Troubleshooting Apache Hive in CDH
This section provides guidance on problems you may encounter while installing, upgrading, or running Hive.
With Hive, the most common troubleshooting aspects involve performance issues and managing disk space. Because Hive uses an underlying compute mechanism such as MapReduce or Spark, sometimes troubleshooting requires diagnosing and changing configuration in those lower layers. In addition, problems can also occur if the metastore metadata gets out of synchronization. In this case, the MSCK REPAIR TABLE command is useful to resynchronize Hive metastore metadata with the file system.
Continue reading:
Troubleshooting
HiveServer2 Service Crashes
If the HS2 service crashes frequently, confirm that the problem relates to HS2 heap exhaustion by inspecting the HS2 instance stdout log.
- In Cloudera Manager, from the home page, go to .
- In the Instances page, click the link of the HS2 node that is down:
HiveServer2 Link on the Cloudera Manager Instances Page
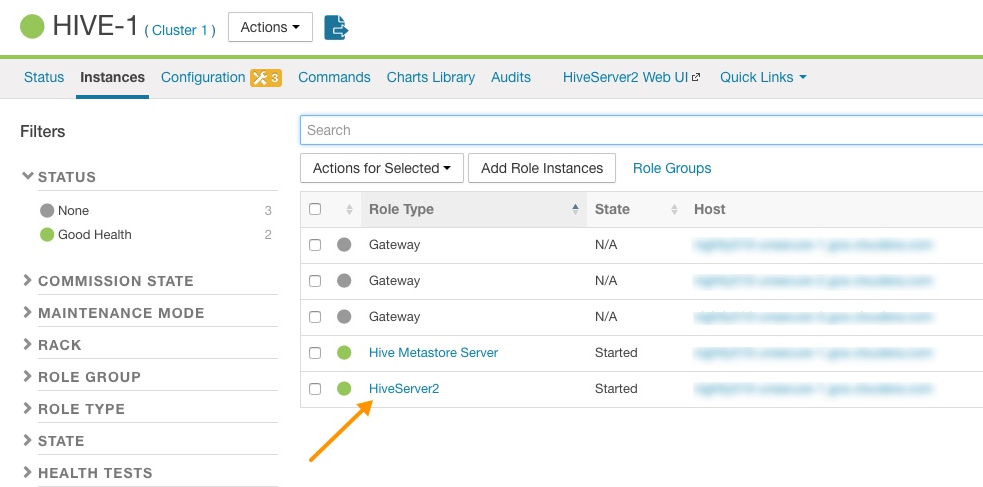
- On the HiveServer2 page, click Processes.
- On the HiveServer2 Processes page, scroll down to the Recent Log Entries and click the link to the Stdout log.
Link to the Stdout Log on the Cloudera Manager Processes Page
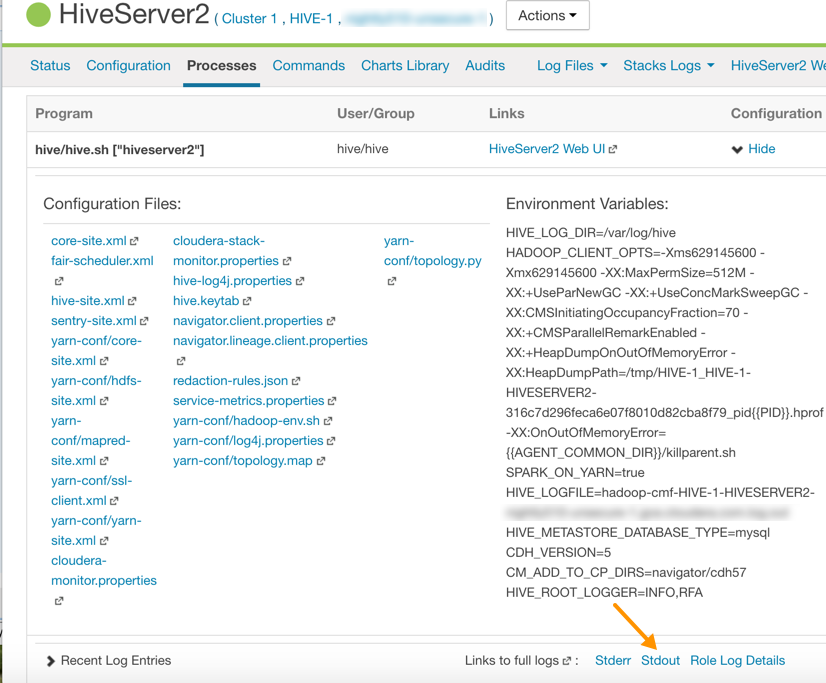
- In the stdout.log, look for the following error:
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="/usr/lib64/cmf/service/common/killparent.sh" # Executing /bin/sh -c "/usr/lib64/cmf/service/common/killparent.sh"
Video: Troubleshooting HiveServer2 Service Crashes
For more information about configuring Java heap size for HiveServer2, see the following video:
After you start the video, click YouTube in the lower right corner of the player window to watch it on YouTube where you can resize it for clearer viewing.
Best Practices for Using MSCK REPAIR TABLE
Hive stores a list of partitions for each table in its metastore. The MSCK REPAIR TABLE command was designed to bulk-add partitions that already exist on the filesystem but are not present in the metastore. It can be useful if you lose the data in your Hive metastore or if you are working in a cloud environment without a persistent metastore. See Tuning Apache Hive Performance on the Amazon S3 Filesystem in CDH or Configuring ADLS Gen1 Connectivity for more information.
Example: How MSCK REPAIR TABLE Works
The following example illustrates how MSCK REPAIR TABLE works.
-
Create directories and subdirectories on HDFS for the Hive table employee and its department partitions:
$ sudo -u hive hdfs dfs -mkdir -p /user/hive/dataload/employee/dept=sales $ sudo -u hive hdfs dfs -mkdir -p /user/hive/dataload/employee/dept=service $ sudo -u hive hdfs dfs -mkdir -p /user/hive/dataload/employee/dept=finance -
List the directories and subdirectories on HDFS:
$ sudo -u hdfs hadoop fs -ls -R /user/hive/dataload drwxr-xr-x - hive hive 0 2017-06-16 17:49 /user/hive/dataload/employee drwxr-xr-x - hive hive 0 2017-06-16 17:49 /user/hive/dataload/employee/dept=finance drwxr-xr-x - hive hive 0 2017-06-16 17:47 /user/hive/dataload/employee/dept=sales drwxr-xr-x - hive hive 0 2017-06-16 17:48 /user/hive/dataload/employee/dept=service -
Use Beeline to create the employee table partitioned by dept:
CREATE EXTERNAL TABLE employee ( eid int, name string, position string ) PARTITIONED BY (dept string) LOCATION ‘/user/hive/dataload/employee’ ; -
Still in Beeline, use the SHOW PARTITIONS command on the employee table that you just created:
SHOW PARTITIONS employee;This command shows none of the partition directories you created in HDFS because the information about these partition directories have not been added to the Hive metastore. Here is the output of SHOW PARTITIONS on the employee table:
+------------+--+ | partition | +------------+--+ +------------+--+ No rows selected (0.118 seconds) -
Use MSCK REPAIR TABLE to synchronize the employee table with the metastore:
MSCK REPAIR TABLE employee; -
Then run the SHOW PARTITIONS command again:
SHOW PARTITIONS employee;Now this command returns the partitions you created on the HDFS filesystem because the metadata has been added to the Hive metastore:
+---------------+--+ | partition | +---------------+--+ | dept=finance | | dept=sales | | dept=service | +---------------+--+ 3 rows selected (0.089 seconds)
Guidelines for Using the MSCK REPAIR TABLE Command
Here are some guidelines for using the MSCK REPAIR TABLE command:
- Running MSCK REPAIR TABLE is very expensive. It consumes a large portion of system resources. Only use it to repair metadata when the metastore has gotten out of sync with the file system. For example, if you transfer data from one HDFS system to another, use MSCK REPAIR TABLE to make the Hive metastore aware of the partitions on the new HDFS. For routine partition creation, use the ALTER TABLE ... ADD PARTITION statement.
- A good use of MSCK REPAIR TABLE is to repair metastore metadata after you move your data files to cloud storage, such as Amazon S3. If you are using this scenario, see Tuning Hive MSCK (Metastore Check) Performance on S3 for information about tuning MSCK REPAIR TABLE command performance in this scenario.
- Run MSCK REPAIR TABLE as a top-level statement only. Do not run it from inside objects such as routines, compound blocks, or prepared statements.
