Managing the Sentry Service
This topic describes basic Sentry terminology and the Sentry privilege model:
Terminology
- An object is an entity protected by Sentry's authorization rules. The objects supported in the current release are server, database, table, URI, collection, and config.
- A role is a collection of rules for accessing a given object.
- A privilege is granted to a role to govern access to an object. Sentry allows you to assign the SELECT privilege to columns (only
for Hive and Impala). Supported privileges are:
Valid privilege types and the objects they apply to Privilege Object ALL SERVER, TABLE, DB, URI, COLLECTION, CONFIG INSERT DB, TABLE SELECT DB, TABLE, COLUMN - A user is an entity that is permitted by the authentication subsystem to access the service. This entity can be a Kerberos principal, an LDAP userid, or an artifact of some other supported pluggable authentication system.
- A group connects the authentication system with the authorization system. It is a collection of one or more users who have been granted one or more authorization roles. Sentry allows a set of roles to be configured for a group.
- A configured group provider determines a user’s affiliation with a group. The current release supports HDFS-backed groups and locally configured groups.
Privilege Model
- Allows any user to execute show function, desc function, and show locks.
- Allows the user to see only those tables, databases, collections, and configurations for which the user has privileges.
- Requires a user to have the necessary privileges on the URI to execute HiveQL operations that specify a location. Examples of such operations include LOAD, IMPORT, and EXPORT.
- Sentry provides column-level access control for tables in Hive and Impala. You can assign the SELECT privilege on a subset of columns in a table.
- In Beeline, you can grant privileges on an object that doesn't exist. For example, you can grant role1 on table1 and then create table1.
For more information, see Authorization Privilege Model for Hive and Impala, Authorization Privilege Model for Cloudera Search, and Configuring Kafka to Use Sentry Authorization.
User to Group Mapping
Minimum Required Role: Configurator (also provided by Cluster Administrator, Full Administrator)
- Sentry - Groups are looked up on the host the Sentry Server runs on.
- Hive - Groups are looked up on the hosts running HiveServer2 and the Hive Metastore.
- Impala - Groups are looked up on the Catalog Server and on all of the Impala daemon hosts.
Group mappings in Sentry can be summarized as in the figure below.
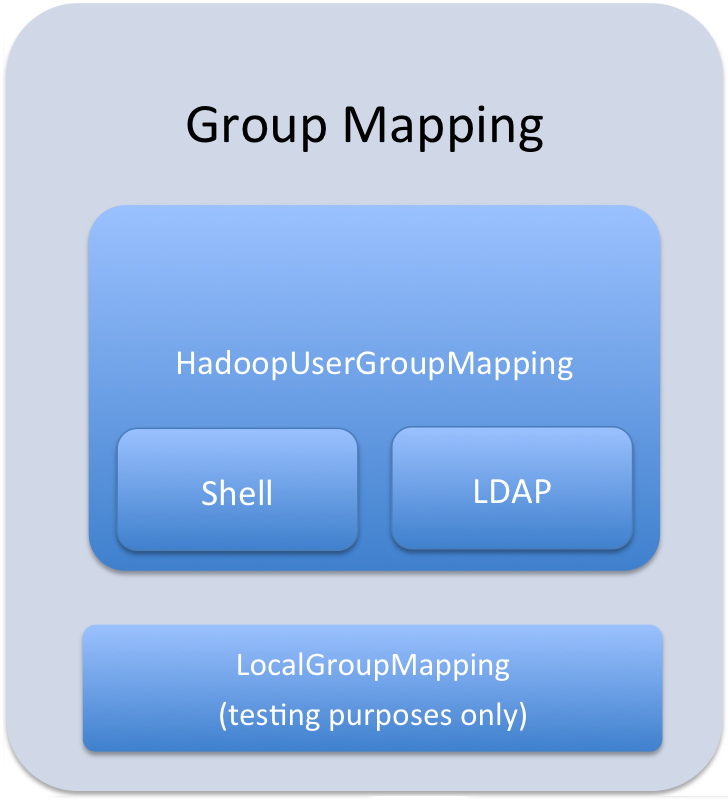
The Sentry service only uses HadoopUserGroup mappings. See Configuring LDAP Group Mappings for details on configuring LDAP group mappings in Hadoop.
Accessing Sentry-Secured Data Outside Hive/Impala
However, there are scenarios where fully vetted and reviewed jobs will also need to access the data stored in the Hive warehouse. A typical scenario would be a secured MapReduce transformation job that is executed automatically as an application user. In such cases it's important to know that the user executing this job will also have full access to the data in the Hive warehouse.
Scenario One: Authorizing Jobs
Problem
A reviewed, vetted, and automated job requires access to the Hive warehouse and cannot use Hive/Impala to access the data.
Solution
Create a group which contains hive, impala, and the user executing the automated job. For example, if the etl user is executing the automated job, you can create a group called hive-users which contains the hive, impala, and etl users.
$ groupadd hive-users $ usermod -G hive,impala,hive-users hive $ usermod -G hive,impala,hive-users impala $ usermod -G etl,hive-users etlOnce you have added users to the hive-users group, change directory permissions in the HDFS:
$ hadoop fs -chgrp -R hive:hive-users /user/hive/warehouse $ hadoop fs -chmod -R 770 /user/hive/warehouse
Scenario Two: Authorizing Group Access to Databases
Problem
One group of users, grp1 should have full access to the database, db1, outside of Sentry. The database, db1 should not be accessible to any other groups, outside of Sentry. Sentry should be used for all other authorization needs.
Solution
$ usermod -G hive,impala,grp1 hive $ usermod -G hive,impala,grp1 impalaThen change group ownerships of all directories and files in db1 to grp1, and modify directory permissions in the HDFS. This example is only applicable to local groups on a single host.
$ hadoop fs -chgrp -R hive:grp1 /user/hive/warehouse/db1.db $ hadoop fs -chmod -R 770 /user/hive/warehouse/db1.db
Configuring Sentry to Enable BDR Replication
Cloudera recommends the following steps when configuring Sentry and data replication is enabled.
- Group membership should be managed outside of Sentry (as OS and LDAP groups are typically managed) and replication for them also should be handled outside of Cloudera Manager.
- In Cloudera Manager, set up HDFS replication for the Sentry files of the databases that are being replicated (separately using Hive/Impala replication).
- On the source cluster, to avoid manual fix up of URI privileges, ensure that the URIs for the data are the same on both the source and target cluster
- On the target cluster, for the databases being replicated, avoid adding more privileges (adding tables specific to target cluster may sometimes require adding extra privileges to allow access to those tables).