Removing the Hive Compilation Lock
Removing the Hive compilation lock allows a defined number of queries to compile in parallel on one HiveServer2 instance. For instances with numerous sessions, turning off the compilation lock prevents additional queries from stopping due to a long compilation. Use this guide to plan and safely remove the compilation lock on your HiveServer2 instance.
Before Removing the Compilation Lock
Before removing the compilation lock, it’s important to be certain it is the cause of any slow compiling queries. You can do this by checking for any long compiling queries in the waiting_compile_ops metric.
If you discover queries awaiting compilation for a long time, turning off the compilation lock could be an option to prevent a bottleneck. However, before turning off the compilation lock, read Fine-tuning the Degree of Parallelism to check you meet the HMS memory requirements.
Removing the Compilation Lock
Follow these steps to turn off the compilation lock in Cloudera Manager.
- Log in to the Cloudera Manager Admin Console.
- Click Clusters in the top navigation bar, and choose Hive from the list of service instances.
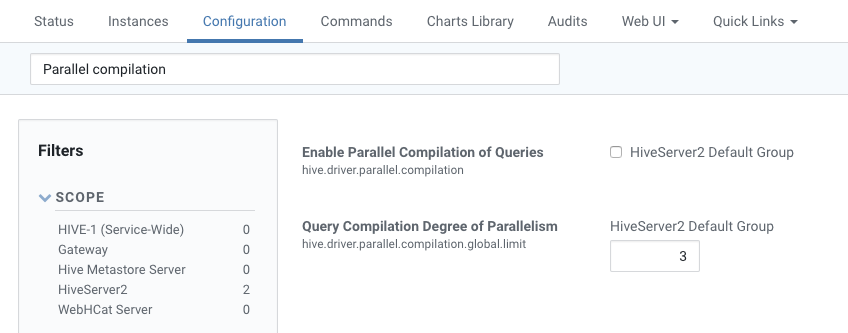
- Click the Configuration tab on the Hive service page to edit the configuration.
- In the Search field, search for Parallel compilation, the results display two configuration options:
-
Enable Parallel Compilation of Queries
Select this to turn off the compilation lock and allow parallel compilation.
-
Query Compilation Degree of Parallelism
This defines the number of workers that can compile queries in parallel. To learn how to set the degree of parallelism, read Fine-Tuning the Degree of Parallelism.
-
- Enter a Reason for change, and then click Save Changes to commit the changes.
- After your change is saved, click the restarticon above the Configuration tab.
If you don’t see the reset icon, try refreshing your browser.
- Click Restart Stale Services, and then click Restart Now.
- Click Finish after the restart completes.
Fine-Tuning the Degree of Parallelism
Use the following formula to fine-tune your degree of parallelization to the minimum amount of memory in your HMS:
(Number of HS2 nodes) X (degree of parallelization) X (10GB) memory in HMS
This formula uses an estimate of a 10 GB table and related partitions data size. HMS needs to store this in its memory and serve the requests which could come from all the HS2 nodes or additional systems—Spark, Flume, or further systems. The degree of parallelization determined how many requests can occur from each HS2 node.
After Turning Off the Compilation Lock
After turning off the compilation lock, it’s important to monitor other services to check they are not being affected. Cloudera recommends regular monitoring of:
- Hive Metastore memory usage - Heap size
- ZooKeeper memory usage - Heap size
- Sentry memory usage - Heap size
- Number of queries waiting for compilation - Queue size
If you discover memory issues, decrease the level of parallelism or add additional memory to the affected services.
If the memory metrics look good and there are still Queries Awaiting Compilation, increase the level parallelism. Learn more in Fine-tuning the Degree of Parallelism.
