Differences in data distribution
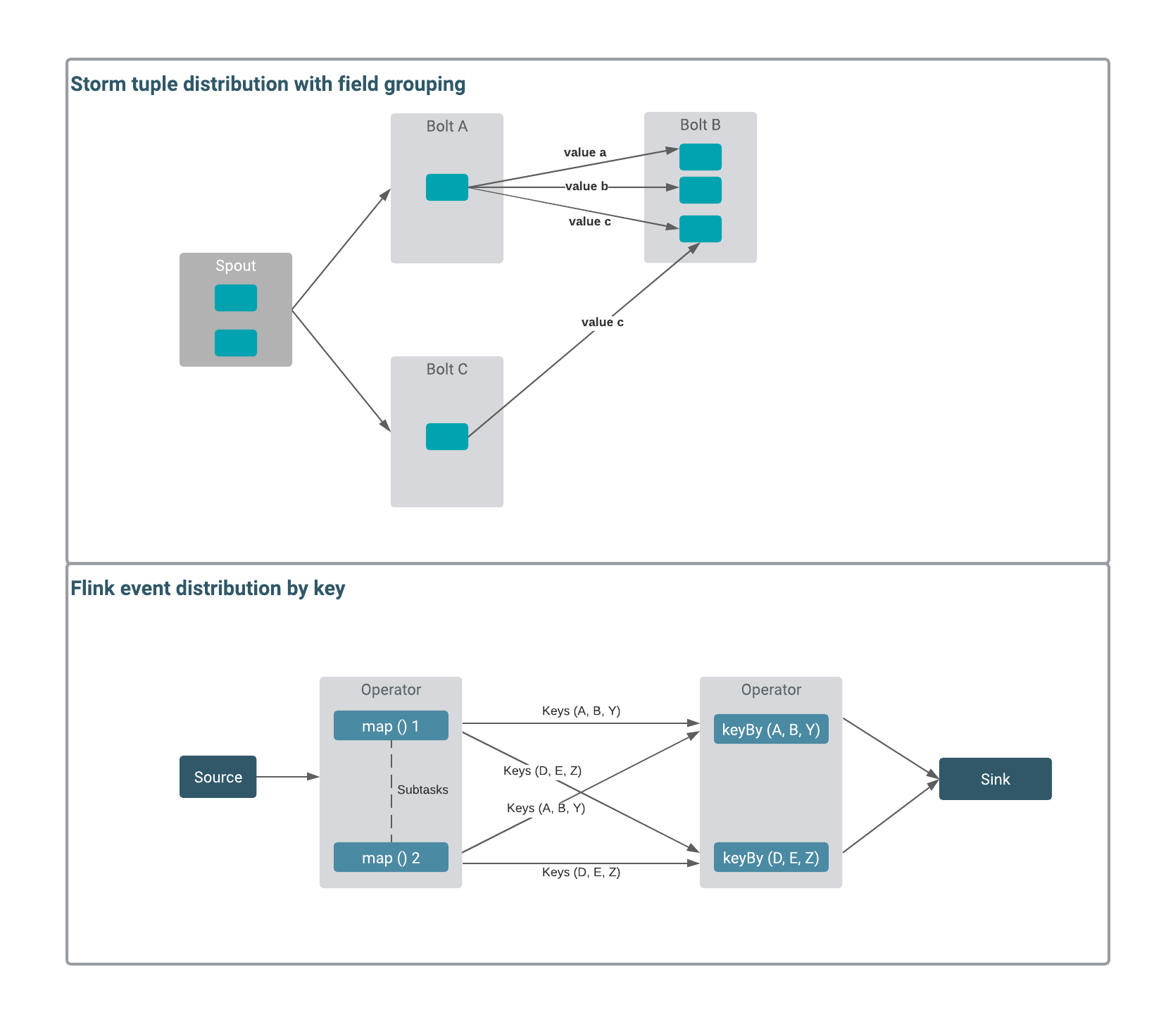
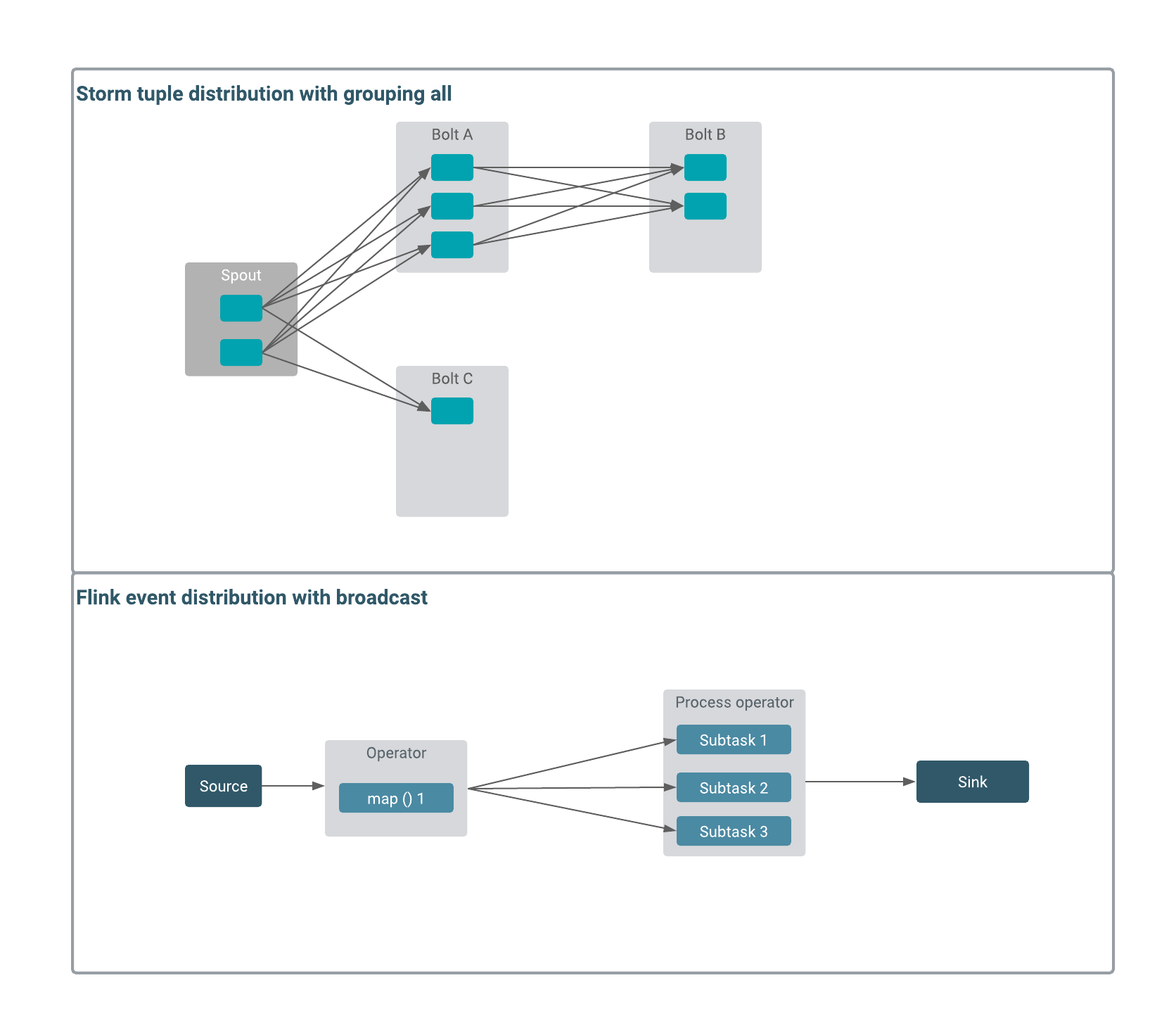
Both Flink and Storm distribute data within their processing elements. Stream grouping in Storm controls the routing of tuples. There is no similar function in Flink, but you can use keys and the broadcast function on your data stream to handle the distribution of events.
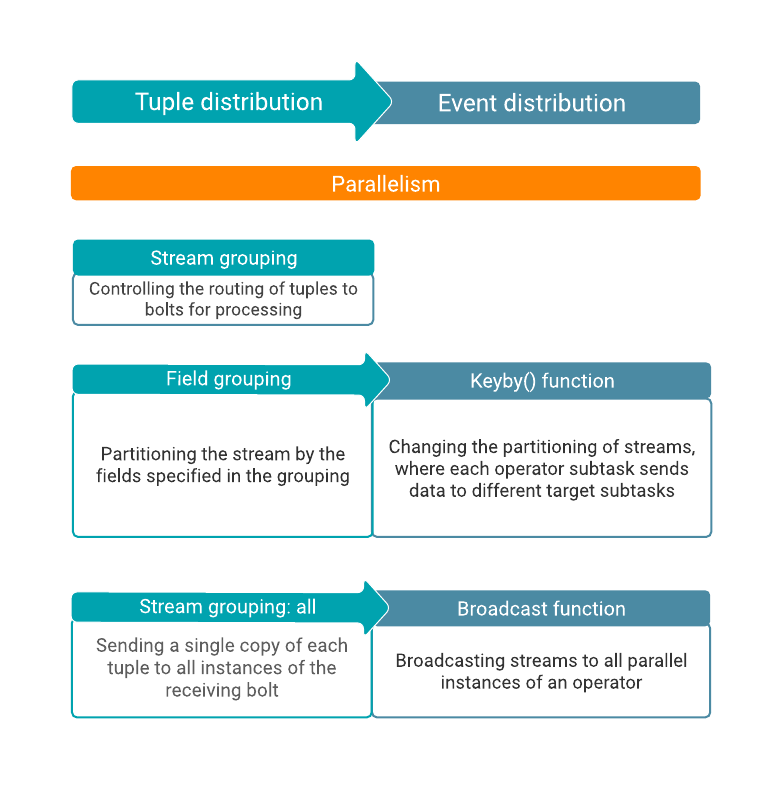
When exchanging data between the elements, Storm supports different methods that include shuffle, field, all, direct, custom, and global. These methods determine if all the data is shared between all bolts, or just certain data with defined fields. In Flink, you can achieve similar result using keys and the broadcast function. The keyBy function is used to partition and group the data together within the incoming stream by given properties or keys. When broadcasting, you share an incoming stream with all parallel instances of an operator. The most common use case for broadcast is sharing a set of rules or raw data within the operators. Like this, the operators process the stream, based on the same configuration, or they work on the same data for analytical purposes.
The following illustrations show the comparison of data distributing methods of Storm and Flink.