Registering an AWS environment from the Cloudera UI
Once you’ve met the AWS cloud provider requirements, register your AWS environment.
Before you begin
This assumes that you have already fulfilled the environment prerequisites described in AWS requirements.
Required role: EnvironmentCreator
Steps
- Navigate to the Cloudera Management Console > Environments >
Register environment:
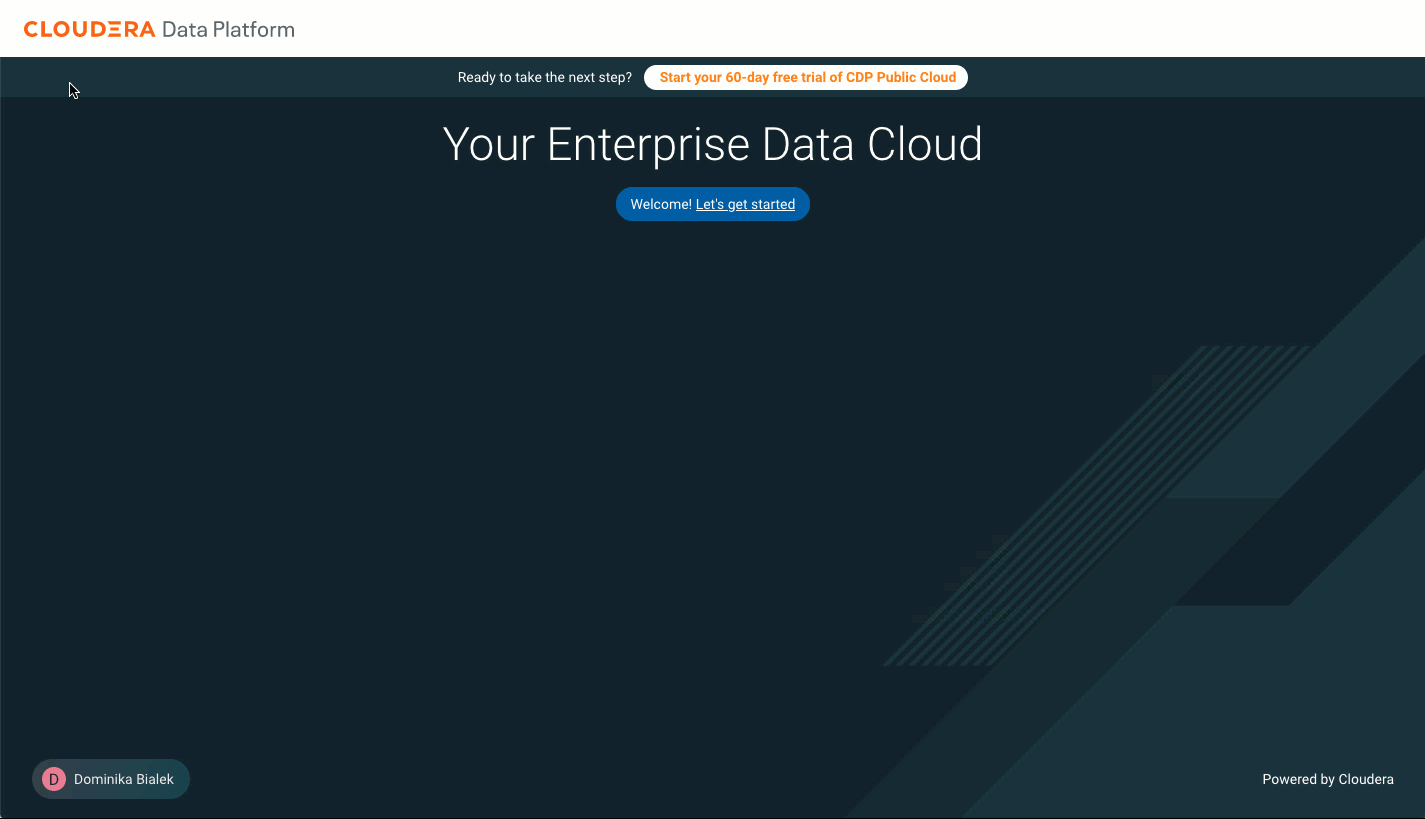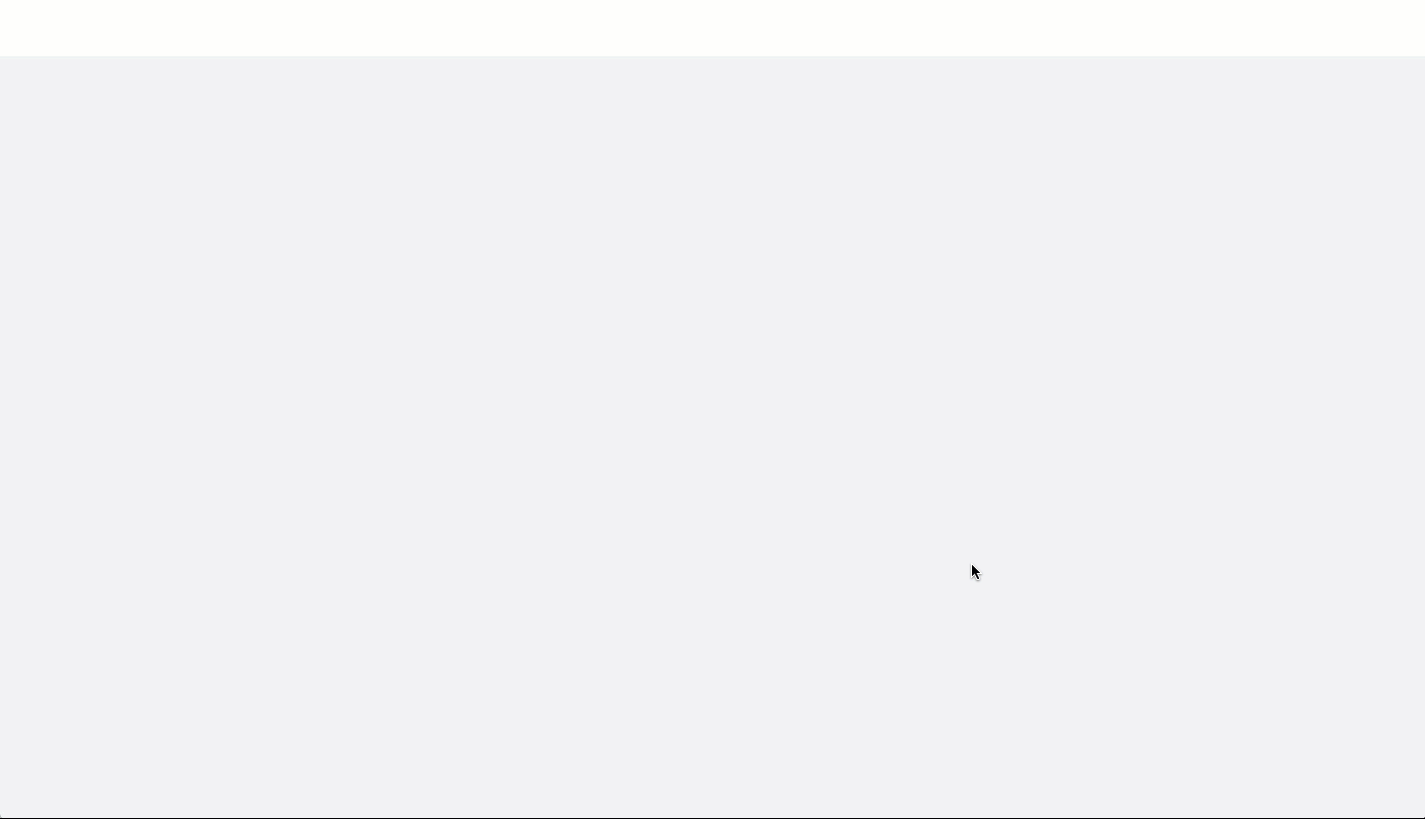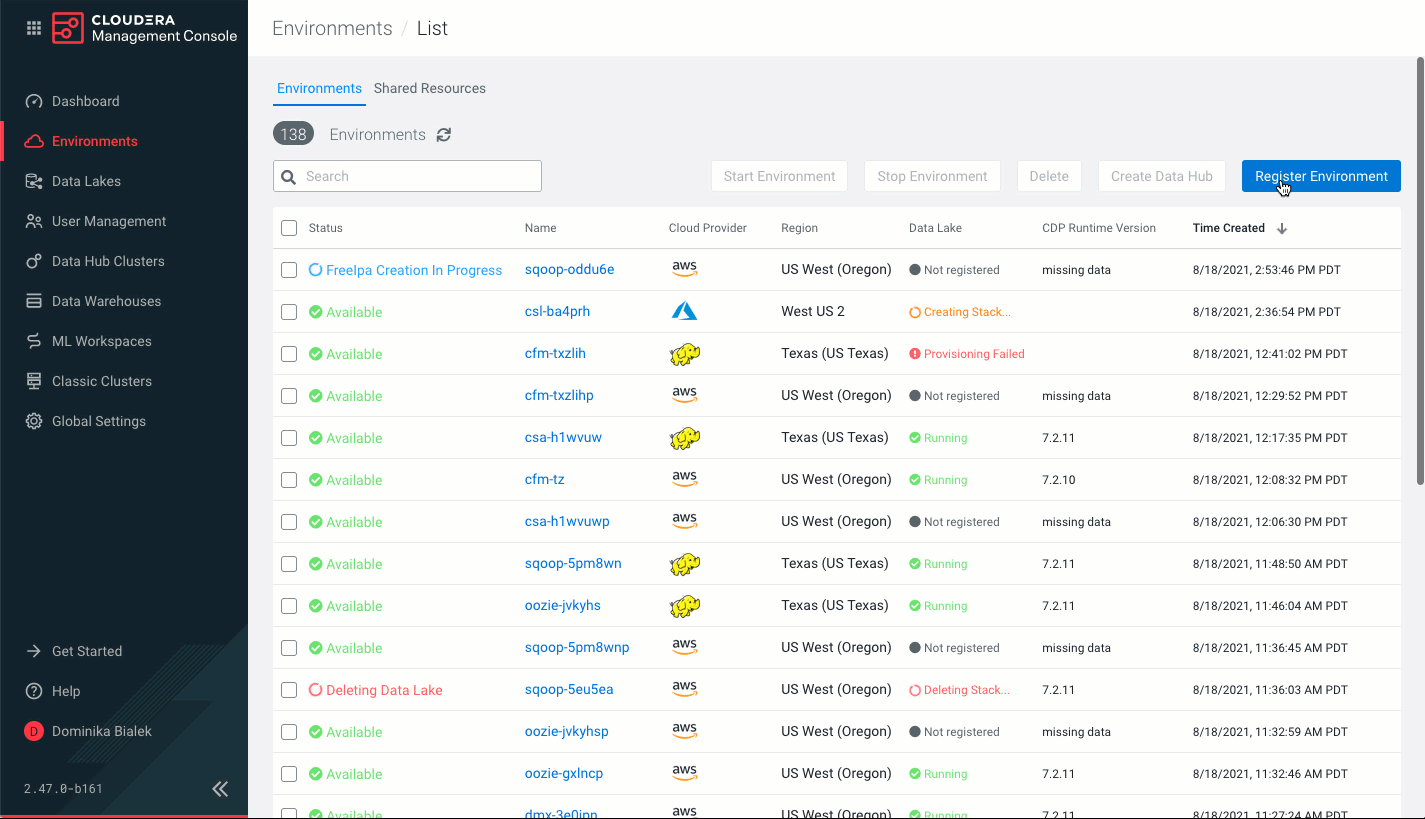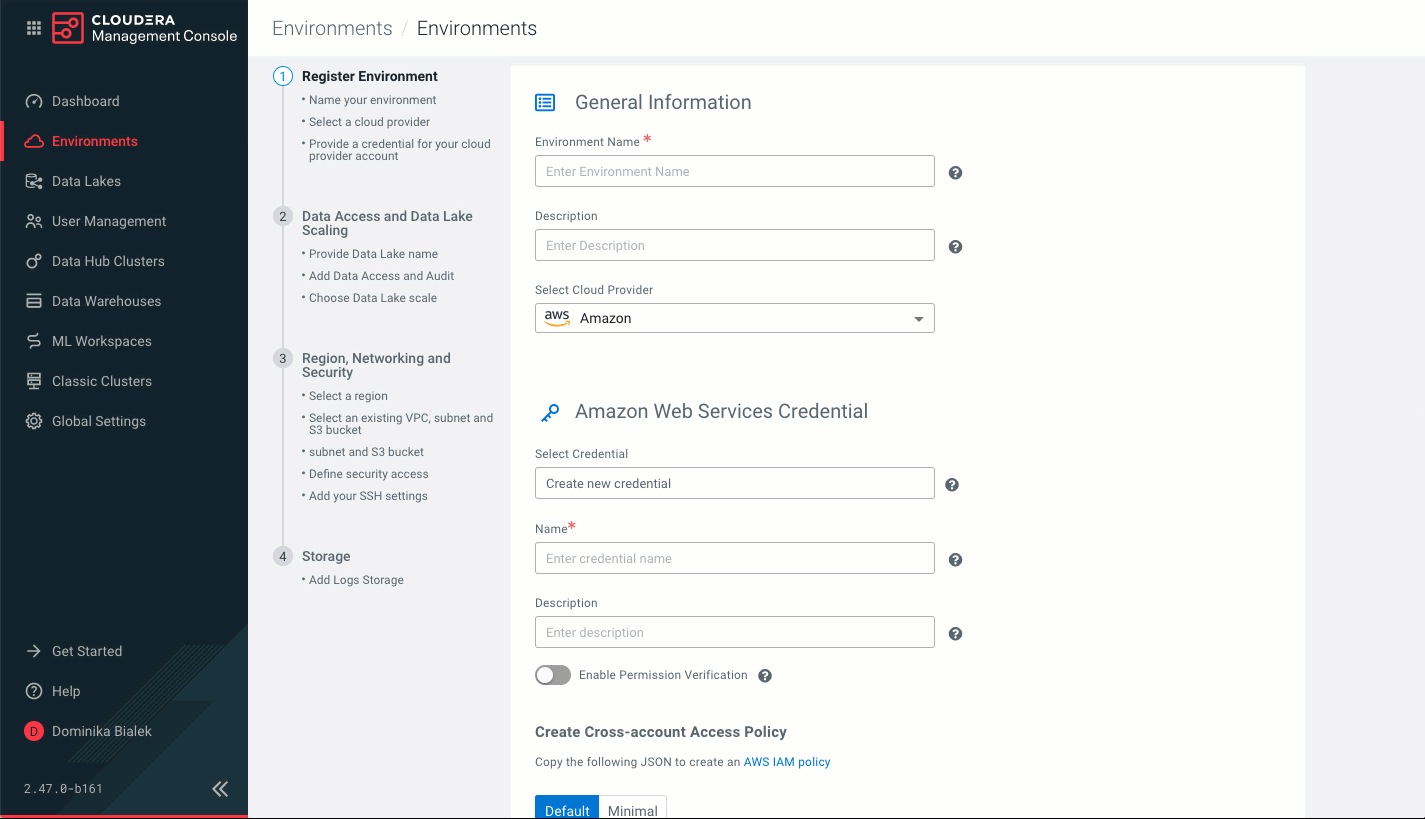
- On the Register Environment page, provide the following information:
Parameter Description General Information Environment Name (Required) Enter a name for your environment. The name: - Must be between 5 and 28 characters long.
- Can only include lowercase letters, numbers, and hyphens.
- Must start with a lowercase letter.
Description Enter a description for your environment. Select Cloud Provider (Required) Select Amazon. Credential (Required) Select Credential Select an existing credential or select Create new credential. For instructions on how to create a credential, refer to Creating a role-based credential.
- Click Next.
- On the Data Access and Data Lake Scaling page, provide the following information:
Parameter Description Data Lake Settings Data Lake Name (Required) Enter a name for the Data Lake cluster that will be created for this environment. The name: - Must be between 5 and 100 characters long
- Must contain lowercase letters
- Cannot contain uppercase letters
- Must start with a letter
- Can only include the following accepted characters are: a-z, 0-9, -.
Architecture Select the Architecture type you want to use for the FreeIPA, Data Lake cluster and RDS. You have the option to choose between the following types:-
X86_64
-
ARM64
You can choose different architecture types for FreeIPA, Data Lake, RDS and Cloudera Data Hub clusters. For example, you can select X86_64 for the Cloudera environment, but ARM64 for the Cloudera Data Hub cluster.
Data Lake Version (Required) Select Cloudera Runtime version that should be deployed for your Data Lake. The latest stable version is used by default. All Cloudera Data Hub clusters provisioned within this Data Lake will be using the same Cloudera Runtime version. Fine-grained access control on S3 Enable Ranger authorization for AWS S3 Identity Enable this if you would like to use Fine-grained access control. Next, from the Select AWS IAM role for Ranger authorizer dropdown, select the DATALAKE_ADMIN_ROLE IAM role created in Minimal setup for cloud storage. Data Access and Audit Assumer Instance Profile (Required) Select the IDBROKER_ROLE instance profile created in Minimal setup for cloud storage. Storage Location Base (Required) Provide the S3 location created for data storage in Minimal setup for cloud storage. Data Access Role (Required) Select the DATALAKE_ADMIN_ROLE IAM role created in Minimal setup for cloud storage. Ranger Audit Role (Required) Select the RANGER_AUDIT_ROLE IAM role created in Minimal setup for cloud storage. IDBroker Mappings We recommend that you leave this out and set it up after registering your environment as part of Onboarding Cloudera users and groups for cloud storage. Scale (Required) Select Data Lake scale. By default, “Light Duty” is used. For more information on Data Lake scale, refer to Data Lake scale.
Enable Compute Cluster Enable Compute Clusters if you would like to deploy a containerized platform on Kubernetes for data services and shared services. - Click on Advanced Options to make additional configurations for your Data Lake. The
following options are available:
Parameter Description Network and Availability Enable Multiple Availability Zones for Data Lake Click the Enable Multiple Availability Zones for Data Lake toggle button to enable multi-AZ for the Data Lake. This option is disabled by default and is only available when a Medium Duty Data Lake is selected. Refer to Deploying Cloudera in multiple AWS availability zones. Hardware and Storage For each host group you can specify an instance type. For more information on instance types, see Amazon EC2 instance types. Cluster Extensions Recipes You can optionally select and attach previously registered recipes to run on a specific Data Lake host group. For more information, see Recipes. - Click Next.
- On the Region, Networking and Security page, provide the following information:
Parameter Description Region Select Region (Required) Select the region that you would like to use for Cloudera. If you would like to use a specific existing virtual network, the virtual network must be located in the selected region.
Customer-managed Keys Enable Customer-Managed Keys Enable this if you would like to provide a Customer-Managed Key (CMK) to encrypt environment's disks and databases. Next, under Select Encryption Key, select an existing CMK. For more information, refer to Customer managed encryption keys. Select Encryption Key Select an existing CMK. Network Select Network (Required) Select the existing virtual network where you would like to provision all Cloudera resources. Refer to VPC and subnet.
Select Subnets (Required) This option is only available if you choose to use an existing network. Multiple subnets must be selected and Cloudera distributes resources evenly within the subnets. Enable Public Endpoint Access Gateway When Cluster Connectivity Manager is enabled, you can optionally enable Public Endpoint Access Gateway to provide secure connectivity to UIs and APIs in Data Lake and Cloudera Data Hub clusters deployed using private networking. Under Select Endpoint Access Gateway Subnets, select the public subnets for which you would like to use the gateway. The number of subnets must be the same as under Select Subnets and the availability zones must match. For more information, refer to Public Endpoint Access Gateway documentation.
Proxies Select Proxy Configuration Select a proxy configuration if previously registered. For more information refer to Setting up a proxy server. Security Access Settings Select Security Access Type (Required) This determines inbound security group settings that allow connections to the Data Lake and Cloudera Data Hub clusters from your organization’s computers. You have two options: Create new security groups - Allows you to provide custom CIDR IP range for all new security groups that will be created for the Data Lake and Cloudera Data Hub clusters so that users from your organization can access cluster UIs and SSH to the nodes.
This must be a valid CIDR IP in IPv4 range. For example: 192.168.27.0/24 allows access from 192.168.27.0 through 192.168.27.255. You can specify multiple CIDR IP ranges separated with a comma. For example: 192.168.27.0/24,192.168.28.0/24
If you use this setting, several security groups will get created: one for each Data Lake host group the Data Lake and one for each host group), one for each FreeIPA host group, and one for RDS; Furthermore, the security group settings specified will be automatically used for Cloudera Data Hub, Cloudera Data Warehouse, and Cloudera AI clusters created as part of the environment.
-
Provide existing security groups (Only available for an existing VPC) - Allows you to select two existing security groups, one for Knox-installed nodes and another for all other nodes. If you select this option, refer to Security groups to ensure that you open all ports required for your users to access environment resources.
Kubernetes Select Private Kubernetes Cluster or provide Authorized IP Ranges If you have enabled Compute Clusters, you have the following options to configure the necessary networking information for the Kubernetes cluster: - Enable Private Kubernetes Cluster to create a private cluster that blocks all access to the API Server endpoint.
- Provide the CIDRs to the Kubernetes API Server Authorized IP Ranges field to specify a set of IP ranges that will be allowed to access the Kubernetes API server.
Worker Node Subnets Uses the same set of subnets provided in Network section. You have the option to not use all of the previously provided subnets. SSH Settings New or existing SSH public key (Required) You have two options for providing a public SSH key: - Select a key that already exists on your AWS account within the specific region that you would like to use.
- Upload a public key directly from your computer.
Add tags You can optionally add tags to be created for your resources on AWS. Refer to Defining custom tags. - Click on Advanced Options to make additional configurations for the FreeIPA
cluster. The following options are available:
Parameter Description Network and Availability Enable Multiple Availability Zones for Data Lake Click the Enable Multiple Availability Zones for Data Lake toggle button to enable multi-AZ for the FreeIPA cluster. Refer to Deploying Cloudera in multiple AWS availability zones. Hardware and Storage For each host group you can specify an instance type. For more information on instance types, see Amazon EC2 instance types. Cluster Extensions Recipes You can optionally select and attach previously registered recipes to run on a specific FreeIPA host group. For more information, see Recipes. - Click Next.
- On the Storage page, provide the following information:
Parameter Description Logs Logger Instance Profile (Required) Select the LOG_ROLE instance profile created in Minimal setup for cloud storage. Logs Location Base (Required) Provide the S3 location created for log storage in Minimal setup for cloud storage. Backup Location Base Provide the S3 location created for FreeIPA and Data Lake backups in Minimal setup for cloud storage. If not provided, the default Backup Location Base uses the Logs Location Base. Telemetry Enable Workload Analytics Enables Cloudera Observability support for workload clusters created within this environment. When this setting is enabled, diagnostic information about job and query execution is sent to Cloudera Observability. For more information, refer to Enabling workload analytics and logs collection. Enable Deployment Cluster Logs Collection When this option is enabled. the logs generated during deployments will be automatically sent to Cloudera. For more information, refer to Enabling workload analytics and logs collection. - Click on Register Environment to trigger environment registration.
- The environment creation takes about 60 minutes. The creation of the FreeIPA server and Data Lake cluster is triggered. You can monitor the progress from the web UI. Once the environment creation has been completed, its status will change to “Running”.
After you finish
- You must assign roles to specific users and groups for the environment so that selected users or user groups can access the environment. Next, you need to perform user sync. For steps, refer to Enabling admin and user access to environments.
- You must onboard your users and/or groups for cloud storage. For steps, refer to Onboarding Cloudera users and groups for cloud storage.
- You must create Ranger policies for your users. For instructions on how to access your Data Lake, refer to Accessing Data Lake services. Once you've accessed Ranger, create Ranger policies to determine which users have access to which databases and tables.