Tuning Hive
To maximize performance of your Apache Hive query workloads, you need to optimize cluster configurations, queries, and underlying Hive table design. This includes the following:
- Configure CDH clusters for the maximum allowed heap memory size, load-balance concurrent connections across your CDH Hive components, and allocate adequate memory to support HiveServer2 and Hive metastore operations.
- Review your Hive query workloads to make sure queries are not overly complex, that they do not access large numbers of Hive table partitions, or that they force the system to materialize all columns of accessed Hive tables when only a subset is necessary.
- Review the underlying Hive table design, which is crucial to maximizing the throughput of Hive query workloads. Do not create thousands of table partitions that might cause queries containing JOINs to overtax HiveServer2 and the Hive metastore. Limit column width, and keep the number of columns under 1,000.
The following sections provide details on implementing these best practices to maximize performance for deployments of HiveServer2 and the Hive metastore.
Heap Size and Garbage Collection for Hive Components
This section provides guidelines for setting HiveServer2 and Hive metastore memory and garbage-collection properties.
Memory Recommendations
HiveServer2 and the Hive metastore require sufficient memory to run correctly. The default heap size of 256 MB for each component is inadequate for production workloads. Consider the following guidelines for sizing the heap for each component, based on your cluster size.
| Number of Concurrent Connections | HiveServer2 Heap Size Recommended Range | Hive Metastore Heap Size Recommended Range |
|---|---|---|
|
Up to 40 concurrent connections Cloudera recommends splitting HiveServer2 into multiple instances and load-balancing once you start allocating over 16 GB to HiveServer2. This reduces the impact of Java garbage collection on active processing by the service. |
12 - 16 GB | 12 - 16 GB |
| Up to 20 concurrent connections | 6 - 12 GB | 10 - 12 GB |
| Up to 10 concurrent connections | 4 - 6 GB | 4 - 10 GB |
| One connection | 4 GB | 4 GB |
In addition, the Beeline CLI should use a heap size of at least 2 GB.
Set the PermGen space for Java garbage collection to 512 MB for all.
Configuring Heap Size and Garbage Collection
Using Cloudera Manager
To configure heap size and garbage collection for HiveServer2:
- To set heap size, go to .
- Set Java Heap Size of HiveServer2 in Bytes to the desired value, and click Save Changes.
- To set garbage collection, go to .
-
Set the PermGen space for Java garbage collection to 512M, the type of garbage collector used (ConcMarkSweepGC or ParNewGC), and enable or disable the garbage collection overhead limit in Java Configuration Options for HiveServer2.
The following example sets the PermGen space to 512M, uses the new Parallel Collector, and disables the garbage collection overhead limit:
-XX:MaxPermSize=512M -XX:+UseParNewGC -XX:-UseGCOverheadLimit
- From the Actions drop-down menu, select Restart to restart the HiveServer2 service.
To configure heap size and garbage collection for the Hive metastore:
- To set heap size, go to .
- Set Java Heap Size of Hive Metastore Server in Bytes to the desired value, and click Save Changes.
- To set garbage collection, go to .
- Set the PermGen space for Java garbage collection to 512M, the type of garbage collector used (ConcMarkSweepGC or ParNewGC), and enable or disable the garbage collection overhead limit in Java Configuration Options for Hive Metastore Server. For an example of this setting, see step 4 above for configuring garbage collection for HiveServer2.
- From the Actions drop-down menu, select Restart to restart the Hive Metastore service.
To configure heap size and garbage collection for the Beeline CLI:
- To set heap size, go to .
- Set Client Java Heap Size in Bytes to at least 2 GiB and click Save Changes.
- To set garbage collection, go to .
-
Set the PermGen space for Java garbage collection to 512M in Client Java Configuration Options.
The following example sets the PermGen space to 512M and specifies IPv4:
-XX:MaxPermSize=512M -Djava.net.preferIPv4Stack=true
- From the Actions drop-down menu, select Restart to restart the client service.
Using the Command Line
To configure the heap size for HiveServer2 and Hive metastore, set the -Xmx parameter in the HADOOP_OPTS variable to the desired maximum heap size in /etc/hive/hive-env.sh.
To configure the heap size for the Beeline CLI, set the HADOOP_HEAPSIZE environment variable in /etc/hive/hive-env.sh before starting the Beeline CLI.
- HiveServer2 uses 12 GB heap.
- Hive metastore uses 12 GB heap.
- Hive clients use 2 GB heap.
if [ "$SERVICE" = "cli" ]; then
if [ -z "$DEBUG" ]; then
export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xmx12288m -Xms12288m
-XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:+UseParNewGC -XX:-UseGCOverheadLimit"
else
export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xmx12288m -Xms12288m
-XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:-UseGCOverheadLimit"
fi
fi
export HADOOP_HEAPSIZE=2048You can use either the Concurrent Collector or the new Parallel Collector for garbage collection by passing -XX:+useConcMarkSweepGC or -XX:+useParNewGC in the HADOOP_OPTS lines above. To enable the garbage collection overhead limit, remove the -XX:-UseGCOverheadLimit setting or change it to -XX:+UseGCOverheadLimit.
Set the PermGen space for Java garbage collection to 512M for all in the JAVA-OPTS environment variable. For example:
set JAVA_OPTS="-Xms256m -Xmx1024m -XX:PermSize=512m -XX:MaxPermSize=512m"
HiveServer2 Performance Tuning and Troubleshooting
- Many Hive table partitions.
- Many concurrent connections to HS2.
- Complex Hive queries that access significant numbers of table partitions.
Symptoms Displayed When HiveServer2 Heap Memory is Full
When HS2 heap memory is full, you might experience the following issues:
- HS2 service goes down and new sessions fail to start.
- HS2 service seems to be running fine, but client connections are refused.
- Query submission fails repeatedly.
- HS2 performance degrades and displays the following behavior:
- Query submission delays
- Long query execution times
Troubleshooting
HiveServer2 Service Crashes
If the HS2 service crashes frequently, confirm that the problem relates to HS2 heap exhaustion by inspecting the HS2 instance stdout log.
- In Cloudera Manager, from the home page, go to .
- In the Instances page, click the link of the HS2 node that is down:
HiveServer2 Link on the Cloudera Manager Instances Page
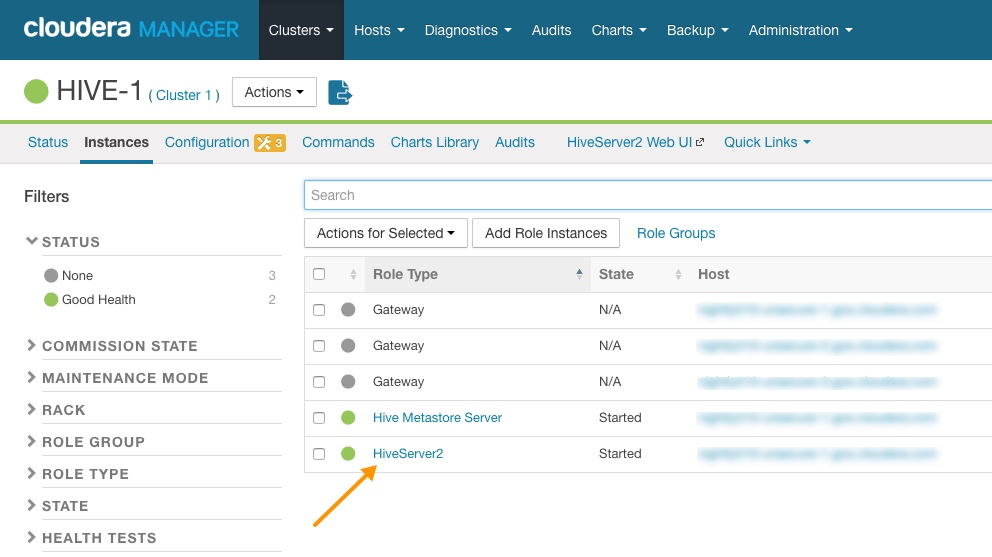
- On the HiveServer2 page, click Processes.
- On the HiveServer2 Processes page, scroll down to the Recent Log Entries and click the link to the Stdout log.
Link to the Stdout Log on the Cloudera Manager Processes Page
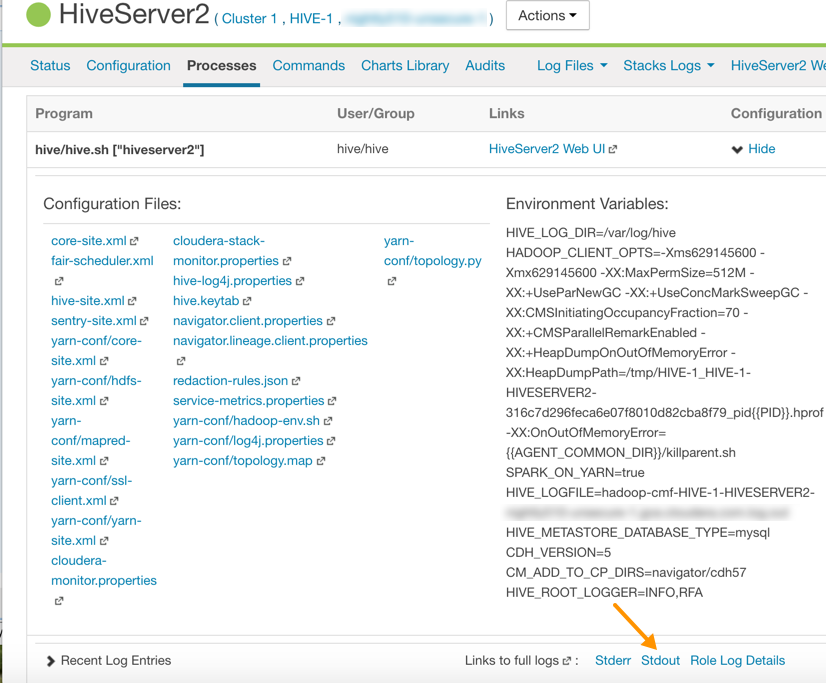
- In the stdout.log, look for the following error:
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="/usr/lib64/cmf/service/common/killparent.sh" # Executing /bin/sh -c "/usr/lib64/cmf/service/common/killparent.sh"
Video: Troubleshooting HiveServer2 Service Crashes
For more information about configuring Java heap size for HiveServer2, see the following video:
After you start the video, click YouTube in the lower right corner of the player window to watch it on YouTube where you can resize it for clearer viewing.
HiveServer2 General Performance Problems or Connections Refused
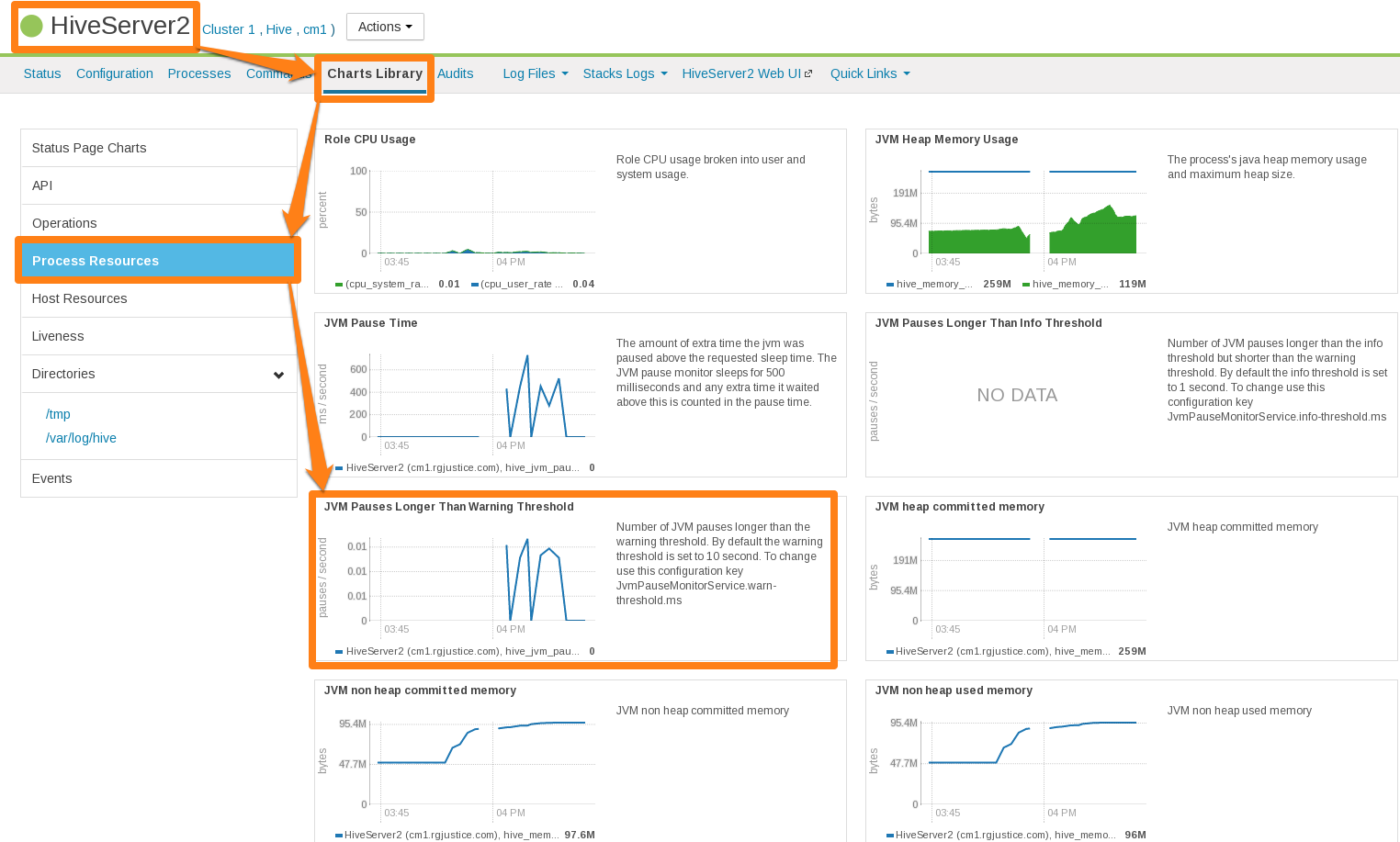
For general HS2 performance problems or if the service refuses connections, but does not completely hang, inspect the Cloudera Manager process charts:
- In Cloudera Manager, navigate to .
- In the Process Resources section of the Charts Library page, view the JVM Pause Time and the JVM Pauses Longer Than Warning Threshold charts for signs that JVM has paused to manage resources. For example:
Cloudera Manager Chart Library Page for Process Resources
HiveServer2 Performance Best Practices
High heap usage by the HS2 process can be caused by Hive queries accessing high numbers of table partitions (greater than several thousand), high levels of concurrency, or other Hive workload characteristics described in Identify Workload Characteristics That Increase Memory Pressure.
HiveServer2 Heap Size Configuration Best Practices
Optimal HS2 heap size configuration depends on several factors, including workload characteristics, number of concurrent clients, and the partitioning of underlying Hive tables. To resolve HS2 memory-related issues, confirm that the HS2 heap size is set properly for your environment.
- In CDH 5.7 and higher, Cloudera Manager starts the HS2 service with 4 GB heap size by default unless hosts have insufficient memory. However, the heap size on lower versions of CDH or
upgraded clusters might not be set to this recommended value. To raise the heap size to at least 4 GB:
- In Cloudera Manager, go to .
- Set Java Heap Size of HiveServer2 in Bytes to 4 GiB and click Save Changes.
- From the Actions drop-down menu, select Restart to restart the HS2 service.
If HS2 is already configured to run with 4 GB or greater heap size and there are still performance issues, workload characteristics may be causing memory pressure. Increase heap size to reduce memory pressure on HS2. Cloudera does not recommend exceeding 16 GB per instance because of long garbage collection pause times. See Identify Workload Characteristics That Increase Memory Pressure for tips to optimize query workloads to reduce the memory requirements on HS2. Cloudera recommends splitting HS2 into multiple instances and load-balancing once you start allocating over 16 GB to HS2.
- If workload analysis does not reveal any major issues, or you can only address workload issues over time, consider the following options:
- Increase the heap size on HS2 in incremental steps. Cloudera recommends increasing the heap size by 50% from the current value with each step. If you have increased the heap size to 16 GB and issues persist, contact Cloudera Support.
- Reduce the number of services running on the HS2 host.
- Load-balance workloads across multiple HS2 instances as described in How the Number of Concurrent Connections Affect HiveServer2 Performance.
- Add more physical memory to the host or upgrade to a larger server.
How the Number of Concurrent Connections Affect HiveServer2 Performance
The number of concurrent connections can impact HS2 in the following ways:
-
High number of concurrent queries
High numbers of concurrent queries increases the connection count. Each query connection consumes resources for the query plan, number of table partitions accessed, and partial result sets. Limiting the number of concurrent users can help reduce overall HS2 resource consumption, especially limiting scenarios where one or more "in-flight" queries returns large result sets.
How to resolve:
- Load-balance workloads across multiple HS2 instances by using HS2 load balancing, which is available in CDH 5.7 and later. Cloudera recommends that you determine the total number of HS2 servers on a cluster by dividing the expected maximum number of concurrent users on a cluster by 40. For example, if 400 concurrent users are expected, 10 HS2 instances should be available to support them. See Configuring HiveServer2 High Availability in CDH for setup instructions.
- Review usage patterns, such as batch jobs timing or Oozie workflows, to identify spikes in the number of connections that can be spread over time.
-
Many abandoned Hue sessions
Users opening numerous browser tabs in Hue causes multiple sessions and connections. In turn, all of these open connections lead to multiple operations and multiple result sets held in memory for queries that finish processing. Eventually, this situation leads to a resource crisis.
How to resolve:
- Reduce the session timeout duration for HS2, which minimizes the impact of abandoned Hue sessions. To reduce session timeout duration, modify these configuration parameters as follows:
- hive.server2.idle.operation.timeout=7200000
The default setting for this parameter is 21600000 or 6 hours.
- hive.server2.idle.session.timeout=21600000
The default setting for this parameter is 43200000 or 12 hours.
To set these parameters in Cloudera Manager, go to , and then search for each parameter.
- hive.server2.idle.operation.timeout=7200000
- Reduce the size of the result set returned by adding filters to queries. This minimizes memory pressure caused by "dangling" sessions.
- Reduce the session timeout duration for HS2, which minimizes the impact of abandoned Hue sessions. To reduce session timeout duration, modify these configuration parameters as follows:
Identify Workload Characteristics That Increase Memory Pressure
If increasing the heap size based on configuration guidelines does not improve performance, analyze your query workloads to identify characteristics that increase memory pressure on HS2. Workloads with the following characteristics increase memory requirements for HS2:
- Queries that access a large number of table partitions:
- Cloudera recommends that a single query access no more than 10,000 table partitions. If joins are also used in the query, calculate the combined partition count accessed across all tables.
- Look for queries that load all table partitions in memory to execute. This can substantially add to memory pressure. For example, a query that accesses a partitioned table with the
following SELECT statement loads all partitions of the target table to execute:
SELECT * FROM <table_name> LIMIT 10;
How to resolve:
- Add partition filters to queries to reduce the total number of partitions that are accessed. To view all of the partitions processed by a query, run the EXPLAIN DEPENDENCY clause, which is explained in the Apache Hive Language Manual.
- Set the hive.metastore.limit.partition.request parameter to 1000 to limit the maximum number of partitions accessed from a single table in a query. See
the Apache wiki for information about setting this parameter. If this parameter is
set, queries that access more than 1000 partitions fail with the following error:
MetaException: Number of partitions scanned (=%d) on table '%s' exceeds limit (=%d)
Setting this parameter protects against bad workloads and identifies queries that need to be optimized. To resolve the failed queries:- Apply the appropriate partition filters.
- Override the limit on a per-query basis.
- Increase the cluster-wide limit beyond 1000, if needed, but note that this adds memory pressure to HiveServer2 and the Hive metastore.
- If the accessed table is not partitioned, see this Cloudera Engineering Blog post, which explains how to partition Hive tables to improve query performance. Choose columns or dimensions for partitioning based upon usage patterns. Partitioning tables too much causes data fragmentation, but partitioning too little causes queries to read too much data. Either extreme makes querying inefficient. Typically, a few thousand table partitions is fine.
- Wide tables or columns:
- Memory requirements are directly proportional to the number of columns and the size of the individual columns. Typically, a wide table contains over 1,000 columns. Wide tables or columns can cause memory pressure if the number of columns is large. This is especially true for Parquet files because all data for a row-group must be in memory before it can be written to disk. Avoid wide tables when possible.
-
Large individual columns also cause the memory requirements to increase. Typically, this happens when a column contains free-form text or complex types.
How to resolve:
- Reduce the total number of columns that are materialized. If only a subset of columns are required, avoid SELECT * because it materializes all columns.
- Instead, use a specific set of columns. This is particularly efficient for wide tables that are stored in column formats. Specify columns explicitly instead of using SELECT *, especially for production workloads.
- High query complexity
Complex queries usually have large numbers of joins, often over 10 joins per query. HS2 heap size requirements increase significantly as the number of joins in a query increases.
How to resolve:
- Make sure that partition filters are specified on all partitioned tables that are involved in JOINs.
- Whenever possible, break queries into multiple smaller queries with intermediate temporary tables.
- Improperly written user-defined functions (UDFs)
Improperly written UDFs can exert significant memory pressure on HS2.
How to resolve:
- Understand the memory implications of the UDF and test it before using it in production environments.
General Best Practices
The following general best practices help maintain a healthy Hive cluster:
- Review and test queries in a development or test cluster before running them in a production environment. Monitor heap memory usage while testing.
- Redirect and isolate any untested, unreviewed, ad-hoc, or "dangerous" queries to a separate HS2 instance that is not critical to batch operation.
Optimizing Hive Write Performance on Amazon S3
In CDH 5.9 and later, support has been added to improve write performance to tables and partitions whose underlying files reside on the S3 filesystem (see Hive-14270). When the optimization is enabled, Hive writes intermediate data to HDFS when performing inserts to tables or partitions on S3, avoiding expensive S3 copy operations. The configuration is off by default when you upgrade, but can be enabled with the following configuration steps.
See Configuring Transient Hive ETL Jobs to Use the Amazon S3 Filesystem for information about setting up Hive to use S3.
Configuring Optimized Hive S3 Write Performance
To enable this optimization, you must set the following two configuration parameters:
- hive.blobstore.use.as.scratchdir=false
This parameter changes the Hive scratch directory from S3 to HDFS.
- hive.exec.copyfile.maxsize=1099511627776
This parameter disables distcp on files that are smaller than 1 TB.
Setting Parameters on a Per-Query Basis
Turn on this optimization feature on a per-query basis by setting these parameters in the query code with the Hive SET command:
set hive.blobstore.use.blobstore.as.scratchdir=false
set hive.exec.copyfile.maxsize=1099511627776;
Setting Parameters as Service-Wide Defaults with Cloudera Manager
Use Cloudera Manager to enable this feature by setting these same two parameters as service-wide defaults by using the HiveServer2 Safety Valve configuration setting for hive-site.xml:
- In the Cloudera Manager Admin Console, go to the Hive service.
- Click the Configuration tab.
- Click the HiveServer2 scope.
- Click the Advanced category.
- Scroll down to the HiveServer2 Advanced Configuration Snippet (Safety Valve) for hive-site.xml and click the plus sign under the last configuration parameter in this section.
- In the new Name and Value fields, type the hive.blobstore.use.blobstore.as.scratchdir parameter name and the false value, respectively.
- Click the plus sign again, and in the Name and Value fields, type the hive.exec.copyfile.maxsize parameter name and the 1099511627776 value.
- Click Save Changes.
Restrictions
The following restrictions apply to this feature:
- CTAS (CREATE TABLE AS SELECT) Queries
Setting these parameters might not improve performance when the following two conditions are true:
- The target table's parent database is created with an HDFS location, and
- The individual CTAS query specifies an S3 location.
Performance gains do not occur if CTAS queries have already staged data in HDFS prior to installing CDH 5.9. However, if the target database of a CTAS query is created with a location that specifies an S3 path, query performance might be improved when CDH 5.9 is installed due to this optimization. Enabling the optimization in either case causes no harm.
- HDFS Encryption
The hive.exec.copyfile.maxsize parameter is also used when copying files between encryption zones for LOAD statements. If you are using HDFS encryption in an environment where performance is critical, Cloudera does not recommend that you change the service-wide value of hive.exec.copyfile.maxsize.
