Metadata
The Cloudera Navigator Metadata component manages metadata about the entities in a CDH cluster and relations between the entities.
The Navigator metadata schema defines the types of metadata that are available for each entity type it supports. The types of metadata defined by the Navigator Metadata component include: the name of an entity, the service that manages or uses the entity, type, path to the entity, date and time of creation, access, and modification, size, owner, purpose, and relations—parent-child, data flow, and instance of—between entities.
For example, the following shows the property sheet of a file entity: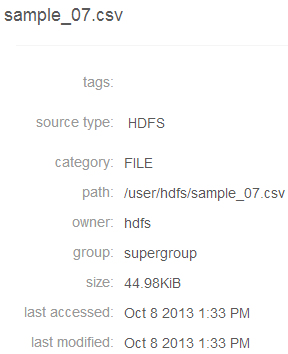
- technical metadata - metadata defined when entities are extracted. You cannot modify technical metadata.
- custom metadata - metadata added to extracted entities. You can add and modify custom metadata before or after entities are extracted.
Continue reading:
Metadata Extraction
The Navigator Metadata Server extracts metadata for the following resource types from the listed servers:- HDFS - Extracts HDFS metadata at the next scheduled extraction run after an HDFS checkpoint. However, if you have high availability enabled, metadata is extracted as soon as it is written to the JournalNodes.
- Hive - Extracts database and table metadata from the Hive Metastore Server.
- MapReduce - Extracts job metadata from the JobTracker. The default setting in Cloudera Manager retains a maximum of five jobs, which means if you run more than five jobs between Navigator extractions, the Navigator Metadata Server would extract the five most recent jobs.
- Oozie - Extracts Oozie workflows from the Oozie Server.
- Pig - Extracts Pig script runs from the JobTracker or Job History Server.
- Sqoop 1 - Extracts database and table metadata from the Hive Metastore Server.
- YARN - Extracts job metadata from the Job History Server.
- HDFS: t0 + extraction poll period + HDFS checkpoint interval (default 1 hour)
- HDFS + HA: t0 + extraction poll period
- Hive: t0 + extraction poll period + Hive maximum wait time (default 60 minutes)
Metadata Indexing
After metadata is extracted it is indexed and made available for searching by an embedded Solr engine. The Solr schema indexes two types of metadata: entity properties and relationship between entities.
You can search entity metadata using the Navigator UI. Relationship metadata is implicitly visible in lineage diagrams and explicitly available in a lineage file.
