Performance comparisons
In this topic, we use the ALS algorithm to compare the training speed
with different underlying math libraries, including F2J,
libgfortran, and Intel’s MKL.
By: Zuling Kang, Senior Solutions Architect at Cloudera, Inc.
The hardware we are using are the r4.large VM instances
from Amazon EC2, with 2 CPU cores and 15.25 GB of memory for each
instance. In addition, we are using CentOS 7.5 and CDH 5.15.2 with the
Cloudera Distribution of Spark 2.3 Release 4. The training code is taken
from the core part of the ALS chapter of Advanced Analytics with Spark
(2nd Edition) by Sandy Ryza, et al, O’Reilly (2017). The training data
set is the one published by Audioscrobbler, which can be downloaded at:
https://storage.googleapis.com/aas-data-sets/profiledata_06-May-2005.tar.gzUsually the rank of the ALS model is set to a much larger value than the default of 10, so we use the value of 200 here to make sure that the result is closer to real world examples. Below is the code used to set the parameter values for our ALS model:
val model = new ALS().
setSeed(Random.nextLong()).
setImplicitPrefs(true).
setRank(200).
setRegParam(0.01).
setAlpha(1.0).
setMaxIter(20).
setUserCol("user").
setItemCol("artist").
setRatingCol("count").
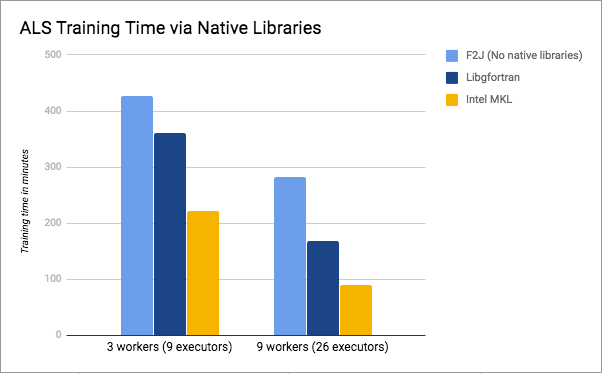
setPredictionCol("prediction")The following table and figure shows the training time when using
different native libraries of Spark ML. The values are shown in minutes.
We can see that both libgfortran and Intel's MKL do
improve the performance of training speed, and MKL seems to outperform
even more. From these experimental results, libgfortran
improves by 18% to 68%, while MKL improves by 92% to 213%.
| # of Workers/Executors | F2J | libgfortran | Intel MKL |
|---|---|---|---|
| 3 workers (9 executors) | 426 | 360 | 222 |
| 9 workers (26 executors) | 282 | 168 | 90 |