Setting up an End-to-End Data Streaming Pipeline
Data Streaming Pipeline
The data streaming pipeline as shown here is the most common usage of Kafka.
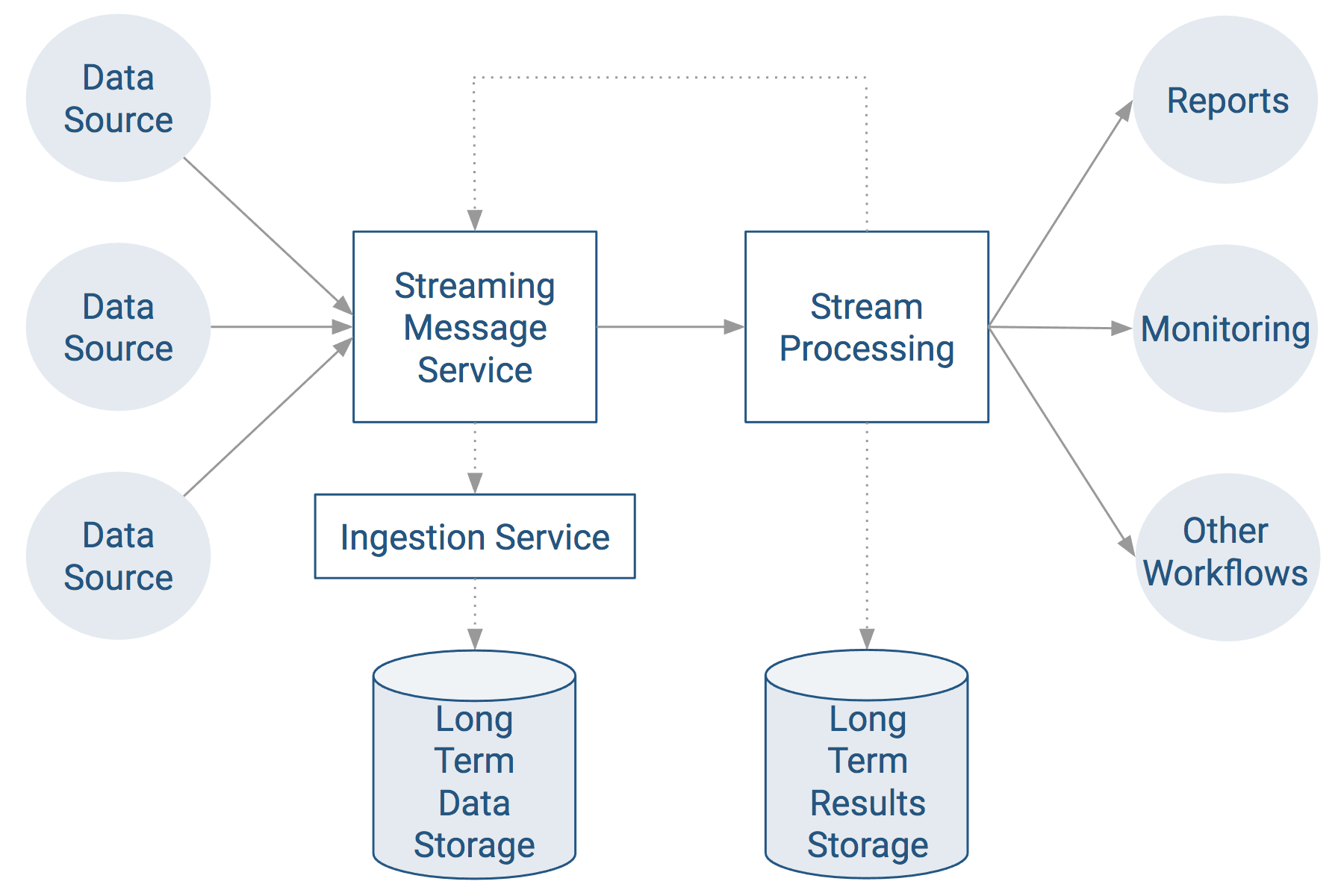
Some things to note about the data streaming pipeline model:
- Most systems have multiple data sources sending data over the Internet, such as per store or per device.
- The ingestion service usually saves older data to some form of long-term data storage.
- The stream processing service can perform near real-time computation on the data extracted from the message service, such as processing transactions, detecting fraud, or alerting systems.
- The results of stream processing can be sent directly to another service (such as for reporting) or can be streamed back into Kafka for one or more other services to do further real time processing.
The following sections show how other components in CDH map into the data streaming model.
Ingest Using Kafka with Apache Flume
Apache Flume is commonly used to collect Kafka topics into a long-term data store.
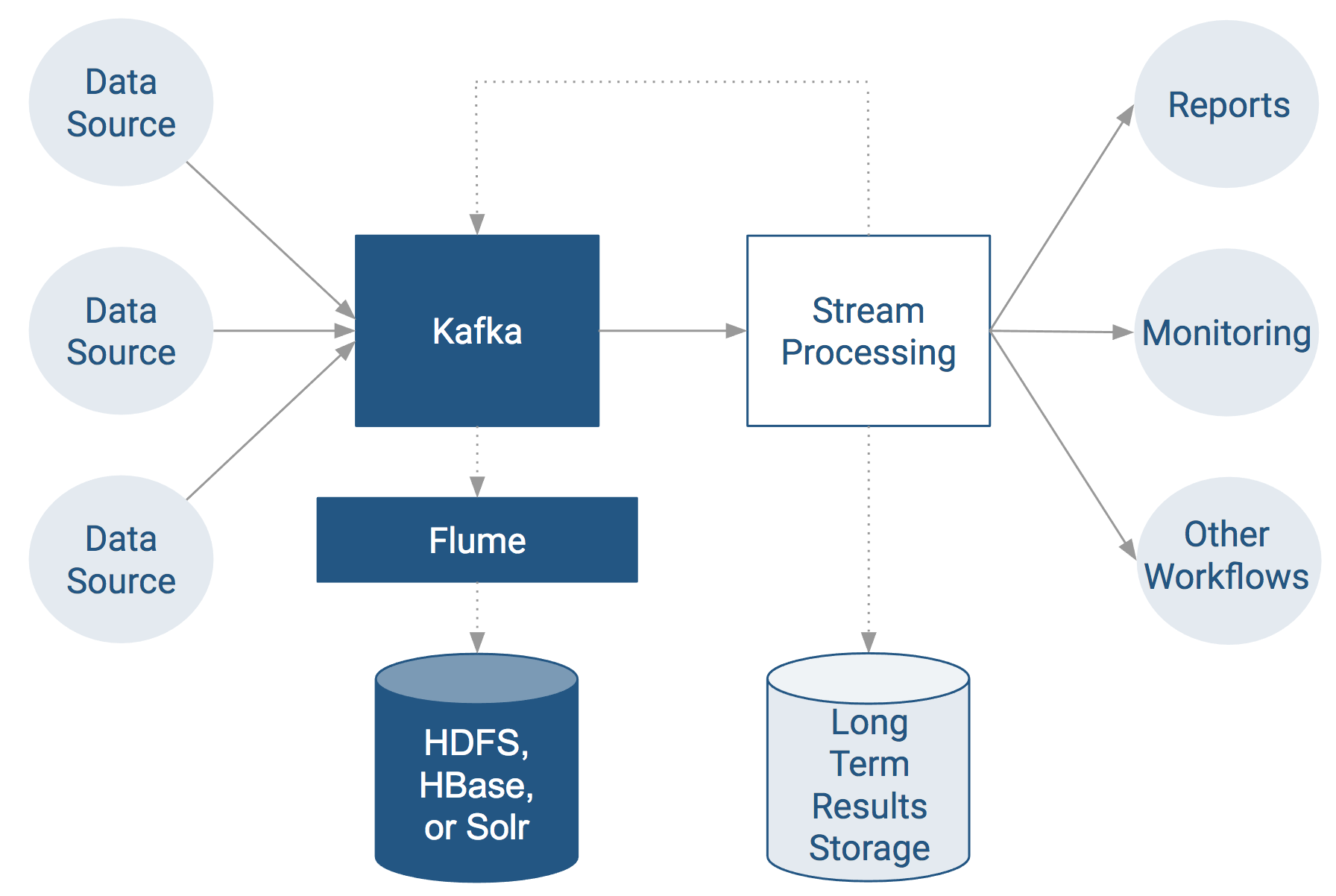
For information on configuring Kafka to securely communicate with Flume, see Configuring Flume Security with Kafka. The following sections describe how to configure Kafka sub-components for directing topics to long-term storage:
Continue reading:
Sources
Use the Kafka source to stream data in Kafka topics to Hadoop. The Kafka source can be combined with any Flume sink, making it easy to write Kafka data to HDFS, HBase, and Solr.
The following Flume configuration example uses a Kafka source to send data to an HDFS sink:
tier1.sources = source1
tier1.channels = channel1
tier1.sinks = sink1
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.zookeeperConnect = zk01.example.com:2181
tier1.sources.source1.topic = weblogs
tier1.sources.source1.groupId = flume
tier1.sources.source1.channels = channel1
tier1.sources.source1.interceptors = i1
tier1.sources.source1.interceptors.i1.type = timestamp
tier1.sources.source1.kafka.consumer.timeout.ms = 100
tier1.channels.channel1.type = memory
tier1.channels.channel1.capacity = 10000
tier1.channels.channel1.transactionCapacity = 1000
tier1.sinks.sink1.type = hdfs
tier1.sinks.sink1.hdfs.path = /tmp/kafka/%{topic}/%y-%m-%d
tier1.sinks.sink1.hdfs.rollInterval = 5
tier1.sinks.sink1.hdfs.rollSize = 0
tier1.sinks.sink1.hdfs.rollCount = 0
tier1.sinks.sink1.hdfs.fileType = DataStream
tier1.sinks.sink1.channel = channel1
For higher throughput, configure multiple Kafka sources to read from the same topic. If you configure all the sources with the same groupID, and the topic contains multiple partitions, each source reads data from a different set of partitions, improving the ingest rate.
The following table describes parameters that the Kafka source supports. Required properties are listed in bold.
| Property Name | Default Value | Description |
|---|---|---|
| type | Must be set to org.apache.flume.source.kafka.KafkaSource. | |
| zookeeperConnect | The URI of the ZooKeeper server or quorum used by Kafka. This can be a single host (for example, zk01.example.com:2181) or a comma-separated list of hosts in a ZooKeeper quorum (for example, zk01.example.com:2181,zk02.example.com:2181, zk03.example.com:2181). | |
| topic | The Kafka topic from which this source reads messages. Flume supports only one topic per source. | |
| groupID | flume | The unique identifier of the Kafka consumer group. Set the same groupID in all sources to indicate that they belong to the same consumer group. |
| batchSize | 1000 | The maximum number of messages that can be written to a channel in a single batch. |
| batchDurationMillis | 1000 | The maximum time (in ms) before a batch is written to the channel. The batch is written when the batchSize limit or batchDurationMillis limit is reached, whichever comes first. |
| Other properties supported by the Kafka consumer | Used to configure the Kafka consumer used by the Kafka source. You can use any consumer properties supported by Kafka. Prepend the consumer property name with the prefix kafka. (for example, kafka.fetch.min.bytes). See the Apache Kafka documentation topic Consumer Configs for the full list of Kafka consumer properties. |
Source Tuning Notes
The Kafka source overrides two Kafka consumer parameters:
- auto.commit.enable is set to false by the source, committing every batch. For improved performance, set this parameter to true using the kafka.auto.commit.enable setting. Note that this change can lead to data loss if the source goes down before committing.
- consumer.timeout.ms is set to 10, so when Flume polls Kafka for new data, it waits no more than 10 ms for the data to be available. Setting this parameter to a higher value can reduce CPU utilization due to less frequent polling, but the trade-off is that it introduces latency in writing batches to the channel.
Kafka Sinks
Use the Kafka sink to send data to Kafka from a Flume source. You can use the Kafka sink in addition to Flume sinks, such as HBase or HDFS.
The following Flume configuration example uses a Kafka sink with an exec source:
tier1.sources = source1
tier1.channels = channel1
tier1.sinks = sink1
tier1.sources.source1.type = exec
tier1.sources.source1.command = /usr/bin/vmstat 1
tier1.sources.source1.channels = channel1
tier1.channels.channel1.type = memory
tier1.channels.channel1.capacity = 10000
tier1.channels.channel1.transactionCapacity = 1000
tier1.sinks.sink1.type = org.apache.flume.sink.kafka.KafkaSink
tier1.sinks.sink1.topic = sink1
tier1.sinks.sink1.brokerList = kafka01.example.com:9092,kafka02.example.com:9092
tier1.sinks.sink1.channel = channel1
tier1.sinks.sink1.batchSize = 20
The following table describes parameters the Kafka sink supports. Required properties are listed in bold.
| Property Name | Default Value | Description | ||||||
|---|---|---|---|---|---|---|---|---|
| type | Must be set to org.apache.flume.sink.kafka.KafkaSink. | |||||||
| brokerList | The brokers the Kafka sink uses to discover topic partitions, formatted as a comma-separated list of hostname:port entries. You do not need to specify the entire list of brokers, but you specify at least two for high availability. | |||||||
| topic | default-flume-topic | The Kafka topic to which messages are published by default. If the event header contains a topic field, the event is published to the designated topic, overriding the configured topic. | ||||||
| batchSize | 100 | The number of messages to process in a single batch. Specifying a larger batchSize can improve throughput and increase latency. | ||||||
| request.required.acks | 0 | The number of replicas that must acknowledge a message before it is written successfully. Possible values are:
To avoid potential loss of data in case of a leader failure, set this to -1. |
||||||
| Other properties supported by the Kafka producer | Used to configure the Kafka producer used by the Kafka sink. You can use any producer properties supported by Kafka. Prepend the producer property name with the prefix kafka (for example, kafka.compression.codec). See the Apache Kafka documentation topic Producer Configs for the full list of Kafka producer properties. |
The Kafka sink uses the topic and key properties from the FlumeEvent headers to determine where to send events in Kafka. If the header contains the topic property, that event is sent to the designated topic, overriding the configured topic. If the header contains the key property, that key is used to partition events within the topic. Events with the same key are sent to the same partition. If the key parameter is not specified, events are distributed randomly to partitions. Use these properties to control the topics and partitions to which events are sent through the Flume source or interceptor.
Kafka Channels
CDH includes a Kafka channel to Flume in addition to the existing memory and file channels. You can use the Kafka channel:
- To write to Hadoop directly from Kafka without using a source.
- To write to Kafka directly from Flume sources without additional buffering.
- As a reliable and highly available channel for any source/sink combination.
The following Flume configuration uses a Kafka channel with an exec source and HDFS sink:
tier1.sources = source1
tier1.channels = channel1
tier1.sinks = sink1
tier1.sources.source1.type = exec
tier1.sources.source1.command = /usr/bin/vmstat 1
tier1.sources.source1.channels = channel1
tier1.channels.channel1.type = org.apache.flume.channel.kafka.KafkaChannel
tier1.channels.channel1.capacity = 10000
tier1.channels.channel1.zookeeperConnect = zk01.example.com:2181
tier1.channels.channel1.parseAsFlumeEvent = false
tier1.channels.channel1.topic = channel2
tier1.channels.channel1.consumer.group.id = channel2-grp
tier1.channels.channel1.auto.offset.reset = earliest
tier1.channels.channel1.kafka.bootstrap.servers = kafka02.example.com:9092,kafka03.example.com:9092
tier1.channels.channel1.transactionCapacity = 1000
tier1.channels.channel1.kafka.consumer.max.partition.fetch.bytes=2097152
tier1.sinks.sink1.type = hdfs
tier1.sinks.sink1.hdfs.path = /tmp/kafka/channel
tier1.sinks.sink1.hdfs.rollInterval = 5
tier1.sinks.sink1.hdfs.rollSize = 0
tier1.sinks.sink1.hdfs.rollCount = 0
tier1.sinks.sink1.hdfs.fileType = DataStream
tier1.sinks.sink1.channel = channel1
The following table describes parameters the Kafka channel supports. Required properties are listed in bold.
| Property Name | Default Value | Description |
|---|---|---|
| type | Must be set to org.apache.flume.channel.kafka.KafkaChannel. | |
| brokerList | The brokers the Kafka channel uses to discover topic partitions, formatted as a comma-separated list of hostname:port entries. You do not need to specify the entire list of brokers, but you should specify at least two for high availability. | |
| zookeeperConnect | The URI of the ZooKeeper server or quorum used by Kafka. This can be a single host (for example, zk01.example.com:2181) or a comma-separated list of hosts in a ZooKeeper quorum (for example, zk01.example.com:2181,zk02.example.com:2181, zk03.example.com:2181). | |
| topic | flume-channel | The Kafka topic the channel will use. |
| groupID | flume | The unique identifier of the Kafka consumer group the channel uses to register with Kafka. |
| parseAsFlumeEvent | true | Set to true if a Flume source is writing to the channel and expects AvroDataums with the FlumeEvent schema (org.apache.flume.source.avro.AvroFlumeEvent) in the channel. Set to false if other producers are writing to the topic that the channel is using. |
| auto.offset.reset | latest |
What to do when there is no initial offset in Kafka or if the current offset does not exist on the server (for example, because the data is deleted).
|
| kafka.consumer.timeout.ms | 100 | Polling interval when writing to the sink. |
| consumer.max.partition.fetch.bytes | 1048576 | The maximum amount of data per-partition the server will return. |
| Other properties supported by the Kafka producer | Used to configure the Kafka producer. You can use any producer properties supported by Kafka. Prepend the producer property name with the prefix kafka. (for example, kafka.compression.codec). See the Apache Kafka documentation topic Producer Configs for the full list of Kafka producer properties. |
CDH Flume Kafka Compatibility
The section Client/Broker Compatibility Across Kafka Versions covered the basics of Kafka client/broker compatibility. Flume has an embedded Kafka client which it uses to talk to Kafka clusters. Since the generally accepted practice is to have the broker running the same or newer version as the client, a CDH Flume version requires being matched to a minimum Kafka version. This is illustrated in the table below.
| CDH Flume Version | Embedded Kafka Client Version | Minimum Supported CDH Kafka Version (Remote or Local) |
|---|---|---|
| CDH 6.0.0 | 1.0.1 | CDH 6.0.0 |
| CDH 5.14.x | 0.10.2-kafka-2.2.0 | Kafka 2.2 |
| CDH 5.13.x | 0.9.0-kafka-2.0.2 | Kafka 2.0 |
| CDH 5.12.x | 0.9.0-kafka-2.0.2 | Kafka 2.0 |
| CDH 5.11.x | 0.9.0-kafka-2.0.2 | Kafka 2.0 |
| CDH 5.10.x | 0.9.0-kafka-2.0.2 | Kafka 2.0 |
| CDH 5.9.x | 0.9.0-kafka-2.0.2 | Kafka 2.0 |
| CDH 5.8.x | 0.9.0-kafka-2.0.0 | Kafka 2.0 |
| CDH 5.7.x | 0.9.0-kafka-2.0.0 | Kafka 2.0 |
Securing Flume with Kafka
When using Flume with a secured Kafka service, you can use Cloudera Manager to generate security related Flume agent configuration.
In Cloudera Manager, on the Flume Configuration page, select the Kafka service you want to connect to. This generates the following files:
- flume.keytab
- jaas.conf
It also generates security protocol and Kerberos service name properties for the Flume agent configuration. If TLS/SSL is also configured for Kafka brokers, the setting also adds SSL truststore properties to the beginning of the Flume agent configuration.
Review the deployed agent configuration and if the defaults do not match your environment (such as the truststore password), you can override the settings by adding the same property to the agent configuration.
Using Kafka with Apache Spark Streaming for Stream Processing
For real-time stream computation, Apache Spark is the tool of choice in CDH.
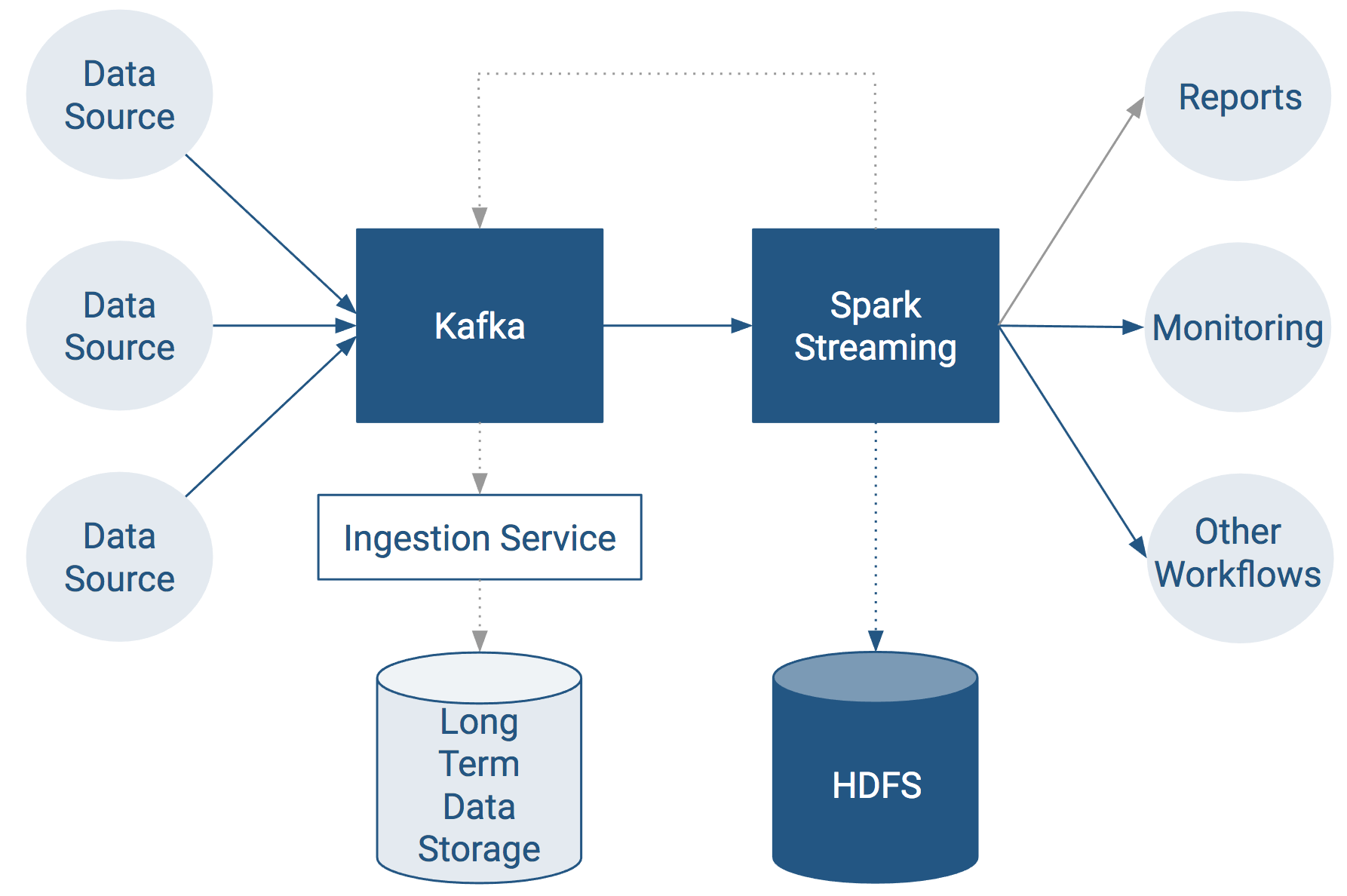
CDH Spark/Kafka Compatibility
The section Client/Broker Compatibility Across Kafka Versions covered the basics of Kafka client/broker compatibility. Spark maintains two embedded Kafka clients and can be configured to use either one. This table in the Apache Spark documentation illustrates the two clients that are available.
For information on how to configure Spark Streaming to receive data from Kafka, refer to the Kafka version you are using in the following table.
| CDH Spark Version | Embedded Kafka Client (Choose based on Kafka cluster) | Minimum Apache Kafka Version | Minimum CDH Kafka Version (Remote or Local) | Upstream Integration Guide | API Stability |
|---|---|---|---|---|---|
| CDH 6.0 | spark-streaming-kafka-0-10 | 0.10.0 | Kafka 2.1 | Spark 2.2 + Kafka 0.10 | Stable |
| CDH 6.0 | spark-streaming-kafka-0-8 | 0.8.2.1 | Kafka 2.0 | Spark 2.2 + Kafka 0.8 | Deprecated |
| Spark 2.2 | spark-streaming-kafka-0-10 | 0.10.0 | Kafka 2.1 | Spark 2.2 + Kafka 0.10 | Experimental |
| Spark 2.2 | spark-streaming-kafka-0-8 | 0.8.2.1 | Kafka 2.0 | Spark 2.2 + Kafka 0.8 | Stable |
| Spark 2.1 | spark-streaming-kafka-0-10 | 0.10.0 | Kafka 2.1 | Spark 2.1 + Kafka 0.10 | Experimental |
| Spark 2.1 | spark-streaming-kafka-0-8 | 0.8.2.1 | Kafka 2.0 | Spark 2.1 + Kafka 0.8 | Stable |
| Spark 2.0 | spark-streaming-kafka-0-8 | 0.8.2.? | Kafka 2.0 | Spark 2.0 + Kafka | Stable |
Validating Kafka Integration with Spark Streaming
To validate your Kafka integration with Spark Streaming, run the KafkaWordCount example in Spark.
If you installed Spark using parcels, use the following command:
/opt/cloudera/parcels/CDH/lib/spark/bin/run-example streaming.KafkaWordCount zkQuorum group topics numThreads
If you installed Spark using packages, use the following command:
/usr/lib/spark/bin/run-example streaming.KafkaWordCount zkQuorum group topics numThreads
Replace the variables as follows:
- zkQuorum: ZooKeeper quorum URI used by Kafka For example:
zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181
- group: Consumer group used by the application.
- topics: Kafka topic containing the data for the application.
- numThreads: Number of consumer threads reading the data. If this is higher than the number of partitions in the Kafka topic, some threads will be idle.
Securing Spark with Kafka
Using Spark Streaming with a Kafka service that’s already secured requires configuration changes on the Spark side. You can find a nice description of the required changes in the spark-dstream-secure-kafka-app sample project on GitHub.
