Getting started with Schema Registry
Get started with Schema Registry in Cloudera Streaming Community Edition.
Schema Registry provides a shared repository of schemas that allows applications to flexibly interact with each other. Applications frequently need a way to share metadata across data format, schema, and semantics. Schema Registry addresses these challenges by evolving schemas such that a producer and consumer can understand different versions of the schemas but still read all information shared between both versions and safely ignore the rest.
The following sections teach you how you can:
- Create a schema.
- Evolve a schema.
- Delete a schema.
- Integrate your own Java Kafka client with Schema Registry.
Creating a schema
Learn how to create a schema in Schema Registry using the Schema Registry UI.
Evolving a schema
Learn how to evolve a schema in Schema Registry using the Schema Registry UI.
You evolve a schema when you create a new version of it. Schema Registry tracks the changes made to your schema, and stores each set of changes in a separate version of the schema. When multiple versions exist, you can select which version you want to use. Ensure that you understand compatibility policies, as they determine how you can evolve your schemas.
- Click the
 icon to open the Edit Version
dialog
icon to open the Edit Version
dialog
Deleting a schema
Learn how to delete a schema from Schema Registry with the Swagger UI or curl.
Schemas can be deleted if you no longer need them. However, unlike schema creation and
evolution, schema deletion can not be done using the Schema Registry UI. Instead, you must
use the Schema Registry API. The following provides instructions on how to delete a schema
using the Swagger UI or curl.
Steps
- Go to
http://localhost:7788/swagger - Click Schema.
- Click DELETE /api/v1/schemaregistry/schemas/{name}.
- Click Try it out.
- Enter the name of the Schema that you want to delete in the Name field.
- Click Execute.
- Open a new terminal session.
- Run the following
command:
Replace [***SCHEMA NAME***] with the name of the schema that you want to deletecurl -X DELETE "http://localhost:7788/api/v1/schemaregistry/schemas/[***SCHEMA NAME***]" -H "accept: application/json"
Integrating Schema Registry with a Kafka Java client
Learn how you can integrate existing Kafka Java clients with Schema Registry.
The following steps walk you through how you can integrate an existing Java Kafka client with Schema Registry. Additionally, you will learn about the KafkaAvroSerializer and KafkaAvroDeserializer. These are the Cloudera recommended converters that you should use when integrating clients with Schema Registry. Lastly, you will also learn how you can view the Avro data produced into a topic using Streams Messaging Manager.
-
View data in Streams Messaging Manager.
-
Click
 (Topics) in the navigation sidebar.
(Topics) in the navigation sidebar.
-
Find the topic you have been using and click
 next to the name of a topic.
next to the name of a topic.
-
Go to Data Explorer.
The messages the producer is producing into the topic should be visible on this page. However, the contents of the messages will not be readable.
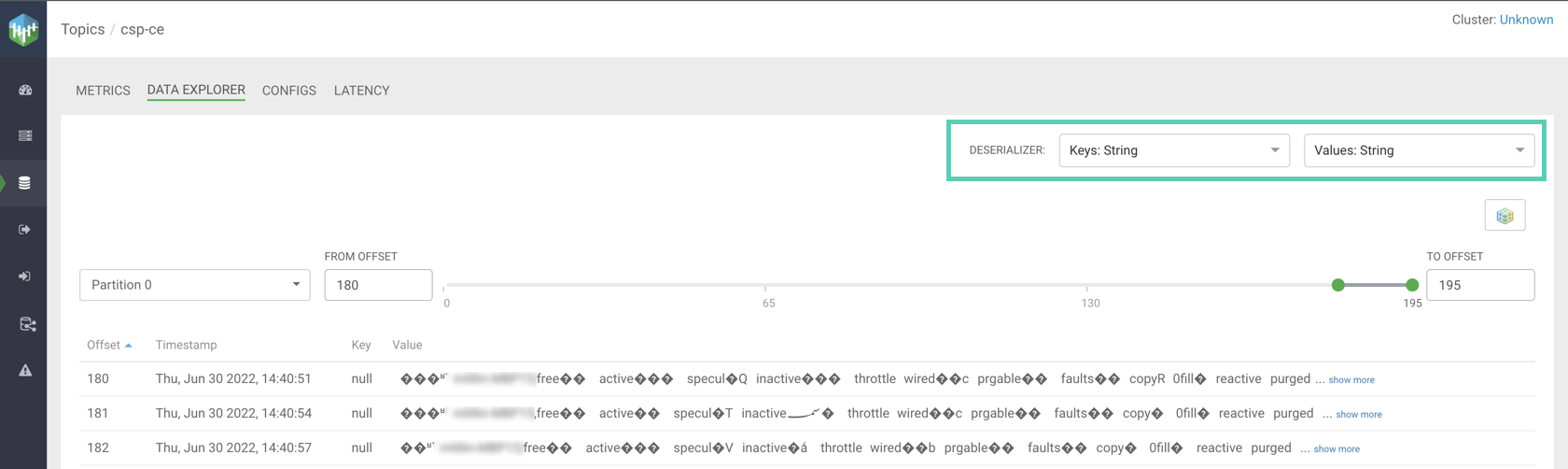
This is because your producer is producing binary data. However because Streams Messaging Manager integrates with Schema Registry, it is capable of decoding the binary data using the schema registered for the topic in Schema Registry. This is done by selecting Avro for the key and/or value deserializer.
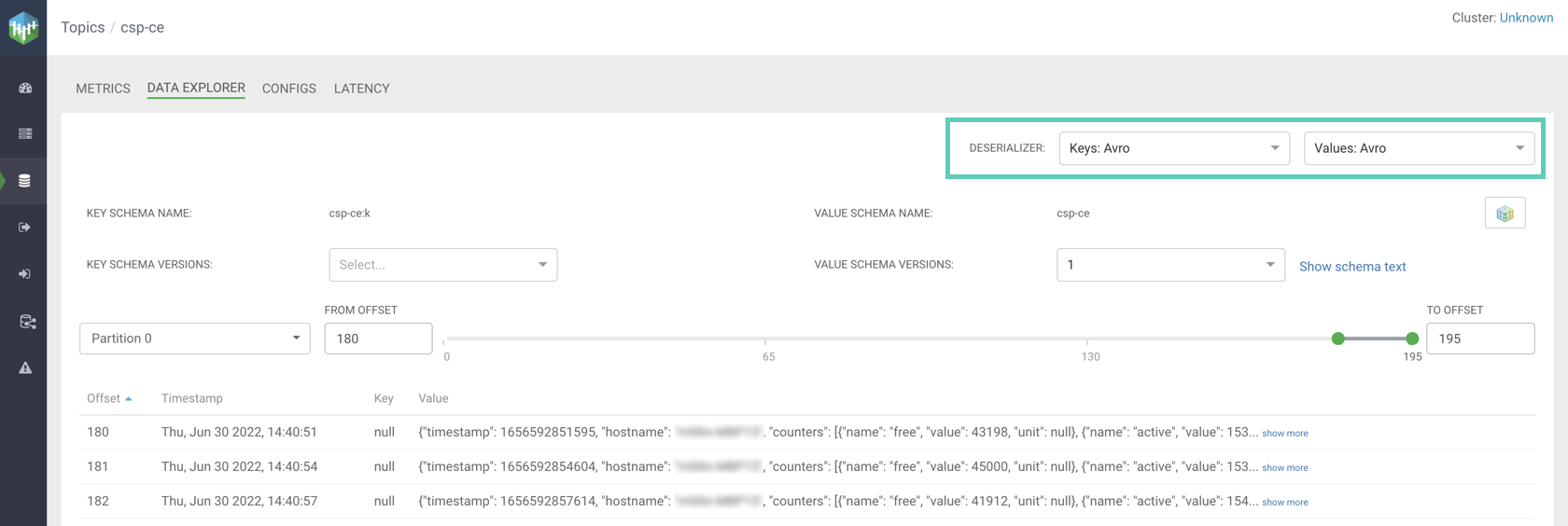
-
Click