Kafka Brokers
This section covers some of how a broker operates in greater detail. As we go over some of these details, we will illustrate how these pieces can cause brokers to have issues.
Single Cluster Scenarios
The figure below shows a simplified version of a Kafka cluster in steady state. There are N brokers, two topics with nine partitions each. The M replicated partitions are not shown for simplicity. This is going to be the baseline for discussions in later sections.
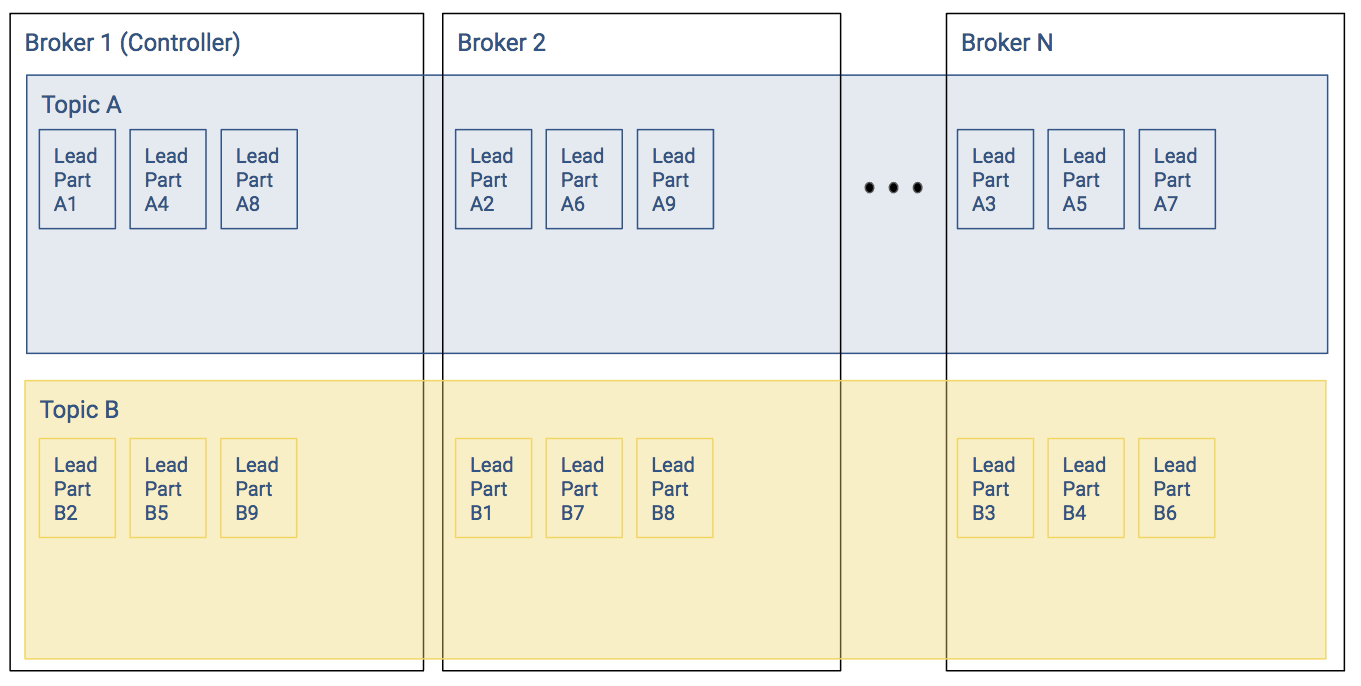
Leader Positions
In the baseline example, each broker shown has three partitions per topic. In the figure above, the Kafka cluster has well balanced leader partitions. Recall the following:
- Producer writes and consumer reads occur at the partition level
- Leader partitions are responsible for ensuring that the follower partitions keep their records in sync
In the baseline example, since the leader partitions were evenly distributed, most of the time the load to the overall Kafka cluster will be relatively balanced.
In the example below, since a large chunk of the leaders for Topic A and Topic B are on Broker 1, a lot more of the overall Kafka workload will occur at Broker 1. This will cause a backlog of work, which slows down the cluster throughput, which will worsen the backlog.
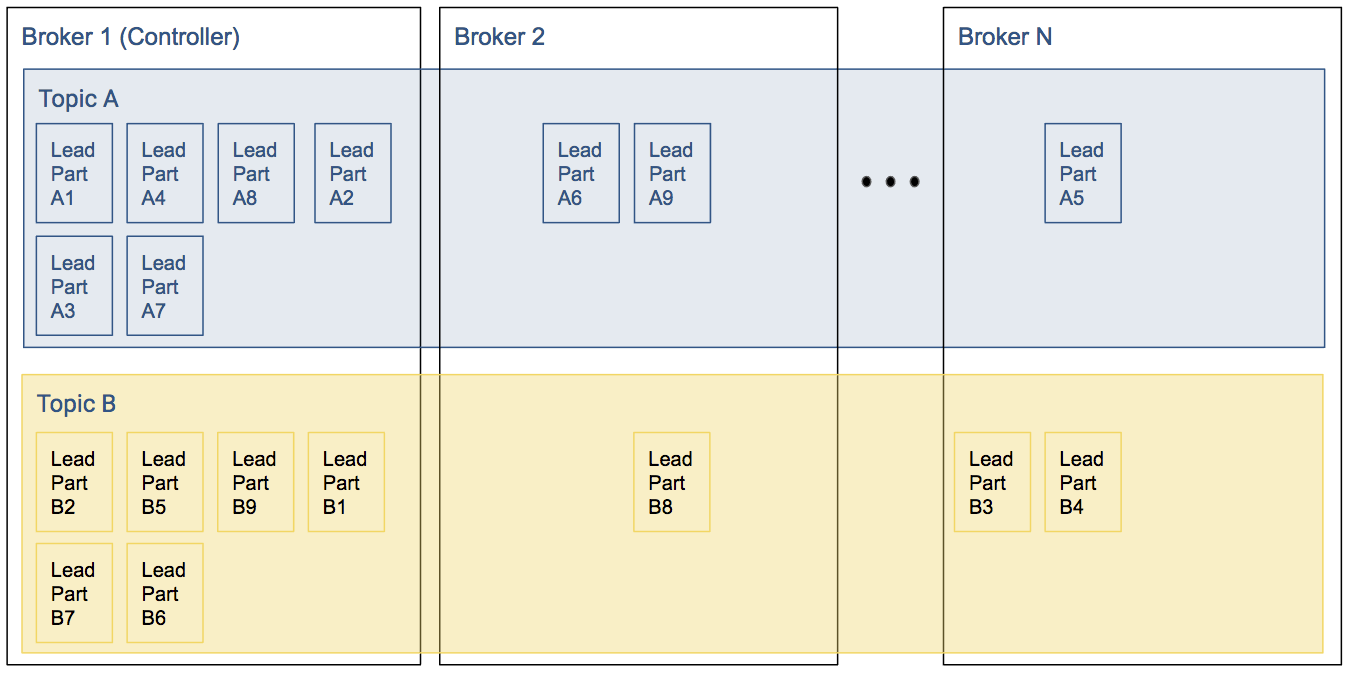
Even if a cluster starts with perfectly balanced topics, failures of brokers can cause these imbalances: if leader of a partition goes down one of the replicas will become the leader. When the original (preferred) leader comes back, it will get back leadership only if automatic leader rebalancing is enabled; otherwise the node will become a replica and the cluster gets imbalanced.
In-Sync Replicas
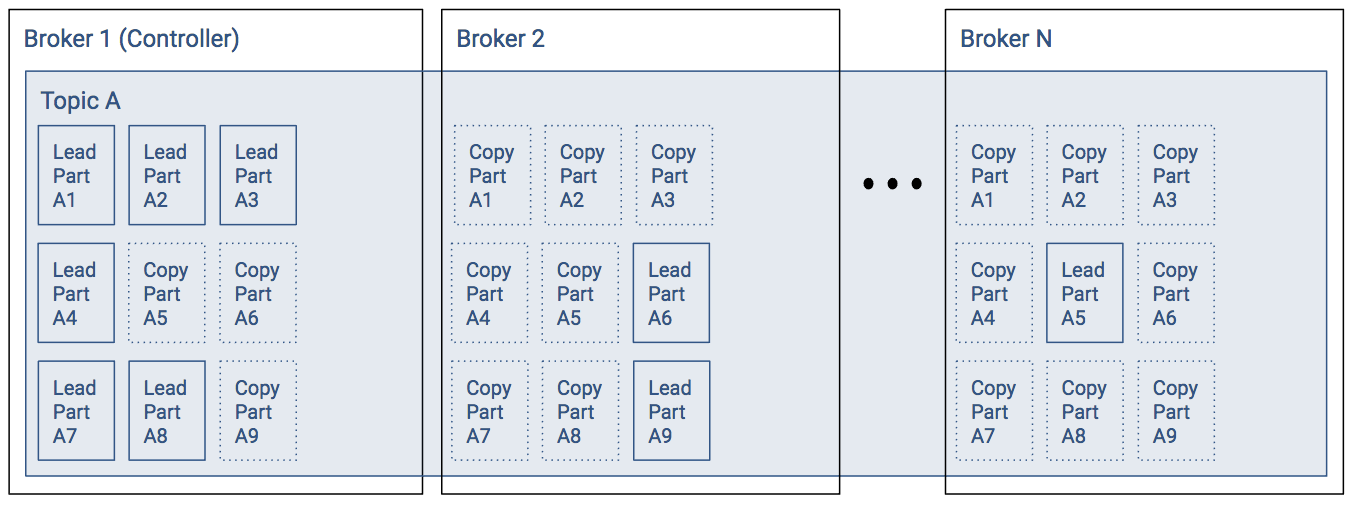
Let’s look at Topic A from the previous example with follower partitions:
- Broker 1 has six leader partitions, broker 2 has two leader partitions, and broker 3 has one leader partition.
- Assuming a replication factor of 3.
Assuming all replicas are in-sync, then any leader partition can be moved from Broker 1 to another broker without issue. However, in the case where some of the follower partitions have not caught up, then the ability to change leaders or have a leader election will be hampered.
Topic Configuration
We already introduced the concept of topics. When managing a Kafka cluster, configuring a topic can require some planning. For small clusters or low record throughput, topic planning isn’t particularly tricky, but as you scale to the large clusters and high record throughput, such planning becomes critical.
Topic Creation
To be able to use a topic, it has to be created. This can happen automatically or manually. When enabled, the Kafka cluster creates topics on demand.
Automatic Topic Creation
If auto.create.topics.enable is set to true and a client is requesting metadata about a non-existent topic, then the broker will create a topic with the given name. In this case, its replication factor and partition count is derived from the broker configuration. Corresponding configuration entries are default.replication.factor and num.partitions. The default value for each these properties is 1. This means the topic will not scale well and will not be tolerant to broker failure. It is recommended to set these default value higher or even better switching off this feature and creating topics manually with configuration suited for the use case at hand.
Topic Properties
There are numerous properties that influence how topics are handled by the cluster. These can be set with kafka-topics tool on topic creation or later on with kafka-configs. The most commonly used properties are:
- min.insync.replicas: specifies how many brokers have to replicate the records before the leader sends back an acknowledgment to the producer (if producer property acks is set to all). With a replication factor of 3, a minimum in-sync replicas of 2 guarantees a higher level of durability. It is not recommended that you set this value equal to the replication factor as it makes producing to the topic impossible if one of the brokers is temporarily down.
- retention.bytes and retention.ms: determines when a record is considered outdated. When data stored in one partition exceeds given limits, broker starts a cleanup to save disk space.
- segment.bytes and segment.ms: determines how much data is stored in the same log segment (that is, in the same file). If any of these limits is reached, a new log segment is created.
- unclean.leader.election.enable: if true, replicas that are not in-sync may be elected as new leaders. This only happens when there are no live replicas in-sync. As enabling this feature may result in data loss, it should be switched on only if availability is more important than durability.
- cleanup.policy: either delete or compact. If delete is set, old log segments will be deleted. Otherwise, only the latest record is retained. This process is called log compaction. This is covered in greater detail in the Record Management section.
If you do not specify these properties, the prevailing broker level configuration will take effect. A complete list of properties can be found in the Topic-Level Configs section of the Apache Kafka documentation.
Partition Management
Partitions are at the heart of how Kafka scales performance. Some of the administrative issues around partitions can be some of the biggest challenges in sustaining high performance.
When creating a topic, you specify which brokers should have a copy of which partition or you specify replication factor and number of partitions and the controller generates a replica assignment for you. If there are multiple brokers that are assigned a partition, the first one in the list is always the preferred leader.
Whenever the leader of a partition goes down, Kafka moves leadership to another broker. Whether this is possible depends on the current set of in-sync replicas and the value of unclean.leader.election.enable. However, no new Kafka broker will start to replicate the partition to reach replication factor again. This is to avoid unnecessary load on brokers when one of them is temporarily down. Kafka will regularly try to balance leadership between brokers by electing the preferred leader. But this balance is based on number of leaderships and not throughput.
Partition Reassignment
In some cases require manual reassignment of partitions:
- If the initial distribution of partitions and leaderships creates an uneven load on brokers.
- If you want to add or remove brokers from the cluster.
Use kafka-reassign-partitions tool to move partitions between brokers. The typical workflow consist of the following:
- Generate a reassignment file by specifying topics to move and which brokers to move to (by setting --topic-to-move-json-file and --broker-list to --generate command).
- Optionally edit the reassignment file and verify it with the tool.
- Actually re-assigning partitions (with option --execute).
- Verify if the process has finished as intended (with option --verify).
Adding Partitions
You can use kafka-topics tool to increase the number of partitions in a given topic. However, note that adding partitions will in most cases break the guarantee preserving the order of records with the same key, because it changes which partition a record key is produced to. Although order of records is preserved for both the old partition the key was produced to and the new one, it still might happen that records from the new partition are consumed before records from the old one.
Choosing the Number of Partitions
When choosing the number of partitions for a topic, you have to consider the following:
- More partitions mean higher throughput.
- You should not have more than a few tens of thousands of partitions in a Kafka cluster.
- In case of an unclean shutdown of one of the brokers, the partitions it was leader for have to be led by other brokers and moving leadership for a few thousand partitions one by one can take seconds of unavailability.
- Kafka keeps all log segment files open at all times. More partitions can mean more file handles to have open.
- More partitions can cause higher latency.
Controller
The controller is one of the brokers that has additional partition and replica management responsibilities. It will control / be involved whenever partition metadata or state is changed, such as when:
- Topics or partitions are created or deleted.
- Brokers join or leave the cluster and partition leader or replica reassignment is needed.
It also tracks the list of in sync replicas (ISRs) and maintains broker, partition, and ISR data in Zookeeper.
Controller Election
Any of the brokers can play the role of the controller, but in a healthy cluster there is exactly one controller. Normally this is the broker that started first, but there are certain situations when a re-election is needed:
- If the controller is shut down or crashes.
- If it loses connection to Zookeeper.
When a broker starts or participates in controller reelection, it will attempt to create an ephemeral node (“/controller”) in ZooKeeper. If it succeeds, the broker becomes the controller. If it fails, there is already a controller, but the broker will watch the node.
If the controller loses connection to ZooKeeper or stops ZooKeeper will remove the ephemeral node and the brokers will get a notification to start a controller election.
Every controller election will increase the “controller epoch”. The controller epoch is used to detect situations when there are multiple active controllers: if a broker gets a message with a lower epoch than the result of the last election, it can be safely ignored. It is also used to detect a “split brain” situation when multiple nodes believe that they are in the controller role.
Having 0 or 2+ controllers means the cluster is in a critical state, as broker and partition state changes are blocked. Therefore it’s important to ensure that the controller has a stable connection to ZooKeeper to avoid controller elections as much as possible.
