
Chapter 9. Using the Hive View
Hive is a data warehouse infrastructure built on top of Hadoop. It provides tools to enable data ETL, a mechanism to put structures on the data, and the capability to query and analyze large data sets that are stored in Hadoop. The Hive View is designed to help you author, execute, understand, and debug Hive queries.
This chapter explains:
![[Important]](../common/images/admon/important.png) | Important |
|---|---|
The Tez View integrates with the Hive View, especially for debugging and analyzing Hive queries. Please install the Tez View when you install the Hive View. See Using the Tez View for more information. |
| Important |
|---|---|
It is critical that you prepare your Ambari Server for hosting views. It is strongly recommended you increase the amount of memory available to your Ambari Server, and that you run additional “standalone” Ambari Servers to host the views. See Preparing Ambari Server for Views and Running Ambari Server Standalone for more information. |
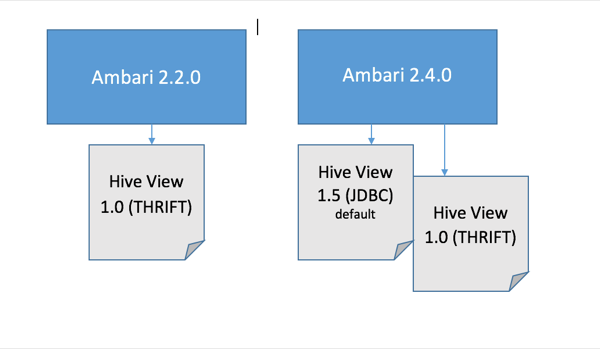
Hive Views
With the release of Apache Ambari 2.4.0, two Hive views install as part of your Hortonworks Data Platform distribution:
Hive View 1.0 - which works with Thift Java API
Hive View 1.5 - which works with the JDBC client
Previously, HDP only installed Hive View 1.0. Hive View 1.5 is now the default when you create a new view.
You can run both views simultaneously, use only one of the views, or upgrade your data from the older view to the newer view. Hortonworks recommends, for enhanced security and because of the future deprecation of Hive View 1.0, that you upgrade and migrate your data from the Hive View 1.0 to the Hive View 1.5.