Configuring the HBase BlockCache
In the default configuration, HBase uses a single on-heap cache. If you configure the off-heap BucketCache, the on-heap cache is used for Bloom filters and indexes, and the off-heap BucketCache is used to cache data blocks. This is called the Combined Blockcache configuration. The Combined BlockCache allows you to use a larger in-memory cache while reducing the negative impact of garbage collection in the heap, because HBase manages the BucketCache instead of relying on the garbage collector.
Contents of the BlockCache
- Your data: Each time a Get or Scan operation occurs, the result is added to the BlockCache if it was not already cached there. If you use the BucketCache, data blocks are always cached in the BucketCache.
- Row keys: When a value is loaded into the cache, its row key is also cached. This is one reason to make your row keys as small as possible. A larger row key takes up more space in the cache.
- hbase:meta: The hbase:meta catalog table keeps track of which RegionServer is serving which regions. It can consume several megabytes of cache if you have a large number of regions, and has in-memory access priority, which means HBase attempts to keep it in the cache as long as possible.
- Indexes of HFiles: HBase stores its data in HDFS in a format called HFile. These HFiles contain indexes which allow HBase to seek for data within them without needing to open the entire HFile. The size of an index is a factor of the block size, the size of your row keys, and the amount of data you are storing. For big data sets, the size can exceed 1 GB per RegionServer, although the entire index is unlikely to be in the cache at the same time. If you use the BucketCache, indexes are always cached on-heap.
- Bloom filters: If you use Bloom filters, they are stored in the BlockCache. If you use the BucketCache, Bloom filters are always cached on-heap.
The sum of the sizes of these objects is highly dependent on your usage patterns and the characteristics of your data. For this reason, the HBase Web UI and Cloudera Manager each expose several metrics to help you size and tune the BlockCache.
Deciding Whether To Use the BucketCache
- If the result of a Get or Scan typically fits completely in the heap, the default configuration, which uses the on-heap LruBlockCache, is the best choice, as the L2 cache will not provide much benefit. If the eviction rate is low, garbage collection can be 50% less than that of the BucketCache, and throughput can be at least 20% higher.
- Otherwise, if your cache is experiencing a consistently high eviction rate, use the BucketCache, which causes 30-50% of the garbage collection of LruBlockCache when the eviction rate is high.
- BucketCache using file mode on solid-state disks has a better garbage-collection profile but lower throughput than BucketCache using off-heap memory.
Bypassing the BlockCache
If the data needed for a specific but atypical operation does not all fit in memory, using the BlockCache can be counter-productive, because data that you are still using may be evicted, or even if other data is not evicted, excess garbage collection can adversely effect performance. For this type of operation, you may decide to bypass the BlockCache. To bypass the BlockCache for a given Scan or Get, use the setCacheBlocks(false) method.
hbase> alter 'myTable', CONFIGURATION => {NAME => 'myCF', BLOCKCACHE => 'false'}Cache Eviction Priorities
Both the on-heap cache and the off-heap BucketCache use the same cache priority mechanism to decide which cache objects to evict to make room for new objects. Three levels of block priority allow for scan-resistance and in-memory column families. Objects evicted from the cache are subject to garbage collection.
-
Single access priority: The first time a block is loaded from HDFS, that block is given single access priority, which means that it will be part of the first group to be considered during evictions. Scanned blocks are more likely to be evicted than blocks that are used more frequently.
-
Multi access priority: If a block in the single access priority group is accessed again, that block is assigned multi access priority, which moves it to the second group considered during evictions, and is therefore less likely to be evicted.
-
In-memory access priority: If the block belongs to a column family which is configured with the in-memory configuration option, its priority is changed to in memory access priority, regardless of its access pattern. This group is the last group considered during evictions, but is not guaranteed not to be evicted. Catalog tables are configured with in-memory access priority.
To configure a column family for in-memory access, use the following syntax in HBase Shell:hbase> alter 'myTable', 'myCF', CONFIGURATION => {IN_MEMORY => 'true'}To use the Java API to configure a column family for in-memory access, use the HColumnDescriptor.setInMemory(true) method.
Sizing the BlockCache
When you use the LruBlockCache, the blocks needed to satisfy each read are cached, evicting older cached objects if the LruBlockCache is full. The size cached objects for a given read may be significantly larger than the actual result of the read. For instance, if HBase needs to scan through 20 HFile blocks to return a 100 byte result, and the HFile blocksize is 100 KB, the read will add 20 * 100 KB to the LruBlockCache.
number of RegionServers * heap size * hfile.block.cache.size * 0.99
To tune the size of the LruBlockCache, you can add RegionServers or increase the total Java heap on a given RegionServer to increase it, or you can tune hfile.block.cache.size to reduce it. Reducing it will cause cache evictions to happen more often, but will reduce the time it takes to perform a cycle of garbage collection. Increasing the heap will cause garbage collection to take longer but happen less frequently.
About the Off-heap BucketCache
- Off-heap: This is the default configuration.
- File-based: You can use the file-based storage mode to store the BucketCache on an SSD or FusionIO device,
hbase> alter 'myTable', CONFIGURATION => {CACHE_DATA_IN_L1 => 'true'}}Configuring the Off-heap BucketCache
| Property | Default | Description |
|---|---|---|
| hbase.bucketcache.combinedcache.enabled | true | When BucketCache is enabled, use it as a L2 cache for LruBlockCache. If set to true, indexes and Bloom filters are kept in the LruBlockCache and the data blocks are kept in the BucketCache. |
hbase.bucketcache.ioengine |
none (BucketCache is disabled by default) | Where to store the contents of the BucketCache. Its value can be offheap, file:PATH, mmap:PATH or pmem:PATH where PATH is the path to the file that host the file-based cache. |
hfile.block.cache.size |
0.4 | A float between 0.0 and 1.0. This factor multiplied by the Java heap size is the size of the L1 cache. In other words, the percentage of the Java heap to use for the L1 cache. |
hbase.bucketcache.size |
not set | When using BucketCache, this is a float that represents one of two
different values, depending on whether it is a floating-point decimal less than 1.0 or an integer greater than 1.0.
|
hbase.bucketcache.bucket.sizes |
4, 8, 16, 32, 40, 48, 56, 64, 96, 128, 192, 256, 384, 512 KB | A comma-separated list of sizes for buckets for the BucketCache if you prefer to use multiple sizes. The sizes should be multiples of the default blocksize, ordered from smallest to largest. The sizes you use will depend on your data patterns. This parameter is experimental. |
-XX:MaxDirectMemorySize |
MaxDirectMemorySize = BucketCache + 1 | A JVM option to configure the maximum amount of direct memory available to the JVM. It is automatically calculated and configured based on the following formula: MaxDirectMemorySize = BucketCache size + 1 GB for other features using direct memory, such as DFSClient. For example, if the BucketCache size is 8 GB, it will be -XX:MaxDirectMemorySize=9G. |
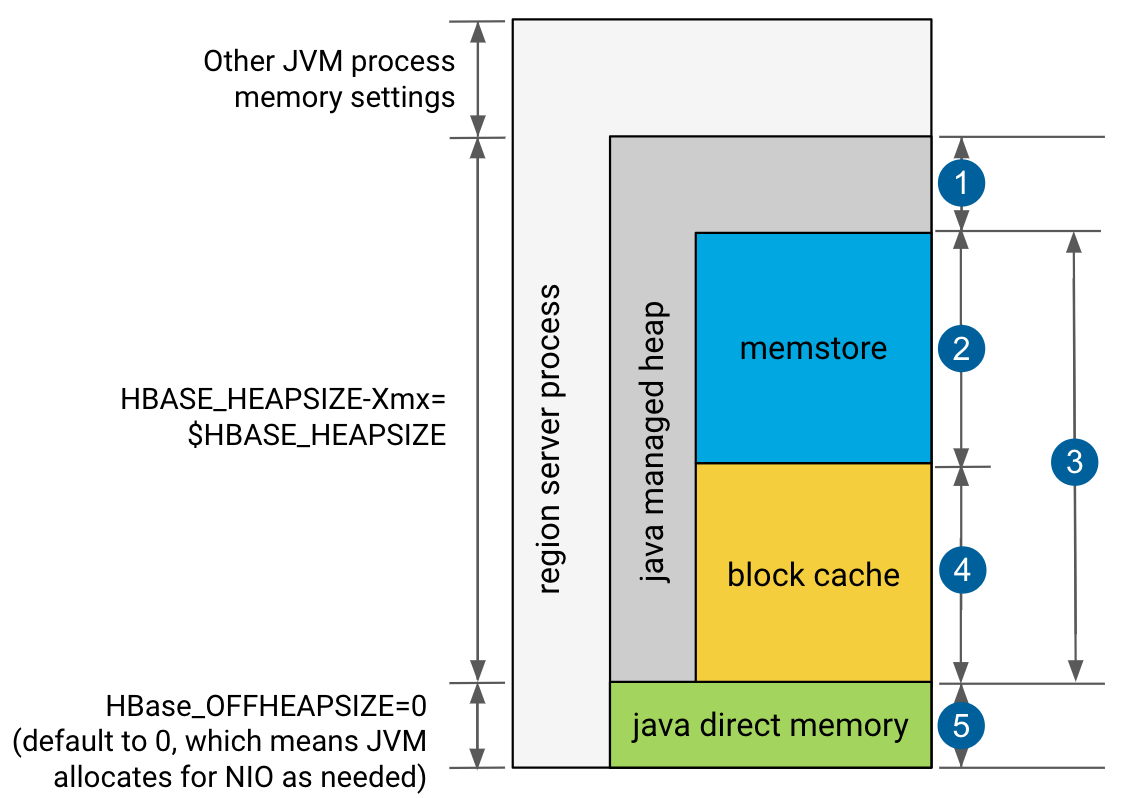
- 20% minimum reserved for operations and rpc call queues
- hbase.regionserver.global.memstore.size: default is 0.4, which means 40%
- hbase.regionserver.global.memstore.size + hfile.block.cache.size ≤0.80, which means 80%
- hfile.block.cache.size: default is 0.4, which means 40%
- slack reserved for HDFS SCR/NIO: number of open HFiles * hbase.dfs.client.read.shortcircuit.buffer.size, where hbase.dfs.client.read.shortcircuit.buffer.size is set to 128k.
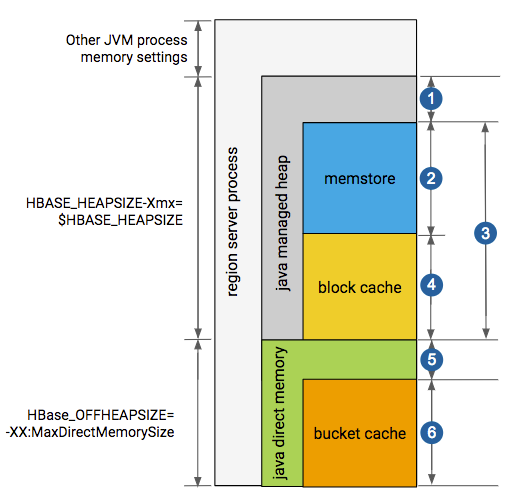
- 20% minimum reserved for operations and rpc call queues
- hbase.regionserver.global.memstore.size: default is 0.4, which means 40%
- hbase.regionserver.global.memstore.size + hfile.block.cache.size ≤0.80, which means 80%
- hfile.block.cache.size: default is 0.4 which means 40%
- slack reserved for HDFS SCR/NIO: number of open HFiles * hbase.dfs.client.read.shortcircuit.buffer.size, where hbase.dfs.client.read.shortcircuit.buffer.size is set to 128k.
- hbase.bucketcache.size: default is 0.0
If hbase.bucketcache.size is float <1, it represents the percentage of total heap size.
If hbase.bucketcache.size is ≥1, it represents the absolute value in MB. It must be < HBASE_OFFHEAPSIZE
Configuring the BucketCache IO Engine
Use the hbase.bucketcache.ioengine parameter to define where to store the content of the BucketCache. Its value can be offheap, file:PATH, mmap:PATH, pmem:PATH , or it can be empty. By default it is empty which means that BucketCache is disabled.
When hbase.bucketcache.ioengine is set to offheap, the content of the BucketCache is stored off-heap as it is presented on the Default LRUCache, L1 only block cache hbase.bucketcache.ioengine=offheap image.
When hbase.bucketcache.ioengine is set to file:PATH, the BucketCache uses file caching.
When hbase.bucketcache.ioengine is set to mmap:PATH, the content of the BucketCache is stored and accessed through memory mapping to a file under the specified path.
When hbase.bucketcache.ioengine is set to pmem:PATH, BucketCache uses direct memory access to and from a file on the specified path. The specified path must be under a volume that is mounted on a persistent memory device that supports direct access to its own address space. An example of such persistent memory device is the Intel® Optane™ DC Persistent Memory, when it is mounted in Direct Mode.
The advantage of the pmem engine over the mmap engine is that it supports large cache size. That is because pmem allows for reads straight from the device address, which means in this mode no copy is created on DRAM. Therefore, swapping due to DRAM free memory exhaustion is not an issue when large cache size is specified. With devices currently available, the bucket cache size can be set to the order of hundreds of GBs or even a few TBs.
When bucket cache size is set to larger than 256GB, the OS limit must be increased, which can be configured by the max_map_count property. Make sure you have an extra 10% for other processes on the host that require the use of memory mapping. This additional overhead depends on the load of processes running on the RS hosts. To calculate the OS limit divide the block cache size in GB by 4 MB and then multiply it by 1.1: (block cache size in GB / 4 MB) * 1.1.
- In Cloudera Manager select the HBase service and go to Configuration.
- Search for BucketCache IOEngine and set it to the required value.
- In Cloudera Manager select the HBase service and go to Configuration.
- Search for RegionServer Advanced Configuration Snippet (Safety Valve) for hbase-site.xml.
- Click the plus icon.
- Set the required value:
- Name: Add hbase.bucketcache.ioengine.
- Value: Add either mmap:PATH: or pmem:PATH.
Configuring the Off-heap BucketCache Using Cloudera Manager
- Go to the HBase service.
- Click the Configuration tab.
- Select the RegionServer scope and do the following:
- Set BucketCache IOEngine to offheap.
- Update the value of BucketCache Size according to the required BucketCache size.
- In the RegionServer Environment Advanced Configuration Snippet (Safety Valve), edit the following parameters:
- HBASE_OFFHEAPSIZE: Set it to a value (such as 5G) that accommodates your required L2 cache size, in addition to space reserved for cache management.
- HBASE_OPTS: Add the JVM option --XX:MaxDirectMemorySize=<size>G, replacing <size> with a value not smaller than the aggregated heap size expressed as a number of gigabytes + the off-heap BucketCache, expressed as a number of gigabytes + around 1GB used for HDFS short circuit read. For example, if the off-heap BucketCache is 16GB and the heap size is 15GB, the total value of MaxDirectMemorySize could be 32: -XX:MaxDirectMamorySize=32G.
- Optionally, when combined BucketCache is in use, you can decrease the heap size ratio allocated to the L1 BlockCache, and increase the Memstore size.
The on-heap BlockCache only stores indexes and Bloom filters, the actual data resides in the off-heap BucketCache. A larger Memstore is able to accommodate more write request before flushing them to disks.
- Decrease HFile Block Cache Size to 0.3 or 0.2.
- Increase Maximum Size of All Memstores in RegionServer to 0.5 or 0.6 respectively.
- Enter a Reason for change, and then click Save Changes to commit the changes.
- Restart or rolling restart your RegionServers for the changes to take effect.
Configuring the Off-heap BucketCache Using the Command Line
- Verify the RegionServer's off-heap size, and if necessary, tune it by editing the hbase-env.sh file and adding a line like the following:
HBASE_OFFHEAPSIZE=5G
Set it to a value that accommodates your BucketCache size + the additional space required for DFSClient short circuit reads (default is 1 GB). For example, if the BucketCache size is 8 GB, set HBASE_OFFHEAPSIZE=9G.
- Configure the MaxDirectMemorySize option for the RegionServers JVMS. This can be done adding the following line in hbase-env.sh:
HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:MaxDirectMemorySize=<size>GReplace <size> with the same value set for HBASE_OFFHEAPSIZE.
- Next, in the hbase-site.xml files on the RegionServers, configure the properties in BucketCache Configuration Properties as appropriate, using the example below as a model.
<property> <name>hbase.bucketcache.combinedcache.enabled</name> <value>true</value> </property> <property> <name>hbase.bucketcache.ioengine</name> <value>offheap</value> </property> <property> <name>hbase.bucketcache.size</name> <value>8388608</value> </property> <property> <name>hfile.block.cache.size</name> <value>0.2</value> </property> <property> <name>hbase.regionserver.global.memstore.size</name> <value>0.6</value> </property>
- Restart each RegionServer for the changes to take effect.
Monitoring the BlockCache
Cloudera Manager provides metrics to monitor the performance of the BlockCache, to assist you in tuning your configuration. See HBase Metrics.
You can view further detail and graphs using the RegionServer UI. To access the RegionServer UI in Cloudera Manager, go to the Cloudera Manager page for the host, click the RegionServer process, and click HBase RegionServer Web UI.
If you do not use Cloudera Manager, access the BlockCache reports at http://regionServer_host:22102/rs-status#memoryStats, replacing regionServer_host with the hostname or IP address of your RegionServer.
