Monitoring YARN Applications
The YARN Applications page displays information about the YARN jobs that are running and have run in your cluster. You can filter the jobs by time period and by specifying simple filtering expressions.
Viewing Jobs
- Do one of the following:
- Select .
- On the tab, select YARN service name and click the Applications tab.
The YARN jobs run during the selected time range display in the Results Tab. The results displayed can be filtered by creating filter expressions.
| Action | Description |
|---|---|
| Filter jobs that display. | Create filter expressions manually, select preconfigured filters, or use the Workload Summary section to build a query interactively. See Filtering Jobs. |
| Select additional attributes for display. | Click Select Attributes. Selected attributes also display as available filters in the Workload Summary section. To display information about attributes, hover over a field label. See Filter Attributes
Only attributes that support filtering appear in the Workload Summary section. See the Attributes table. |
| View a histogram of the attribute values. | Click the  icon to the right of each
attribute displayed in the Workload Summary section. icon to the right of each
attribute displayed in the Workload Summary section. |
| Display charts based on the filter expression and selected attributes. | Click the Charts tab. |
| Send a YARN application diagnostic bundle to Cloudera support. | Click Collect Diagnostics Data. See Sending Diagnostic Data to Cloudera for YARN Applications. |
| Export a JSON file with the query results that you can use for further analysis. | Click Export. |
Configuring YARN Application Monitoring
You can configure the visibility of the YARN application monitoring results.
For information on how to configure whether admin and non-admin users can view all applications, only that user's applications, or no applications, see Configuring Application Visibility.
Results Tab
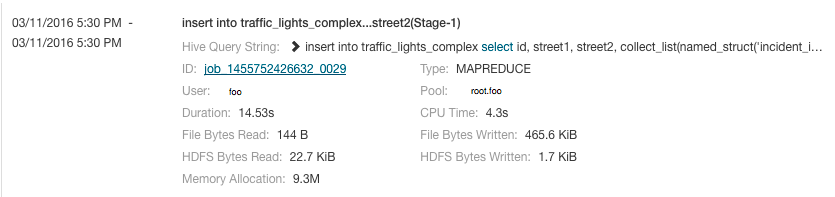
Jobs are ordered with the most recent at the top. Each job has summary and detail information. A job summary includes start and end timestamps, query (if the job is part of a Hive query)
name, pool, job type, job ID, and user. For example:
A running job displays a progress bar under the start timestamp:
 to the right of each job listing to do the following. (Not all
options display, depending on the type of job.)
to the right of each job listing to do the following. (Not all
options display, depending on the type of job.)
- Application Details – Open a details page for the job.
- Collect Diagnostic Data – Send a YARN application diagnostic bundle to Cloudera support.
- Similar MR2 Jobs – Display a list of similar MapReduce 2 jobs.
- User's YARN Applications – Display a list of all jobs run by the user of the current job.
- View on JobHistory Server – View the application in the YARN JobHistory Server.
- Kill (running jobs only) – Kill a job (administrators only). Killing a job creates an audit event. When you kill a job,
 replaces the progress bar.
replaces the progress bar. - Applications in Hive Query (Hive jobs only)
- Applications in Oozie Workflow (Oozie jobs only)
- Applications in Pig Script (Pig jobs only)
Filtering Jobs
You filter jobs by selecting a time range and specifying a filter expression in the search box.
You can use the Time Range Selector or a duration link (  ) to set the time range.
(See Time Line for details).
) to set the time range.
(See Time Line for details).
Filter Expressions
- Attribute - Query language name of the attribute.
- Operator - Type of comparison between the attribute and the attribute value. Cloudera Manager supports the standard comparator operators =, !=, >, <, >=, <=, and RLIKE. (RLIKE performs regular expression matching as specified in the Java Pattern class documentation.) Numeric values can be compared with all operators. String values can be compared with =, !=, and RLIKE. Boolean values can be compared with = and !=.
- Value - The value of the attribute. The value depends on the type of the attribute. For a Boolean value, specify either true or false. When specifying a string value, enclose the value in double quotes.
You create compound filter expressions using the AND and OR operators. When more than one operator is used in an expression, AND is evaluated first, then OR. To change the order of evaluation, enclose subexpressions in parentheses.
Compound Expressions
user = "root" AND application_duration >= 100000.0
maps_completed >= 200.0 AND (user = "Jack" OR user = "Jill")
Choosing and Running a Filter
- Do one of the following:
- Select a Suggested or Recently Run Filter
Click the
 to the right of the Search button to
display a list of sample and recently run filters, and select a filter. The filter text displays in the text box.
to the right of the Search button to
display a list of sample and recently run filters, and select a filter. The filter text displays in the text box. - Construct a Filter from the Workload Summary Attributes
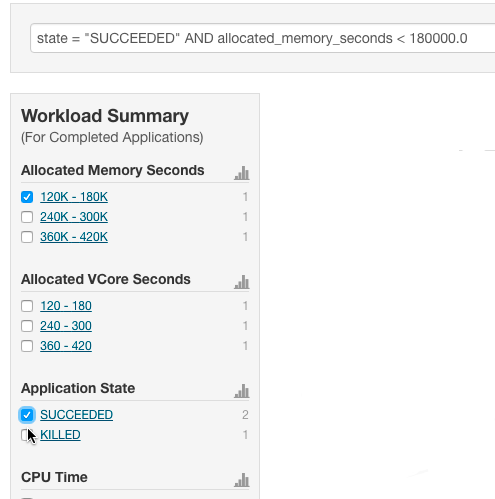
Optionally, click Select Attributes to display a dialog box where you can chose attributes to display in the Workload Summary section. Select the checkbox next to one or more attributes and click Close. Only attributes that support filtering appear in the Workload Summary section. See the Attributes table.
The attributes display in the Workload Summary section along with values or ranges of values that you can filter on. The values and ranges display as links with checkboxes. Select one or more checkboxes to add the range or value to the query. Click a link to run a query on that value or range. For example:
- Type a Filter
- Start typing or press Spacebar in the text box. As you type, filter attributes matching the typed letter display. If you press Spacebar, standard filter attributes display. These suggestions are part of typeahead, which helps build valid queries. For information about the attribute name and supported values for each field, hover over the field in an existing query.
- Select an attribute and press Enter.
- Press Spacebar to display a drop-down list of operators.
- Select an operator and press Enter.
- Specify an attribute value in one of the following ways:
- For attribute values that support typeahead, press Spacebar to display a drop-down list of values and press Enter.
- Type a value.
- Select a Suggested or Recently Run Filter
- Click in the text box and press Enter or click Search. The list displays the results that match the specified filter. If the histograms are showing, they are redrawn to show only the values for the selected filter. The filter is added to the Recently Run list.
Filter Attributes
| Display Name
(Attribute Name) |
Type | Supports Filtering? | Description |
|---|---|---|---|
| Allocated Memory
(allocated_mb) |
NUMBER | FALSE | The sum of memory in MB allocated to the application's running containers. Called 'allocated_mb' in searches. |
| Allocated Memory Seconds
(allocated_memory_seconds) |
NUMBER | TRUE | The amount of memory the application has allocated (megabyte-seconds). Called 'allocated_memory_seconds' in searches. |
| Allocated VCores
(allocated_vcores) |
NUMBER | FALSE | The sum of virtual cores allocated to the application's running containers. Called 'allocated_vcores' in searches. |
| Allocated VCore Seconds
(allocated_vcore_seconds) |
NUMBER | TRUE | The amount of CPU resources the application has allocated (virtual core-seconds). Called 'allocated_vcore_seconds' in searches. |
| Application ID
(application_id) |
STRING | FALSE | The ID of the YARN application. Called 'application_id' in searches. |
| Application State
(state) |
STRING | TRUE | The state of this YARN application. This reflects the ResourceManager state while the application is running and the JobHistory Server state after the application has completed. Called 'state' in searches. |
| Application Tags
(application_tags) |
STRING | FALSE | A list of tags for the application. Called 'application_tags' in searches. |
| Application Type
(application_type) |
STRING | TRUE | The type of the YARN application. Called 'application_type' in searches. |
| Bytes Read
(bytes_read) |
BYTES | TRUE | Bytes read. Called 'bytes_read' in searches. |
| Bytes Written
(bytes_written) |
BYTES | TRUE | Bytes written. Called 'bytes_written' in searches. |
| Combine Input Records
(combine_input_records) |
NUMBER | TRUE | Combine input records. Called 'combine_input_records' in searches. |
| Combine Output Records
(combine_output_records) |
NUMBER | TRUE | Combine output records. Called 'combine_output_records' in searches. |
| Committed Heap
(committed_heap_bytes) |
BYTES | TRUE | Total committed heap usage. Called 'committed_heap_bytes' in searches. |
| Completed Maps and Reduces
(tasks_completed) |
NUMBER | TRUE | The number of completed map and reduce tasks in this MapReduce job. Called 'tasks_completed' in searches. Available only for running jobs. |
| CPU Allocation
(vcores_millis) |
NUMBER | TRUE | CPU allocation. This is the sum of 'vcores_millis_maps' and 'vcores_millis_reduces'. Called 'vcores_millis' in searches. |
| CPU Time
(cpu_milliseconds) |
MILLISECONDS | TRUE | CPU time. Called 'cpu_milliseconds' in searches. |
| Data Local Maps
(data_local_maps) |
NUMBER | TRUE | Data local maps. Called 'data_local_maps' in searches. |
| Data Local Maps Percentage
(data_local_maps_percentage) |
NUMBER | TRUE | The number of data local maps as a percentage of the total number of maps. Called 'data_local_maps_percentage' in searches. |
| Diagnostics
(diagnostics) |
STRING | FALSE | Diagnostic information on the YARN application. If the diagnostic information is long, this may only contain the beginning of the information. Called 'diagnostics' in searches. |
| Duration
(application_duration) |
MILLISECONDS | TRUE | How long YARN took to run this application. Called 'application_duration' in searches. |
| Executing
(executing) |
BOOLEAN | FALSE | Whether the YARN application is currently running. Called 'executing' in searches. |
| Failed Map and Reduce Attempts
(failed_tasks_attempts) |
NUMBER | TRUE | The number of failed map and reduce attempts for this MapReduce job. Called 'failed_tasks_attempts' in searches. Available only for failed jobs. |
| Failed Map Attempts
(failed_map_attempts) |
NUMBER | TRUE | The number of failed map attempts for this MapReduce job. Called 'failed_map_attempts' in searches. Available only for running jobs. |
| Failed Maps
(num_failed_maps) |
NUMBER | TRUE | Failed maps. Called 'num_failed_maps' in searches. |
| Failed Reduce Attempts
(failed_reduce_attempts) |
NUMBER | TRUE | The number of failed reduce attempts for this MapReduce job. Called 'failed_reduce_attempts' in searches. Available only for running jobs. |
| Failed Reduces
(num_failed_reduces) |
NUMBER | TRUE | Failed reduces. Called 'num_failed_reduces' in searches. |
| Failed Shuffles
(failed_shuffle) |
NUMBER | TRUE | Failed shuffles. Called 'failed_shuffle' in searches. |
| Failed Tasks
(num_failed_tasks) |
NUMBER | TRUE | The total number of failed tasks. This is the sum of 'num_failed_maps' and 'num_failed_reduces'. Called 'num_failed_tasks' in searches. |
| Fallow Map Slots Time
(fallow_slots_millis_maps) |
MILLISECONDS | TRUE | Fallow map slots time. Called 'fallow_slots_millis_maps' in searches. |
| Fallow Reduce Slots Time
(fallow_slots_millis_reduces) |
MILLISECONDS | TRUE | Fallow reduce slots time. Called 'fallow_slots_millis_reduces' in searches. |
| Fallow Slots Time
(fallow_slots_millis) |
MILLISECONDS | TRUE | Total fallow slots time. This is the sum of 'fallow_slots_millis_maps' and 'fallow_slots_millis_reduces'. Called 'fallow_slots_millis' in searches. |
| File Bytes Read
(file_bytes_read) |
BYTES | TRUE | File bytes read. Called 'file_bytes_read' in searches. |
| File Bytes Written
(file_bytes_written) |
BYTES | TRUE | File bytes written. Called 'file_bytes_written' in searches. |
| File Large Read Operations
(file_large_read_ops) |
NUMBER | TRUE | File large read operations. Called 'file_large_read_ops' in searches. |
| File Read Operations
(file_read_ops) |
NUMBER | TRUE | File read operations. Called 'file_read_ops' in searches. |
| File Write Operations
(file_write_ops) |
NUMBER | TRUE | File write operations. Called 'file_large_write_ops' in searches. |
| Garbage Collection Time
(gc_time_millis) |
MILLISECONDS | TRUE | Garbage collection time. Called 'gc_time_millis' in searches. |
| HDFS Bytes Read
(hdfs_bytes_read) |
BYTES | TRUE | HDFS bytes read. Called 'hdfs_bytes_read' in searches. |
| HDFS Bytes Written
(hdfs_bytes_written) |
BYTES | TRUE | HDFS bytes written. Called 'hdfs_bytes_written' in searches. |
| HDFS Large Read Operations
(hdfs_large_read_ops) |
NUMBER | TRUE | HDFS large read operations. Called 'hdfs_large_read_ops' in searches. |
| HDFS Read Operations
(hdfs_read_ops) |
NUMBER | TRUE | HDFS read operations. Called 'hdfs_read_ops' in searches. |
| HDFS Write Operations
(hdfs_write_ops) |
NUMBER | TRUE | HDFS write operations. Called 'hdfs_write_ops' in searches. |
| Hive Query ID
(hive_query_id) |
STRING | FALSE | If this MapReduce job ran as a part of a Hive query, this field contains the ID of the Hive query. Called 'hive_query_id' in searches. |
| Hive Query String
(hive_query_string) |
STRING | TRUE | If this MapReduce job ran as a part of a Hive query, this field contains the string of the query. Called 'hive_query_string' in searches. |
| Hive Sentry Subject Name
(hive_sentry_subject_name) |
STRING | TRUE | If this MapReduce job ran as a part of a Hive query on a secured cluster using impersonation, this field contains the name of the user that initiated the query. Called 'hive_sentry_subject_name' in searches. |
| Input Directory
(input_dir) |
STRING | TRUE | The input directory for this MapReduce job. Called 'input_dir' in searches. |
| Input Split Bytes
(split_raw_bytes) |
BYTES | TRUE | Input split bytes. Called 'split_raw_bytes' in searches. |
| Killed Map and Reduce Attempts
(killed_tasks_attempts) |
NUMBER | TRUE | The number of map and reduce attempts that were killed by user(s) for this MapReduce job. Called 'killed_tasks_attempts' in searches. Available only for killed jobs. |
| Killed Map Attempts
(killed_map_attempts) |
NUMBER | TRUE | The number of map attempts killed by user(s) for this MapReduce job. Called 'killed_map_attempts' in searches. Available only for running jobs. |
| Killed Reduce Attempts
(killed_reduce_attempts) |
NUMBER | TRUE | The number of reduce attempts killed by user(s) for this MapReduce job. Called 'killed_reduce_attempts' in searches. Available only for running jobs. |
| Launched Map Tasks
(total_launched_maps) |
NUMBER | TRUE | Launched map tasks. Called 'total_launched_maps' in searches. |
| Launched Reduce Tasks
(total_launched_reduces) |
NUMBER | TRUE | Launched reduce tasks. Called 'total_launched_reduces' in searches. |
| Map and Reduce Attempts in NEW State
(new_tasks_attempts) |
NUMBER | TRUE | The number of map and reduce attempts in NEW state for this MapReduce job. Called 'new_tasks_attempts' in searches. Available only for running jobs. |
| Map Attempts in NEW State
(new_map_attempts) |
NUMBER | TRUE | The number of map attempts in NEW state for this MapReduce job. Called 'new_map_attempts' in searches. Available only for running jobs. |
| Map Class
(mapper_class) |
STRING | TRUE | The class used by the map tasks in this MapReduce job. Called 'mapper_class' in searches. You can search for the mapper class using the class name alone, for example 'QuasiMonteCarlo$QmcMapper', or the fully qualified classname, for example, 'org.apache.hadoop.examples.QuasiMonteCarlo$QmcMapper'. |
| Map CPU Allocation
(vcores_millis_maps) |
NUMBER | TRUE | Map CPU allocation. Called 'vcores_millis_maps' in searches. |
| Map Input Records
(map_input_records) |
NUMBER | TRUE | Map input records. Called 'map_input_records' in searches. |
| Map Memory Allocation
(mb_millis_maps) |
NUMBER | TRUE | Map memory allocation. Called 'mb_millis_maps' in searches. |
| Map Output Bytes
(map_output_bytes) |
BYTES | TRUE | Map output bytes. Called 'map_output_bytes' in searches. |
| Map Output Materialized Bytes
(map_output_materialized_bytes) |
BYTES | TRUE | Map output materialized bytes. Called 'map_output_materialized_bytes' in searches. |
| Map Output Records
(map_output_records) |
NUMBER | TRUE | Map output records. Called 'map_output_records' in searches. |
| Map Progress
(map_progress) |
NUMBER | TRUE | The percentage of maps completed for this MapReduce job. Called 'map_progress' in searches. Available only for running jobs. |
| Maps Completed
(maps_completed) |
NUMBER | TRUE | The number of map tasks completed as a part of this MapReduce job. Called 'maps_completed' in searches. |
| Map Slots Time
(slots_millis_maps) |
MILLISECONDS | TRUE | Total time spent by all maps in occupied slots. Called 'slots_millis_maps' in searches. |
| Maps Pending
(maps_pending) |
NUMBER | TRUE | The number of maps waiting to be run for this MapReduce job. Called 'maps_pending' in searches. Available only for running jobs. |
| Maps Running
(maps_running) |
NUMBER | TRUE | The number of maps currently running for this MapReduce job. Called 'maps_running' in searches. Available only for running jobs. |
| Maps Total
(maps_total) |
NUMBER | TRUE | The number of Map tasks in this MapReduce job. Called 'maps_total' in searches. |
| Memory Allocation
(mb_millis) |
NUMBER | TRUE | Total memory allocation. This is the sum of 'mb_millis_maps' and 'mb_millis_reduces'. Called 'mb_millis' in searches. |
| Merged Map Outputs
(merged_map_outputs) |
NUMBER | TRUE | Merged map outputs. Called 'merged_map_outputs' in searches. |
| Name
(name) |
STRING | TRUE | Name of the YARN application. Called 'name' in searches. |
| Oozie Workflow ID
(oozie_id) |
STRING | FALSE | If this MapReduce job ran as a part of an Oozie workflow, this field contains the ID of the Oozie workflow. Called 'oozie_id' in searches. |
| Other Local Maps
(other_local_maps) |
NUMBER | TRUE | Other local maps. Called 'other_local_maps' in searches. |
| Other Local Maps Percentage
(other_local_maps_percentage) |
NUMBER | TRUE | The number of other local maps as a percentage of the total number of maps. Called 'other_local_maps_percentage' in searches. |
| Output Directory
(output_dir) |
STRING | TRUE | The output directory for this MapReduce job. Called 'output_dir' in searches. |
| Pending Maps and Reduces
(tasks_pending) |
NUMBER | TRUE | The number of maps and reduces waiting to be run for this MapReduce job. Called 'tasks_pending' in searches. Available only for running jobs. |
| Physical Memory
(physical_memory_bytes) |
BYTES | TRUE | Physical memory. Called 'physical_memory_bytes' in searches. |
| Pig Script ID
(pig_id) |
STRING | FALSE | If this MapReduce job ran as a part of a Pig script, this field contains the ID of the Pig script. Called 'pig_id' in searches. |
| Pool
(pool) |
STRING | TRUE | The name of the resource pool in which this application ran. Called 'pool' in searches. Within YARN, a pool is referred to as a queue. |
| Progress
(progress) |
NUMBER | TRUE | The progress reported by the application. Called 'progress' in searches. |
| Rack Local Maps
(rack_local_maps) |
NUMBER | TRUE | Rack local maps. Called 'rack_local_maps' in searches. |
| Rack Local Maps Percentage
(rack_local_maps_percentage) |
NUMBER | TRUE | The number of rack local maps as a percentage of the total number of maps. Called 'rack_local_maps_percentage' in searches. |
| Reduce Attempts in NEW State
(new_reduce_attempts) |
NUMBER | TRUE | The number of reduce attempts in NEW state for this MapReduce job. Called 'new_reduce_attempts' in searches. Available only for running jobs. |
| Reduce Class
(reducer_class) |
STRING | TRUE | The class used by the reduce tasks in this MapReduce job. Called 'reducer_class' in searches. You can search for the reducer class using the class name alone, for example 'QuasiMonteCarlo$QmcReducer', or fully qualified classname, for example, 'org.apache.hadoop.examples.QuasiMonteCarlo$QmcReducer'. |
| Reduce CPU Allocation
(vcores_millis_reduces) |
NUMBER | TRUE | Reduce CPU allocation. Called 'vcores_millis_reduces' in searches. |
| Reduce Input Groups
(reduce_input_groups) |
NUMBER | TRUE | Reduce input groups. Called 'reduce_input_groups' in searches. |
| Reduce Input Records
(reduce_input_records) |
NUMBER | TRUE | Reduce input records. Called 'reduce_input_records' in searches. |
| Reduce Memory Allocation
(mb_millis_reduces) |
NUMBER | TRUE | Reduce memory allocation. Called 'mb_millis_reduces' in searches. |
| Reduce Output Records
(reduce_output_records) |
NUMBER | TRUE | Reduce output records. Called 'reduce_output_records' in searches. |
| Reduce Progress
(reduce_progress) |
NUMBER | TRUE | The percentage of reduces completed for this MapReduce job. Called 'reduce_progress' in searches. Available only for running jobs. |
| Reduces Completed
(reduces_completed) |
NUMBER | TRUE | The number of reduce tasks completed as a part of this MapReduce job. Called 'reduces_completed' in searches. |
| Reduce Shuffle Bytes
(reduce_shuffle_bytes) |
BYTES | TRUE | Reduce shuffle bytes. Called 'reduce_shuffle_bytes' in searches. |
| Reduce Slots Time
(slots_millis_reduces) |
MILLISECONDS | TRUE | Total time spent by all reduces in occupied slots. Called 'slots_millis_reduces' in searches. |
| Reduces Pending
(reduces_pending) |
NUMBER | TRUE | The number of reduces waiting to be run for this MapReduce job. Called 'reduces_pending' in searches. Available only for running jobs. |
| Reduces Running
(reduces_running) |
NUMBER | TRUE | The number of reduces currently running for this MapReduce job. Called 'reduces_running' in searches. Available only for running jobs. |
| Reduces Total
(reduces_total) |
NUMBER | TRUE | The number of reduce tasks in this MapReduce job. Called 'reduces_total' in searches. |
| Running Containers
(running_containers) |
NUMBER | FALSE | The number of containers currently running for the application. Called 'running_containers' in searches. |
| Running Map and Reduce Attempts
(running_tasks_attempts) |
NUMBER | TRUE | The number of map and reduce attempts currently running for this MapReduce job. Called 'running_tasks_attempts' in searches. Available only for running jobs. |
| Running Map Attempts
(running_map_attempts) |
NUMBER | TRUE | The number of running map attempts for this MapReduce job. Called 'running_map_attempts' in searches. Available only for running jobs. |
| Running MapReduce Application Information Retrieval Duration.
(running_application_info_retrieval_time) |
NUMBER | TRUE | How long it took, in seconds, to retrieve information about the MapReduce application. |
| Running Maps and Reduces
(tasks_running) |
NUMBER | TRUE | The number of maps and reduces currently running for this MapReduce job. Called 'tasks_running' in searches. Available only for running jobs. |
| Running Reduce Attempts
(running_reduce_attempts) |
NUMBER | TRUE | The number of running reduce attempts for this MapReduce job. Called 'running_reduce_attempts' in searches. Available only for running jobs. |
| Service Name
(service_name) |
STRING | FALSE | The name of the YARN service. Called 'service_name' in searches. |
| Shuffle Bad ID Errors
(shuffle_errors_bad_id) |
NUMBER | TRUE | Shuffle bad ID errors. Called 'shuffle_errors_bad_id' in searches. |
| Shuffle Connection Errors
(shuffle_errors_connection) |
NUMBER | TRUE | Shuffle connection errors. Called 'shuffle_errors_connection' in searches. |
| Shuffled Maps
(shuffled_maps) |
NUMBER | TRUE | Shuffled maps. Called 'shuffled_maps' in searches. |
| Shuffle IO Errors
(shuffle_errors_io) |
NUMBER | TRUE | Shuffle IO errors. Called 'shuffle_errors_io' in searches. |
| Shuffle Wrong Length Errors
(shuffle_errors_wrong_length) |
NUMBER | TRUE | Shuffle wrong length errors. Called 'shuffle_errors_wrong_length' in searches. |
| Shuffle Wrong Map Errors
(shuffle_errors_wrong_map) |
NUMBER | TRUE | Shuffle wrong map errors. Called 'shuffle_errors_wrong_map' in searches. |
| Shuffle Wrong Reduce Errors
(shuffle_errors_wrong_reduce) |
NUMBER | TRUE | Shuffle wrong reduce errors. Called 'shuffle_errors_wrong_reduce' in searches. |
| Slots Time
(slots_millis) |
MILLISECONDS | TRUE | Total slots time. This is the sum of 'slots_millis_maps' and 'slots_millis_reduces'. Called 'slots_millis' in searches. |
| Spilled Records
(spilled_records) |
NUMBER | TRUE | Spilled Records. Called 'spilled_records' in searches. |
| Successful Map and Reduce Attempts
(successful_tasks_attempts) |
NUMBER | TRUE | The number of successful map and reduce attempts for this MapReduce job. Called 'successful_tasks_attempts' in searches. Available only for successful jobs. |
| Successful Map Attempts
(successful_map_attempts) |
NUMBER | TRUE | The number of successful map attempts for this MapReduce job. Called 'successful_map_attempts' in searches. Available only for running jobs. |
| Successful Reduce Attempts
(successful_reduce_attempts) |
NUMBER | TRUE | The number of successful reduce attempts for this MapReduce job. Called 'successful_reduce_attempts' in searches. Available only for running jobs. |
| Total Maps and Reduces Number
(total_task_num) |
NUMBER | TRUE | The number of map and reduce tasks in this MapReduce job. Called 'tasks_total' in searches. Available only for running jobs. |
| Total Tasks
(total_launched_tasks) |
NUMBER | TRUE | The total number of tasks. This is the sum of 'total_launched_maps' and 'total_launched_reduces'. Called 'total_launched_tasks' in searches. |
| Tracking Url
(tracking_url) |
STRING | FALSE | The MapReduce application tracking URL. |
| Uberized Job
(uberized) |
BOOLEAN | FALSE | Whether this MapReduce job is uberized - running completely in the ApplicationMaster. Called 'uberized' in searches. Available only for running jobs. |
| Unused Memory Seconds
(unused_memory_seconds) |
NUMBER | TRUE | The amount of memory the application has allocated but not used (megabyte-seconds). This metric is calculated hourly if container usage metric aggregation is enabled. Called 'unused_memory_seconds' in searches. |
| Unused VCore Seconds
(unused_vcore_seconds) |
NUMBER | TRUE | The amount of CPU resources the application has allocated but not used (virtual core-seconds). This metric is calculated hourly if container usage metric aggregation is enabled. Called 'unused_vcore_seconds' in searches. |
| Used Memory Max
(used_memory_max) |
NUMBER | TRUE | The maximum container memory usage for a YARN application. This metric is calculated hourly if container usage metric
aggregation is enabled and a Cloudera Manager Container Usage Metrics Directory is specified.
For information about how to enable metric aggregation and the Container Usage Metrics Directory, see Enabling the Cluster Utilization Report. |
| User
(user) |
STRING | TRUE | The user who ran the YARN application. Called 'user' in searches. |
| Virtual Memory
(virtual_memory_bytes) |
BYTES | TRUE | Virtual memory. Called 'virtual_memory_bytes' in searches. |
| Work CPU Time
(cm_cpu_milliseconds) |
MILLISECONDS | TRUE | Attribute measuring the sum of CPU time used by all threads of the query, in milliseconds. Called 'work_cpu_time' in searches. For Impala queries, CPU time is calculated based on the 'TotalCpuTime' metric. For YARN MapReduce applications, this is calculated from the 'cpu_milliseconds' metric. |
Examples
Consider the following filter expressions: user = "root", rowsProduced > 0, fileFormats RLIKE ".TEXT.*", and executing = true. In the examples:
- The filter attributes are user, rowsProduced, fileFormats, and executing.
- The operators are =, >, and RLIKE.
- The filter values are root, 0, .TEXT.*, and true.
Sending Diagnostic Data to Cloudera for YARN Applications
Minimum Required Role: Cluster Administrator (also provided by Full Administrator)
- From the YARN page in Cloudera Manager, click the Applications menu.
- Collect diagnostics data. There are two ways to do this:
-
To collect data from all applications that are visible in the list, click the top Collect Diagnostics Data button on the upper right, above the list of YARN applications.
- To collect data from only one specific application, click the down arrow on the right-hand end of the row of the application and select Collect Diagnostics
Data.
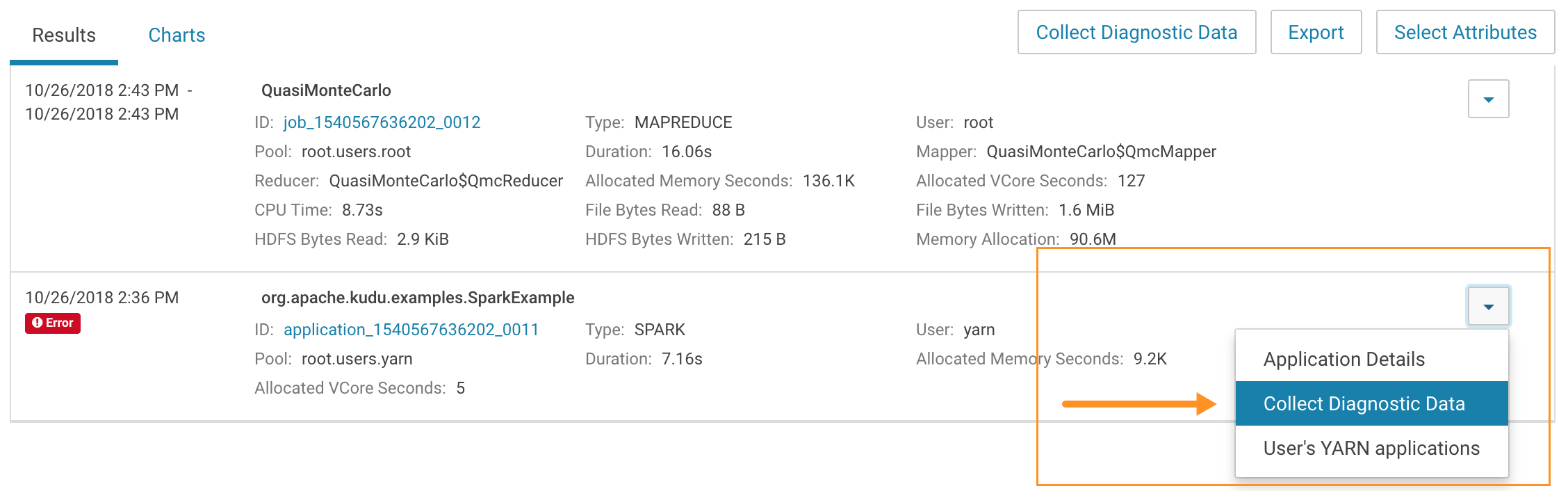
-
- In the Send YARN Applications Diagnostic Data dialog box, provide the following information:
- If applicable, the Cloudera Support ticket number of the issue being experienced on the cluster.
- Optionally, add a comment to help the support team understand the issue.
- Click the checkbox Send Diagnostic Data to Cloudera.
- Click the button Collect and Send Diagnostic Data.
