
Using Virtual Tables
Virtual Tables are the interface for inputs (sources) and outputs (sinks) in SQL Stream Builder. Sources and sinks are configured separately, and may require a data source to be configured before they can be selectable. Data is continuously processed via the SQL Stream Builder SQL job from the source and the results of the query are continuously processed to the sink.
Virtual Table Sources
A Virtual Table Source is a logical definition of the data source that includes the location and connection parameters, a schema, an optional Input Transform, and any required, context specific configuration parameters.
FROM clause run in SQL query specifies the Virtual Table Source. If you
are performing a join, then each table specified in the SQL statement must reference a Virtual
Table Source. This can be the same source multiple times, or a
self-join.SELECT lat,lon FROM airplanes -- the name of the virtual table source WHERE icao <> 0;
- Kafka
- In this release of SSB, only Kafka is available as a virtual table source. To use Kafka as a source, you need to create a Kafka topic from which SSB reads the incoming data from.
- Schema
- Schema is defined for a given source when the source is created. When adding a schema you can either paste it to the Schema Definition field or click the Detect schema button to identify the schema used on the generated data. You can use JSON or AVRO as formats. The AVRO format can only be used when using Schema Registry.
- Input Transform
- You can apply input transformations on your data when adding a virtual table source to clean or arrange the data coming from the source using javascript functions.
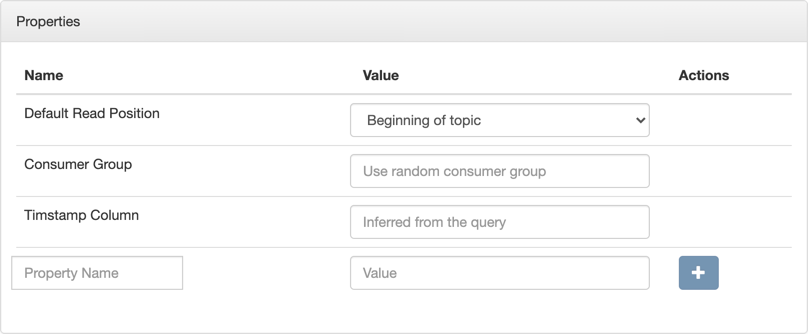
- Properties
- You can specify certain properties to define your source in detail. You can add customized
properties additionally to the default ones. To create properties, you need to give a name to
the property and provide a value for it, then click Actions.
Virtual Table Sinks
When you execute a query, the results go to the Virtual Table Sink that you selected in the SQL window. This allows you to create aggregations, filters, joins, and so on, and then route the results to a sink. The schema for the results is the schema that you created when you ran the query.
Selecting a sink for your SQL job is optional. You can output data to the screen when composing a SQL statement, or when configuring a Materialized View. This way data is not sent to a sink directly. To create a chain of SQL Stream Builder jobs, you can select a source topic from a different SQL job for a sink to process data in pieces.
Sampling the results to your browser allows you to inspect the queried data and iterate on your query. You can sample 100 rows in the Results tab by clicking on the Sample button in the Console. In case you do not add any sink to the SQL job, the results automatically appear in the Results tab.
Based on the type of Virtual Table Sink, you need to configure a data source before creating the sink. You can specify the Virtual Table Sink either before running a SQL job or when running a SQL job. The results from the SQL Stream Builder SQL query are sent to the Virtual Table Sink continuously.
- Webhook sink
- The webhook sink is useful for sending data to HTTP endpoints through POST or PUT.
- Kafka sink
- Kafka sinks are an output virtual table to send the data resulting from the query to. The data of a Kafka sink is in JSON format.
- Schema
-
For sinks, the schema is defined by the table structure in the SQL statement, both for column names and datatypes. SSB supports aliases for column names like
SELECT bar AS foo FROM bazas well asCAST(value AS type)for type conversions. SSB supports meta commands likeshow tablesanddescribe <table>that make it easier to visualize the schema used on the data.
