Concepts and Terminology
This topic provides model conceptual information.
- Model
-
Model is a high level abstract term that is used to describe several possible incarnations of objects created during the model deployment process. For the purpose of this discussion you should note that 'model' does not always refer to a specific artifact. More precise terms (as defined later in this section) should be used whenever possible.
Stages of the Model Deployment Process
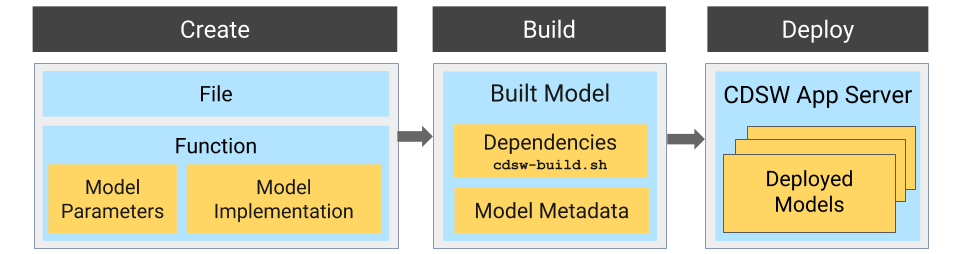
- Create
-
- File - The R or Python file containing the function to be invoked when the model is started.
- Function - The function to be invoked inside the file. This function
should take a single JSON-encoded object (for example, a python dictionary)
as input and return a JSON-encodable object as output to ensure
compatibility with any application accessing the model using the API. JSON
decoding and encoding for model input/output is built into Cloudera Data
Science Workbench. The function will likely include the following components:
- Model Implementation
The code for implementing the model (e.g. decision trees, k-means). This might originate with the data scientist or might be provided by the engineering team. This code implements the model's predict function, along with any setup and teardown that may be required.
- Model Parameters
A set of parameters obtained as a result of model training/fitting (using experiments). For example, a specific decision tree or the specific centroids of a k-means clustering, to be used to make a prediction.
- Model Implementation
- Build
-
This stage takes as input the file that calls the function and returns an artifact that implements a single concrete model, referred to as a model build.
- Built Model
A built model is a static, immutable artifact that includes the model implementation, its parameters, any runtime dependencies, and its metadata. If any of these components need to be changed, for example, code changes to the implementation or its parameters need to be retrained, a new build must be created for the model. Model builds are versioned using build numbers.
To create the model build, Cloudera Data Science Workbench creates a Docker image based on the engine designated as the project's default engine. This image provides an isolated environment where the model implementation code will run.
To configure the image environment, you can specify a list of dependencies to be installed in a build script called
For details about the build process and examples on how to install dependencies, see Engines for Experiments and Models.cdsw-build.sh. - Build Number:
Build numbers are used to track different versions of builds within the scope of a single model. They start at 1 and are incremented with each new build created for the model.
- Built Model
- Deploy
-
This stage takes as input the memory/CPU resources required to power the model, the number of replicas needed, and deploys the model build created in the previous stage to a REST API.