You can use the registered Kafka source to create a Kafka Virtual Table Source. You
need to add a Kafka topic and choose to use Schema Registry to have a Kafka source for your
SQL Stream job.
Make sure that you have created a Kafka topic.
Make sure that you have the right permissions set in Ranger.
Make sure there is generated data in the Kafka topic.
If you are using Schema Registry, you have added a schema.
Go to your cluster in Cloudera Manager.
Click on SQL Stream Builder from the list of
Services.
Click on SQLStreamBuilder Console.
The Streaming SQL Console opens up in a new window.
Select Console from the left hand menu.
Select the Virtual Tables tab.
Select the Virtual Table Source sub-tab.
Select Add Source > Apache Kafka.
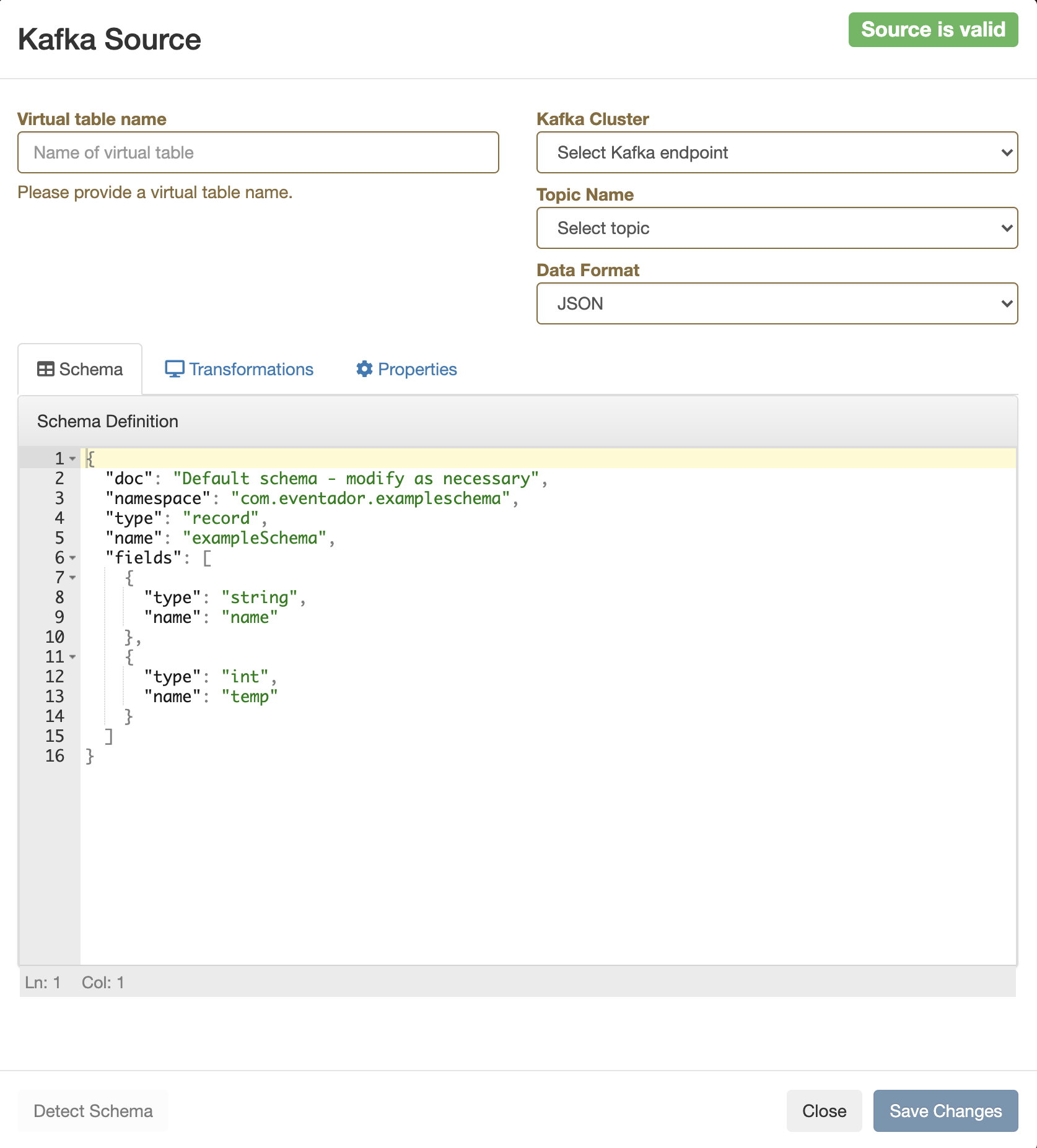
The Kafka Source window appears.
Provide a name to the Virtual Table.
Select a registered Kafka data source.
Select a Kafka topic from the list.
Select the Data Format.
You can select JSON as data format.
You can select Avro as data format.
Determine the schema for the Virtual Table Source.
Add a customized schema to the Schema Definition field.
Click Detect Schema to read a sample of the messages and automatically
infer the schema.
Click Detect Schema if you are using Schema Registry.
Customize your Virtual Table Source.
Configure an Input Transform, add the code using the Transformations
tab.
Configure any Kafka properties required using the Properties tab.
Select Save Changes.
The Kafka Virtual Table Source is ready for queries to be
run. You can check its configuration by a DESC <tablename> command
in the Compose tab, and selecting Execute. You can use the Kafka
sink for your SQL job by declaring in with the FORM clause in the SQL
statement.