
Kafka Architecture
Learn about Kafka's architecture and how it compares to an ideal publish-subscribe system.
The ideal publish-subscribe system is straightforward: Publisher A’s messages must make their way to Subscriber A, Publisher B’s messages must make their way to Subscriber B, and so on.
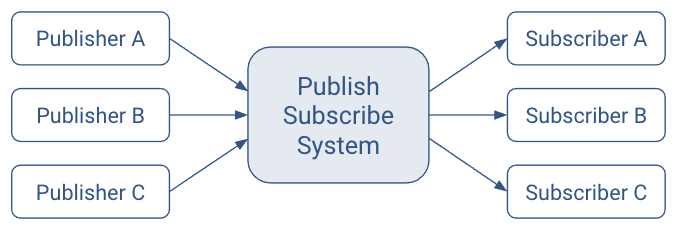
An ideal system has the benefit of:
- Unlimited Lookback. A new Subscriber A1 can read Publisher A’s stream at any point in time.
- Message Retention. No messages are lost.
- Unlimited Storage. The publish-subscribe system has unlimited storage of messages.
- No Downtime. The publish-subscribe system is never down.
- Unlimited Scaling. The publish-subscribe system can handle any number of publishers and/or subscribers with constant message delivery latency.
Kafka's architecture however deviates from this ideal system. Some of the key differences are:
- Messaging is implemented on top of a replicated, distributed commit log.
- The client has more functionality and, therefore, more responsibility.
- Messaging is optimized for batches instead of individual messages.
- Messages are retained even after they are consumed; they can be consumed again.
The results of these design decisions are:
- Extreme horizontal scalability
- Very high throughput
- High availability
- Different semantics and message delivery guarantees
Kafka Terminology
Kafka uses its own terminology when it comes to its basic building blocks and key concepts. The usage of these terms might vary from other technologies. The following provides a list and definition of the most important concepts of Kafka:
- Broker
- A broker is a server that stores messages sent to the topics and serves consumer requests.
- Topic
-
A topic is a queue of messages written by one or more producers and read by one or more consumers.
- Producer
-
A producer is an external process that sends records to a Kafka topic.
- Consumer
-
A consumer is an external process that receives topic streams from a Kafka cluster.
- Client
-
Client is a term used to refer to either producers and consumers.
- Record
-
A record is a publish-subscribe message. A record consists of a key/value pair and metadata including a timestamp.
- Partition
-
Kafka divides records into partitions. Partitions can be thought of as a subset of all the records for a topic.
Continue reading to learn more about each key concept.
