
Configuring Kafka tables
The user defined Kafka table can be configured based on the schema, event time, input transformations and other Kafka specific properties.
Schema tab
Schema is defined for a given Kafka source when the source is created. The data contained in the Kafka topic can either be in JSON or AVRO format.
When specifying a schema you can either paste it to the Schema Definition field or click the Detect schema button to identify the schema used on the generated data. The Detect Schema functionality is only available for JSON data.
Event Time tab
- Input Timestamp Column: name of the timestamp column in the Kafka topic from where the watermarks are mapped to the Event Time Column of the Kafka table
- Event Time Column: default or custom name of the resulting timestamp column where the watermarks are going to be mapped in the created Kafka table
- Watermark seconds: number of seconds used in the watermark strategy. The watermark is defined by the current event timestamp minus this value.
- Using the default Kafka Timestamps setting
- Using the default Kafka Timestamps setting, but providing custom name for the Event Time Column
- Not using the default Kafka Timestamps setting, and providing all of the Kafka timestamp information manually
- Not using watermark strategy for the Kafka table
Using the default Kafka Timestamp setting
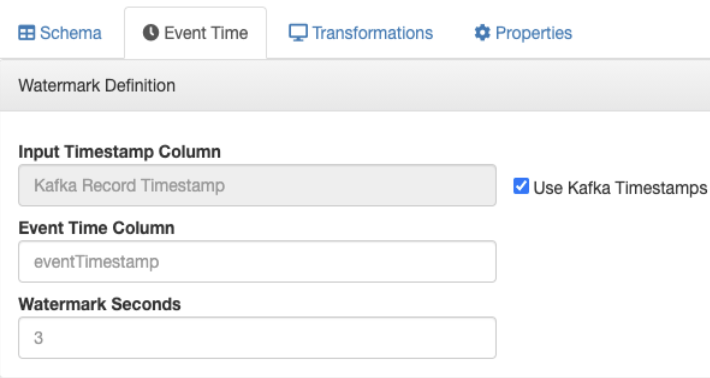
After saving your changes, you can view the created DDL syntax for the Table on the right side under the DDL tab. You can review the generated watermark strategy for your table that was set on the Watermark Definition tab.
'eventTimestamp' TIMESTAMPS(3) METADATA FROM 'timestamp', WATERMARK FOR 'eventTimestamp' AS 'eventTimestamp' - INTERVAL '3' SECOND
Using the default Kafka Timestamp setting with custom Event Time Column name
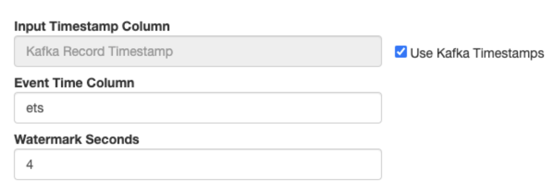
- The column type must be "long".
- The format must be in epoch (in milliseconds since January 1, 1970).
'ets' TIMESTAMP(3) METADATA FROM 'timestamp', WATERMARK FOR 'ets' - INTERVAL '4' SECOND
Manually providing the Kafka timestamp information
When you want to manually configure the watermark strategy of the Kafka table, you can provide the timestamp column name from the Kafka source, and add a custom column name for the resulting Kafka table. Make sure that you provide the correct column name for the Input Timestamp Column that exactly matches the column name in the Kafka source data.
- Input Timestamp Column: name of the timestamp field in the Kafka source
- Event Time Column: predefined 'eventTimestamp' name or custome column name of the timestamp field in the created Kafka table
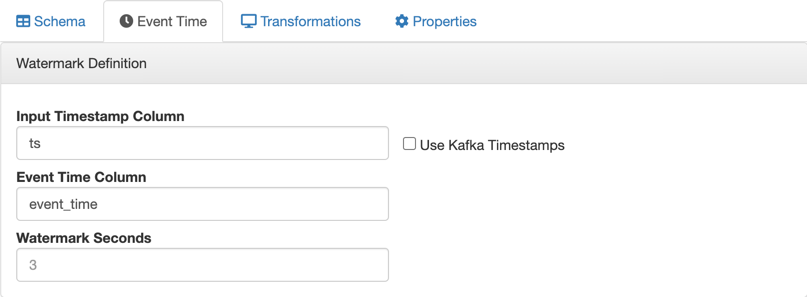
- The column type must be "long".
- The format must be in epoch (in milliseconds since January 1, 1970).
Not using watermark strategy for Kafka table

Input Transform tab
You can apply input transformations on your data when adding a Kafka table as a source to your queries. Input transformations can be used to clean or arrange the incoming data from the source using javascript functions.
For more information about Input Transform, see the Creating input transformations document.
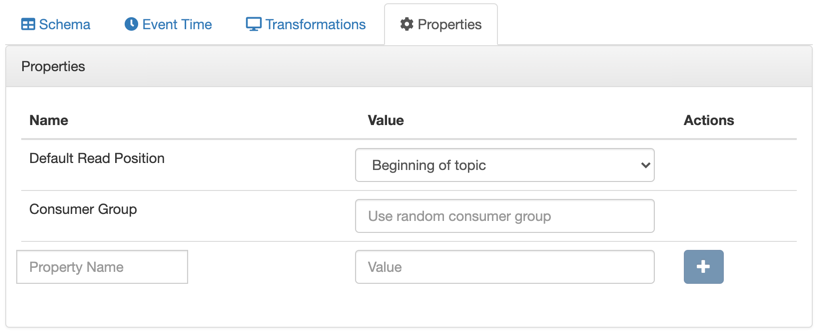
Properties tab
Assigning Kafka keys in streaming queries
Based on the Sticky Partitioning strategy of Kafka, when null keyed events are sent to a topic, they are randomly distributed in smaller batches within the partitions. As the results of the SQL Stream queries by default do not include a key, when written to a Kafka table, the Sticky Partitioning strategy is used. In many cases, it is useful to have more fine-grained control over how events are distributed within the partitions. You can achieve this in SSB by configuring a custom key based on your specific workload.
SELECT sensor_name AS _eventKey --sensor_name becomes the key in the output kafka topic FROM sensors WHERE eventTimestamp > current_timestamp;
To configure keys in DDL-defined tables (those that are configured using the Templates), refer to the official Flink Kafka SQL Connector documentation for more information (specifically the key.format and key.fields options).
