Virtual Private Clusters and Cloudera SDX
Overview
A Virtual Private Cluster uses the Cloudera Shared Data Experience (SDX) to simplify deployment of both on-premise and cloud-based applications and enable workloads running in different clusters to securely and flexibly share data. This architecture provides many advantages for deploying workloads and sharing data among applications, including a shared catalog, unified security, consistent governance, and data lifecycle management.
In traditional CDH deployments, a Regular cluster contains storage nodes, compute nodes, and other services such as metadata services and security services that are collocated in a single cluster. This traditional architecture provides many advantages where computational services such as Impala and YARN can access collocated data sources such as HDFS or Hive.
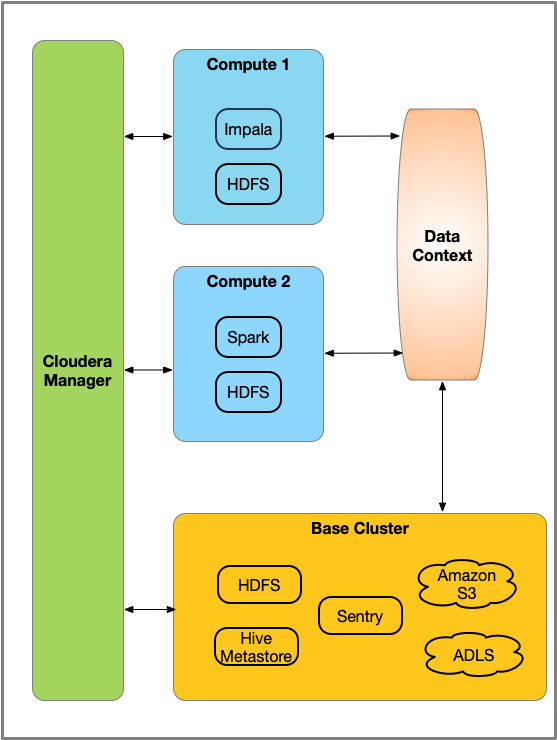
With Virtual Private Clusters and the SDX framework, a new type of cluster is available in Cloudera Manager 6.2 and higher, called a Compute cluster. A Compute cluster runs computational services such as Impala, Hive Execution Service, Spark, or YARN but you configure these services to access data hosted in another Regular CDH cluster, called the Base cluster. Using this architecture, you can separate compute and storage resources in a variety of ways to flexibly maximize resources.
Advantages of Separating Compute and Data Resources
Architectures that separate compute resources from data resources can provide many advantages for a CDH deployment:
- More options for deploying computational and storage resources
- You can selectively deploy resources using on-premise servers, containers, virtual machines, or cloud resources that are tailored for the workload. When you configure a Compute cluster, you can provision hardware that is more appropriate for computational workloads while the Base cluster can use hardware that emphasizes storage capacity. Cloudera recommends that each cluster use similar hardware.
- Software resources can be optimized to best use computational and storage resources.
-
Ephemeral clusters
When deploying clusters on cloud infrastructure, having separate clusters for compute and storage allows you to temporarily shut down the compute clusters and avoid unnecessary expense -- while still leaving the data available to other applications.
- Workload Isolation
- Compute clusters can help to resolve resource conflicts among users accessing the cluster. Longer running or resource intensive workloads can be isolated to run in dedicated compute clusters that do not interfere with other workloads.
- Resources can be grouped into clusters that allow IT to allocate costs to the teams that use the resources.
Architecture
A Compute cluster is configured with compute resources such as YARN, Spark, Hive Execution, or Impala. Workloads running on these clusters access data by connecting to a Data Context for the Base cluster. A Data Context is a connector to a Regular cluster that is designated as the Base cluster. The Data context defines the data, metadata and security services deployed in the Base cluster that are required to access the data. Both the Compute cluster and Base cluster are managed by the same instance of Cloudera Manager. A Base cluster must have an HDFS service deployed and can contain any other CDH services -- but only HDFS, Hive, Sentry, Amazon S3, and Microsoft ADLS can be shared using the data context.
- Hive Execution Service (This service supplies the HiveServer2 role only.)
- Hue
- Impala
- Kafka
- Spark 2
- Oozie (only when Hue is available, and is a requirement for Hue)
- YARN
- HDFS (required)
The functionality of a Virtual Private cluster is a subset of the functionality available in Regular clusters, and the versions of CDH that you can use are limited. For more information, see Compatibility Considerations for Virtual Private Clusters.
For details on networking requirements and topology, see Networking Considerations for Virtual Private Clusters.
Performance Trade Offs
Throughput
Because data will be accessed over network connections to other clusters, this architecture may not be appropriate for workloads that scan large amounts of data. These types of workloads may run better on Regular clusters where compute and storage are collocated and features such as Impala short-circuit reads can provide improved performance.
See Networking Considerations for Virtual Private Clusters
You can evaluate the networking performance using the Network Performance Inspector.
Ephemeral Clusters
For deployments where the Compute clusters are shut down or suspended when they are not needed, cluster services that collect historical data do not collect data when the Compute clusters are off-line, and the history is not available to users. This affects services such as the Spark History Server and the YARN JobHistory Server. When the Compute cluster restarts, the previous history will be available.
Data Governance and Catalog In Compute clusters
In the context of a Base cluster with additional Compute clusters running workloads, Navigator serves the governance and catalog goals of the long-term assets on the Base cluster. It also collects audit events from the supported services running on the Compute clusters. Navigator does not extract metadata from the potentially transient Compute clusters. When you configure your clusters such that user operations run against services and data on the Base cluster and only operations by controlled service accounts are run on the compute cluster, Navigator continues to track essential metadata.
No metadata is collected from services running on Compute clusters. To ensure that your system collects the metadata for assets and operations in your environment, include the services in your data context.
When you terminate a Compute cluster, you should make sure that audit events from services on the Compute cluster have been processed by Navigator. Audit events that have not reached Navigator will be lost when the cluster terminates.
For more information on how Cloudera Navigator interacts with Compute clusters, see Cloudera Navigator support for Virtual Private Clusters
Using Virtual Private Clusters in Your Applications
Generally, your applications interact with the services deployed on the Compute cluster, and those services access data stored in the Base cluster through the Data Context.
Adding a Compute Cluster and Data Context
To create a Compute cluster, you must have a Regular cluster that will be designated as the Base cluster. This cluster hosts the data services to be used by a Compute cluster and can also host services for other workloads that do not require access to data services defined in the Data Context.
To create a Regular cluster, see Adding and Deleting Clusters.
To create a Compute cluster:
- On the Cloudera Manager home page, click
The Add Cluster Welcome page displays.
- Click Continue. The Cluster Basics page displays.
- Select Compute cluster.
- If you already have a Data Context defined, select it from the drop-down list.
-
To create new Data Context:
- Select Create Data Context from the drop-down list.
The Create Data Context dialog box displays.
- Enter a unique name for the Data Context.
- Select the Base cluster from the drop-down list.
- Select the Data Services, Metadata Services and Security Services you want to expose in the Data Context. You can choose the following:
- HDFS (required)
- Amazon S3 (must be configured on the base cluster)
- Microsoft ADLS (must be configured on the base cluster)
- Hive Metadata Service
- Sentry
- Click Create.
The Cluster Basics page displays your selections.
- Select Create Data Context from the drop-down list.
- Click Continue.
- Continue with the next steps in the Add Cluster Wizard to specify hosts and credentials, and install the Agent and CDH software.
The Select Repository screen will examine the CDH version of the case cluster and recommend a supported version. Cloudera recommends that your Base and Compute clusters each run the same version of CDH. The Wizard will offer the option to choose other versions, but these combinations have not been tested and are not supported for production use.
- On the Select Services screen, choose any of the pre-configured combinations of services listed on this page, or you can select Custom Services and choose the services you want to install. The following services can be installed on a Compute cluster:
- Hive Execution Service (This service supplies the HiveServer2 role only.)
- Hue
- Impala
- Kafka
- Spark 2
- Oozie (only when Hue is available, and is a requirement for Hue)
- YARN
- HDFS (required)
- If you have enabled Kerberos authentication on the Base cluster, you must also enable Kerberos on the Compute cluster.
Improvements for Virtual Private Clusters in CDH 6.3
The following features have been added for Virtual Private Clusters:
Navigator Audit Support
Audits are now generated and available via Navigator for compute clusters.
Impala Improvements
Impala Data Caching
When the storage of an Impala cluster is not co-located with the Impala executor nodes (e.g. S3, remote HDFS data node in multi-cluster configuration), reads from remote storage may result in higher latency or become network bound for scan-heavy queries. Starting CDH 6.3.0, Impala implements a data cache backed by local storage of the executors to allow remote data to be cached in the local storage. The fixed capacity cache transparently caches HDFS blocks of remote reads and uses LRU eviction policy. If sized correctly, the query latency will be on-par with HDFS local reads configuration. The cache will not persist across restart. The cache is disabled by default.
See Impala Remote Data Cache for the information and steps to enable remote data cache.
Automatic refresh/invalidation of tables on CatalogD
When there are multiple Impala compute clusters deployed that all talk to the same HMS, it is possible that data inserted from one Impala cluster is not visible to another Impala cluster without issuing a manual refresh/invalidate command. Starting 6.3.0 Impala will generate INSERT events when data is inserted in to tables. These INSERT events are fetched at regular intervals by all the Impala clusters from HMS to automatically refresh the tables as needed. Note that this behavior is applicable only when --hms_event_polling_interval_s is set to a non-zero value.
Hive Improvements
The scratch directory for temporary tables is now stored on HDFS in the compute cluster; this helps with avoiding contention on the base cluster HDFS when multiple Hive / HiveServer 2 compute clusters are set up and temporary tables are used during Hive queries.
Hue Improvements
Hue file browser now points at the base cluster HDFS instead of the Compute cluster’s local HDFS. This helps the Hue end user on compute clusters see the base cluster HDFS.
