created on the destination during the replication.
- If you drop a table partition or index on the source cluster, the replication job also drops them on the destination cluster.
- If you truncate a table, and the Delete Policy for the replication job is set to Delete to Trash or Delete Permanently, the corresponding data files are deleted on the destination during a replication.
Performance and Scalability Limitations
- Maximum number of databases: 100
- Maximum number of tables per database: 1,000
- Maximum number of partitions per table: 10,000. See Identify Workload Characteristics That Increase Memory Pressure.
- Maximum total number of tables (across all databases): 10,000
- Maximum total number of partitions (across all tables): 100,000
- Maximum number of indexes per table: 100
Hive Replication in Dynamic Environments
To use BDR for Hive replication in environments where the Hive Metastore changes, such as when a database or table gets created or deleted, additional configuration is needed.
- Open the Cloudera Manager Admin Console.
- Search for the HDFS Client Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml property on the source cluster.
- Add the following properties:
- Name: replication.hive.ignoreDatabaseNotFound
Value: true
- Name:replication.hive.ignoreTableNotFound
Value: true
- Name: replication.hive.ignoreDatabaseNotFound
- Save the changes.
- Restart the HDFS service.
Configuring Replication of Hive Data
- Verify that your cluster conforms to one of the Supported Replication Scenarios.
- If the source cluster is managed by a different Cloudera Manager server than the destination cluster, configure a peer relationship.
- Do one of the following:
- From the Backup tab, select Replications.
- From the Clusters tab, go to the Hive service and select .
The Schedules tab of the Replications page displays.
- Select .
- Use the Source drop-down list to select the cluster with the Hive service you want to replicate.
- Use the Destination drop-down list to select the destination for the replication. If there is only one Hive service managed by Cloudera Manager available as a destination, this is specified as the destination. If more than one Hive service is managed by this Cloudera Manager, select from among them.
- Select a Schedule:
- Immediate - Run the schedule Immediately.
- Once - Run the schedule one time in the future. Set the date and time.
- Recurring - Run the schedule periodically in the future. Set the date, time, and interval between runs.
- Leave Replicate All checked to replicate all the Hive databases from the source. To replicate only selected databases, uncheck this option and enter
the database name(s) and tables you want to replicate.
- You can specify multiple databases and tables using the plus symbol to add more rows to the specification.
- You can specify multiple databases on a single line by separating their names with the pipe (|) character. For example: mydbname1|mydbname2|mydbname3.
- Regular expressions can be used in either database or table fields, as described in the following table:
Regular Expression Result [\w].+
Any database or table name. (?!myname\b).+
Any database or table except the one named myname. db1|db2 [\w_]+
All tables of the db1 and db2 databases. db1 [\w_]+
Click the "+" button and then enter
db2 [\w_]+
All tables of the db1 and db2 databases (alternate method).
- Use the Advanced Options section to specify an export location, modify the parameters of the MapReduce job that will perform the replication, and set
other options. You can select a MapReduce service (if there is more than one in your cluster) and change the following parameters:
- Uncheck the Replicate HDFS Files checkbox to skip replicating the associated data files.
- Uncheck the Replicate Impala Metadata checkbox to skip replicating Impala metadata. (This option is checked by default.) See Impala Metadata Replication.
- The Force Overwrite option, if checked, forces overwriting data in the destination metastore if incompatible changes are detected. For example, if the destination metastore was modified, and a new partition was added to a table, this option forces deletion of that partition, overwriting the table with the version found on the source.
- By default, Hive metadata is exported to a default HDFS location (/user/${user.name}/.cm/hive) and then imported from this HDFS file to the destination Hive metastore. In this example, user.name is the process user of the HDFS service on the destination cluster. To override the default HDFS location for this export file, specify a path in the Export Path field.
- By default, Hive HDFS data files (for example, /user/hive/warehouse/db1/t1) are replicated to a location relative to "/" (in this example, to /user/hive/warehouse/db1/t1). To override the default, enter a path in the HDFS Destination Path field. For example, if you enter /ReplicatedData, the data files would be replicated to /ReplicatedData/user/hive/warehouse/db1/t1.
- Select the MapReduce Service to use for this replication (if there is more than one in your cluster).
- To specify the user that should run the MapReduce job, use the Run As Username option. By default, MapReduce jobs run as hdfs. To run the MapReduce job as a different user, enter the user name. If you are using Kerberos, you must provide a user name here, and it must have an ID greater than 1000.
- Scheduler Pool - The name of a resource pool. The value you enter is used by the MapReduce Service you specified when Cloudera Manager executes the MapReduce job for the replication. The job specifies the value using one of these properties:
- MapReduce - Fair scheduler: mapred.fairscheduler.pool
- MapReduce - Capacity scheduler: queue.name
- YARN - mapreduce.job.queuename
- Log Path - An alternative path for the logs.
- Maximum Map Slots and Maximum Bandwidth- Limits for the number of map slots and for bandwidth per mapper. The default is 100 MB.
- Abort on Error - Whether to abort the job on an error. By selecting the check box, files copied up to that point remain on the destination, but no additional files will be copied. Abort on Error is off by default.
- Skip Checksum Checks - Whether to skip checksum checks, which are performed by default.
Checksums are used for two purposes:
- To skip replication of files that have already been copied. If Skip Checksum Checks is selected, the replication job skips copying a file if the file lengths and modification times are identical between the source and destination clusters. Otherwise, the job copies the file from the source to the destination.
- To redundantly verify the integrity of data. However, checksums are not required to guarantee accurate transfers between clusters. HDFS data transfers are protected by checksums during transfer and storage hardware also uses checksums to ensure that data is accurately stored. These two mechanisms work together to validate the integrity of the copied data.
- Replication Strategy - Whether file replication should be static (the default) or dynamic. Static replication distributes file replication tasks among the mappers up front to achieve a uniform distribution based on file sizes. Dynamic replication distributes file replication tasks in small sets to the mappers, and as each mapper processes its tasks, it dynamically acquires and processes the next unallocated set of tasks.
- Delete Policy - Whether files that were on the source should also be deleted from the destination directory. Options include:
- Keep Deleted Files - Retains the destination files even when they no longer exist at the source. (This is the default.).
- Delete to Trash - If the HDFS trash is enabled, files are moved to the trash folder.
- Delete Permanently - Uses the least amount of space; use with caution.
- Preserve - Whether to preserve the Block Size, Replication Count, and Permissions as they exist on the source file system, or to use the settings as configured on the destination file system. By default, settings are preserved on the source.
- Alerts - Whether to generate alerts for various state changes in the replication workflow. You can alert On Failure, On Start, On Success, or On Abort (when the replication workflow is aborted).
- Click Save Schedule.
The replication task appears as a row in the Replications Schedule table. See Viewing Replication Schedules.
Viewing Replication Schedules
The Replications Schedules page displays a row of information about each scheduled replication job. Each row also displays recent messages regarding the last time the Replication job ran.
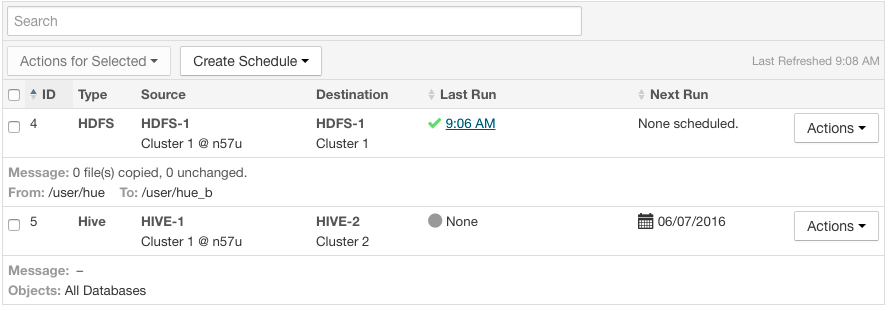
Only one job corresponding to a replication schedule can occur at a time; if another job associated with that same replication schedule starts before the previous one has finished, the second one is canceled.
You can limit the replication jobs that are displayed by selecting filters on the left. If you do not see an expected schedule, adjust or clear the filters. Use the search box to search the list of schedules for path, database, or table names.
| Column | Description |
|---|---|
| ID | An internally generated ID number that identifies the schedule. Provides a convenient way to identify a schedule.
Click the ID column label to sort the replication schedule table by ID. |
| Type | The type of replication scheduled, either HDFS or Hive. |
| Source | The source cluster for the replication. |
| Destination | The destination cluster for the replication. |
| Objects | Displays on the bottom line of each row, depending on the type of replication:
For example: 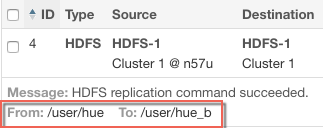 |
| Last Run | The date and time when the replication last ran. Displays None if the scheduled
replication has not yet been run. Click the date and time link to view the Replication History page for the replication.
Displays one of the following icons:
Click the Last Run column label to sort the Replication Schedules table by the last run date. |
| Next Run | The date and time when the next replication is scheduled, based on the schedule parameters specified for the schedule.
Hover over the date to view additional details about the scheduled replication.
Click the Next Run column label to sort the Replication Schedules table by the next run date. |
| Actions | The following items are available from the Action button:
|
 - Successful. Displays the date and time of the last run replication.
- Successful. Displays the date and time of the last run replication. - Failed. Displays the date and time of a failed replication.
- Failed. Displays the date and time of a failed replication. - None. This scheduled replication has not yet run.
- None. This scheduled replication has not yet run.
- While a job is in progress, the Last Run column displays a spinner and progress bar, and each stage of the replication task is indicated in the message beneath the job's row. Click the Command Details link to view details about the execution of the command.
- If the job is successful, the number of files copied is indicated. If there have been no changes to a file at the source since the previous job, then that file is not copied. As a result, after the initial job, only a subset of the files may actually be copied, and this is indicated in the success message.
- If the job fails, the
 icon displays.
icon displays. - To view more information about a completed job, select . See Viewing Replication History.
Enabling, Disabling, or Deleting A Replication Schedule
When you create a new replication schedule, it is automatically enabled. If you disable a replication schedule, it can be re-enabled at a later time.
-
- Click in the row for a replication schedule.
-or-
-
- Select one or more replication schedules in the table by clicking the check box the in the left column of the table.
- Click .
Viewing Replication History
You can view historical details about replication jobs on the Replication History page.
To view the history of a replication job:
- Select to go to the Replication Schedules page.
- Locate the row for the job.
- Click .

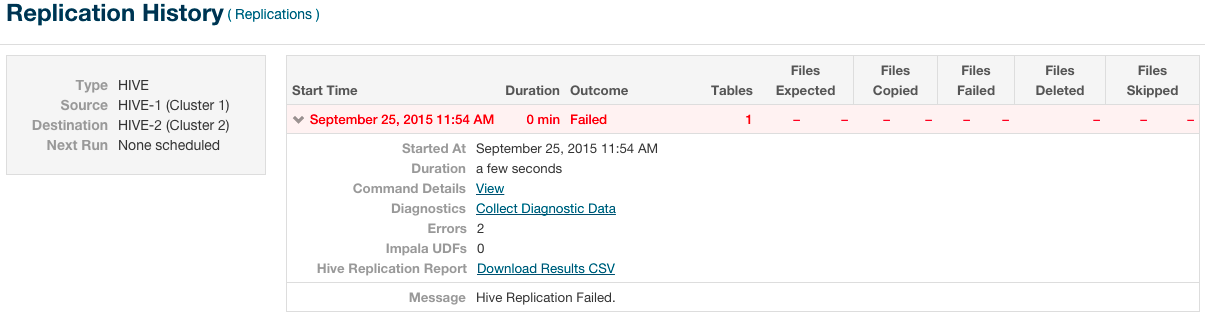
The Replication History page displays a table of previously run replication jobs with the following columns:
| Column | Description |
|---|---|
| Start Time | Time when the replication job started.
Click
|
| Duration | Amount of time the replication job took to complete. |
| Outcome | Indicates success or failure of the replication job. |
| Files Expected | Number of files expected to be copied, based on the parameters of the replication schedule. |
| Files Copied | Number of files actually copied during the replication. |
| Tables | (Hive only) Number of tables replicated. |
| Files Failed | Number of files that failed to be copied during the replication. |
| Files Deleted | Number of files that were deleted during the replication. |
| Files Skipped | Number of files skipped during the replication. The replication process skips files that already exist in the destination and have not changed. |
